



Алексей Лобанов
Энциклопедия финансового риск-менеджмента
1.22. Важнейшие виды распределений случайных величин
1.22.1. Биномиальное распределение
Дискретная случайная величина ξ имеет биномиальное распределение (binomial distribution) B(n, р), если она принимает значения: 0, 1, 2, …, n, причем
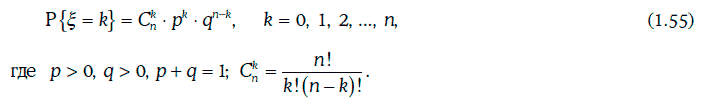
Свойства биноминального распределения

Пример 1.52. Рассмотрим портфель из 20 облигаций, выпущенных различными эмитентами с одним и тем же кредитным рейтингом. Предположим, что дефолты по облигациям независимы, а вероятность дефолта по любой облигации в течение одного года равна 10 %.
Обозначим через ξ число дефолтов по данному портфелю в течение одного года. Случайная величина ξ имеет биномиальное распределение B(20, 0,1), следовательно, ожидаемое число дефолтов по портфелю облигаций в течение одного года составит:
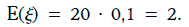
Вероятность того, что в течение года произойдет два дефолта, находится следующим образом:
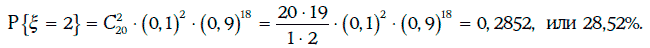
Вероятность, что в течение года произойдет 5 дефолтов, составит величину:
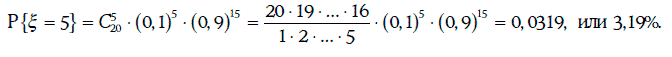
1.22.2. Распределение Пуассона
Случайная величина ξ, принимающая значения 0, 1, 2, …, k, …, имеет распределение Пуассона (Poisson's distribution) с параметром λ > 0, если

Свойства распределения Пуассона

Пример 1.53. Число дефолтов по портфелю облигаций в течение одного года имеет распределение Пуассона. Ожидаемое число дефолтов равно 8.
Вероятность того, что в течение года произойдет ровно два дефолта, можно найти по следующей формуле:
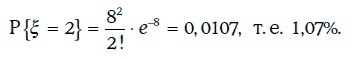
1.22.3. Нормальное распределение
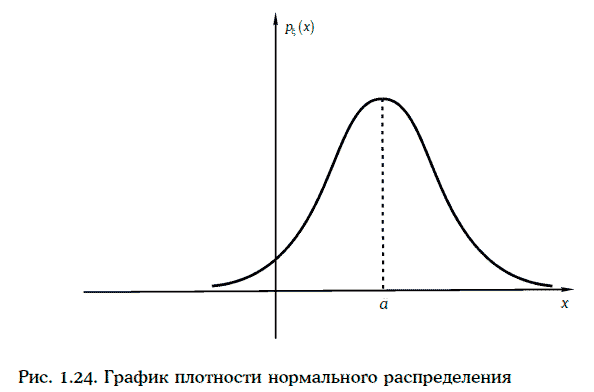
Говорят, что случайная величина ξ распределена нормально (normal distribution), если ее плотность распределения вероятностей имеет вид:

График плотности нормального распределения приведен на рис. 1.24.
Основные свойства нормального распределения
1. Если случайная величина ξ распределена нормально с плотностью
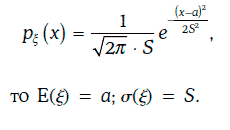
2. Плотность нормально распределенной случайной величины симметрична относительно математического ожидания этой случайной величины, т. е. асимметрия a(ξ) = 0.
В частности,
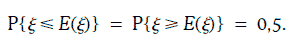
Эксцесс нормального распределения всегда равен 3.
3. Вероятность того, что нормально распределенная случайная величина будет отличаться от своего ожидаемого значения на величину, не превышающую одного, двух или трех ее стандартных отклонений, равна 68,3, 95,5 и 99,75 % соответственно.
Пример 1.54. Инвестор считает, что реализуемая доходность его портфеля облигаций за 6 месяцев имеет нормальное распределение с математическим ожиданием 7 % и стандартным отклонением 4 %.
Вероятность того, что реализуемая доходность окажется:
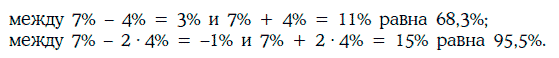
4. Если случайная величина ξ распределена нормально с параметрами (a, S), то случайная величина
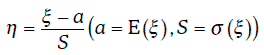
распределена нормально с параметрами (0, 1), т. е. имеет стандартное нормальное распределение.
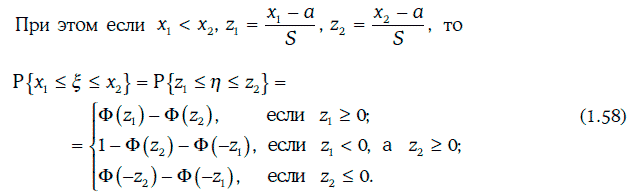

Пример 1.55. Менеджер считает, что стоимость управляемого им портфеля облигаций распределена нормально с математическим ожиданием 10 млн долл. и стандартным отклонением 2 млн долл. Его интересует, какова вероятность, что стоимость портфеля окажется между 6 млн и 11 млн долл.
В данном случае

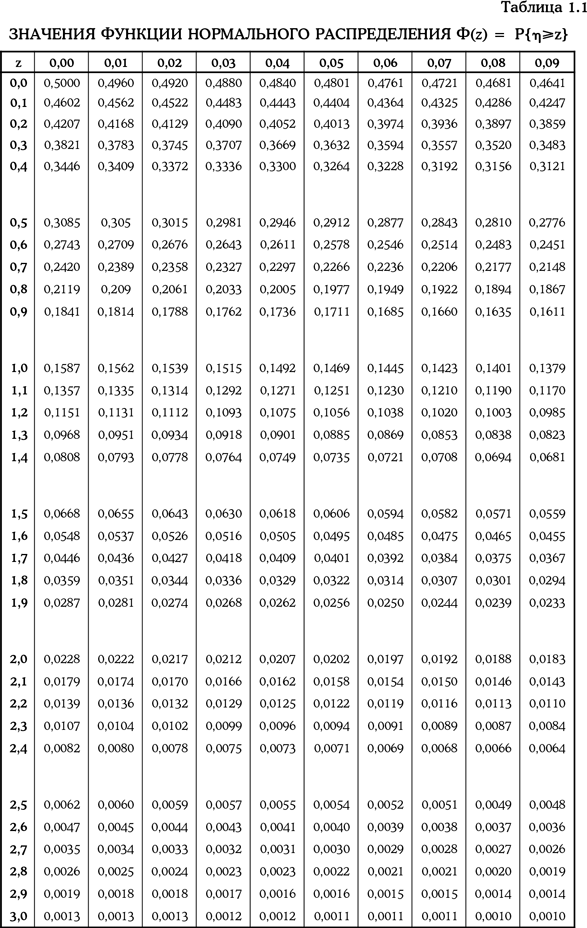
Пример 1.56. Предположим, что в условиях примера 1.55 менеджер хочет найти доверительный интервал для стоимости управляемого им портфеля с надежностью 95 %. Иными словами, требуется найти интервал
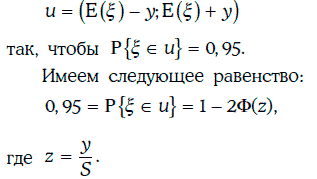
Тогда Ф(z) = 0,025. С помощью табл. 1.1 найдем значение z = 1,96. Значит, y = z · S = 1,96 · 2 млн долл. = 3,92 млн долл.
Искомый доверительный интервал: (6,08 млн долл.; 13,92 млн долл.).


1.22.4. Логарифмически нормальное (логнормальное) распределение
Говорят, что положительная случайная величина ξ распределена логнормально (lognormal distribution), если ln ξ имеет нормальное распределение вероятностей. Таким образом, плотность логнормального распределения имеет вид:
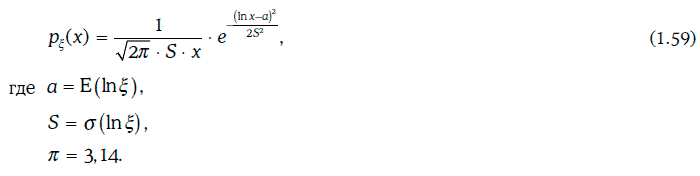
График плотности логнормального распределения приведен на рис. 1.25.
Свойства логнормального распределения
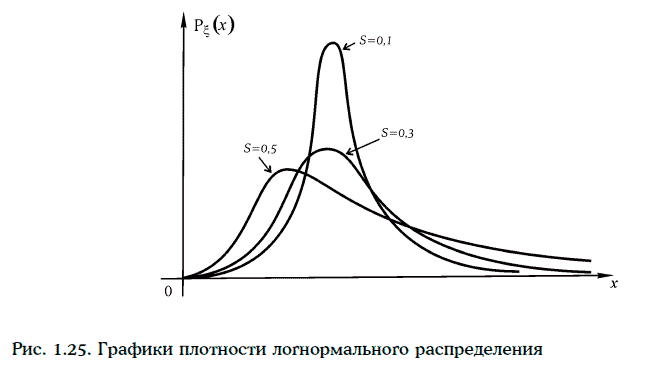
1. Логнормальное распределение обладает правосторонней асимметрией (positively skewed), а при малых значениях S = σ(lnξ) близко к нормальному распределению.
2. Если случайная величина ξ имеет логнормальное распределение с параметрами а и S, то
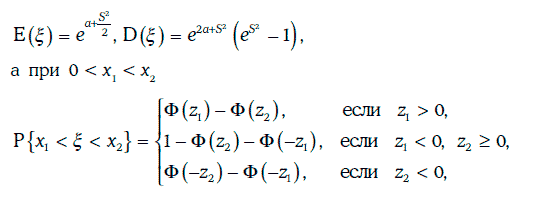

Пример 1.57. Будем считать, что доходность 10-летних облигаций с нулевыми купонами имеет логнормальное распределение с параметрами a = -2,70; S = 0,30.
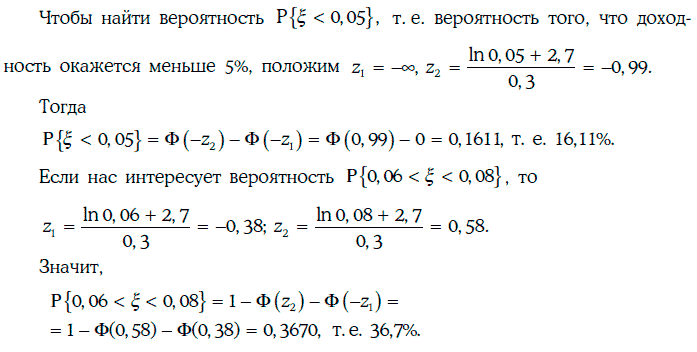
3. Если две случайные величины распределены логнормально, то их произведение также имеет логнормальное распределение.
1.22.5. Распределение х2 (хи-квадрат)
Говорят, что случайная величина z имеет распределение х2 (chi-squared distribution) с n степенями свободы, если она представима в виде суммы n квадратов взаимно независимых величин со стандартными нормальными распределениями.
Свойства распределения X2


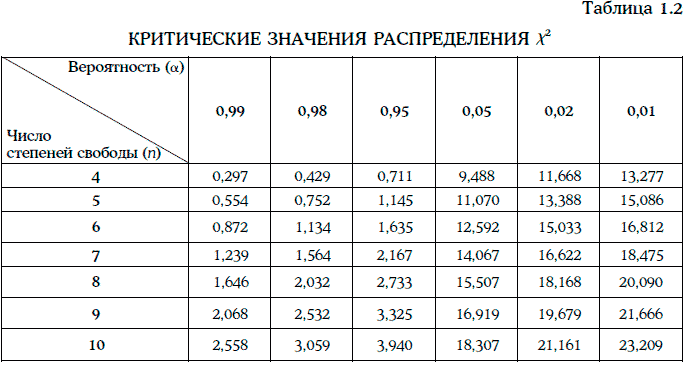
Пример 1.58. Даны 10 дневных наблюдений доходности 30-летних казначейских облигаций с нулевым купоном:
Если допустить, что доходность распределена нормально, то оценки математического ожидания и дисперсии доходности можно найти следующим образом:
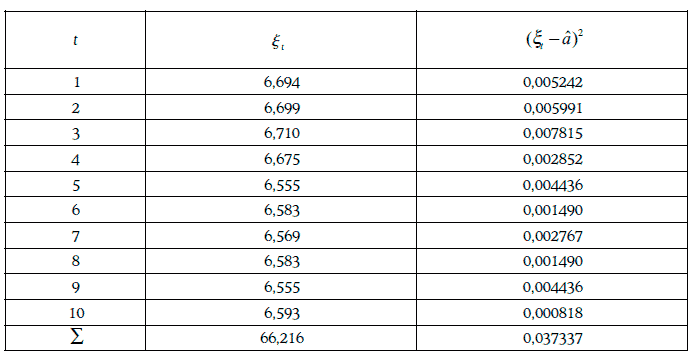
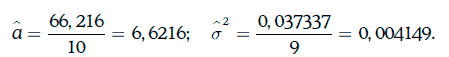
Доверительный интервал для дисперсии доходности с надежностью 96 % можно найти из условия
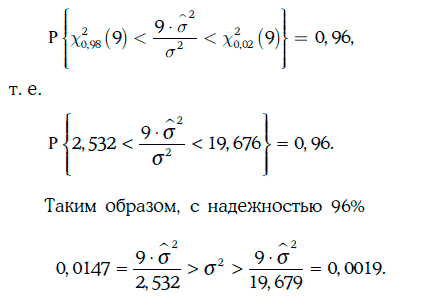
1.22.6. Распределение Стьюдента
Распределение вероятностей случайной величины

называется распределением Стьюдента (Student’s t-distribution) с n степенями свободы, если случайные величины ξ и η независимы, ξ имеет стандартное нормальное распределение, а η – распределение х2 с n степенями свободы.
Свойства распределения Стьюдента
1. Если случайная величина t имеет распределение Стьюдента с n степенями свободы, то
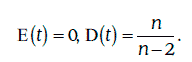
Асимметрия распределения Стьюдента равна 0.
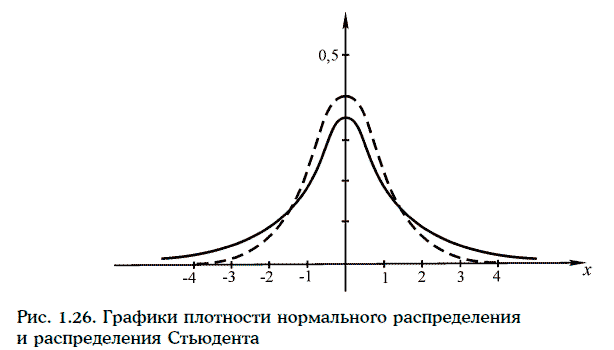
2. При возрастании числа степеней свободы распределение Стьюдента стремится к стандартному нормальному распределению. При этом распределение Стьюдента имеет более тяжелые ветви, чем стандартное нормальное распределение. На рис. 1.26 изображены графики плотности стандартного нормального распределения и распределения Стьюдента с тремя степенями свободы.
3. Критическим значением распределения Стьюдента с и степенями свободы называют число ta(n), удовлетворяющее условию:
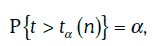
где α – заданная вероятность.
Критические значения распределения Стьюдента указаны в табл. 1.3.
4. Если случайные величины ξ1, ξ2…., ξn взаимно независимы и распределены нормально с параметрами (а, σ), то случайная величина
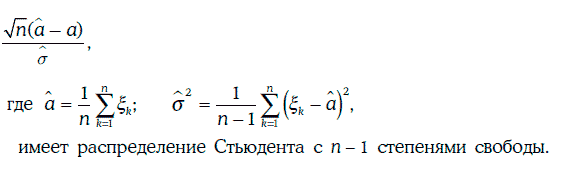
Пример. 1.59. В условиях примера 1.58 найдем доверительный интервал для ожидаемой доходности с надежностью 95 %.
Так как
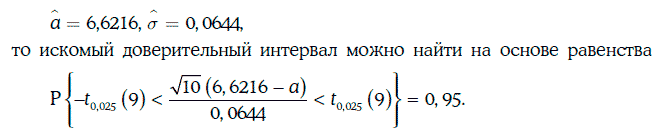
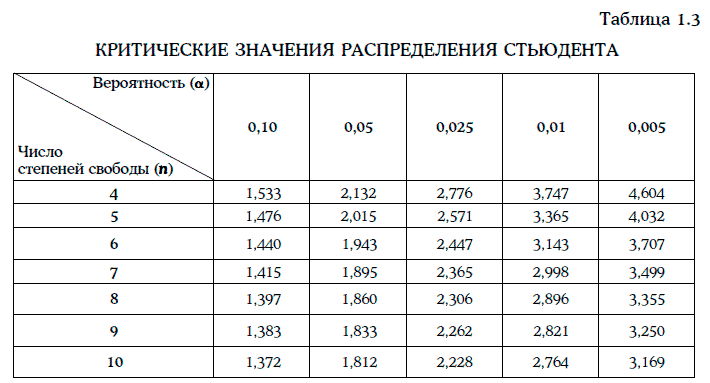
Согласно табл. 1.3, критическое значение распределения Стьюдента t0,025(9) = 2, 262.
Следовательно,
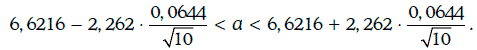
Таким образом, с надежностью 95 % ожидаемая доходность казначейских облигаций находится между 6,57 и 6,67 %.
1.22.7. Гамма-распределение
Плотность гамма-распределения Г(α, γ) имеет следующий вид:
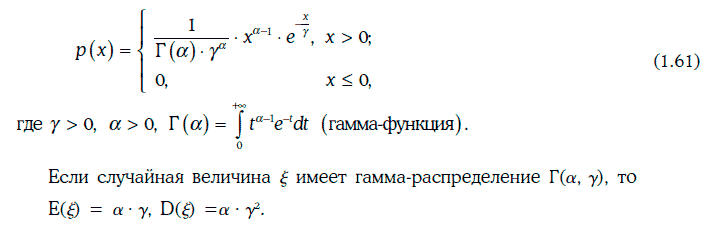
1.22.8. Бета-распределение
Плотность бета-распределения В(α, β) записывается в виде:
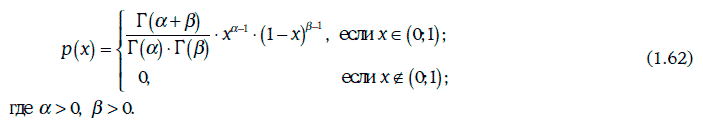
Если случайная величина ξ имеет бета-распределение В(α, β), то
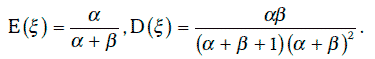
1.22.9. Двумерное нормальное распределение
Плотность двумерного нормального распределения имеет следующий вид:
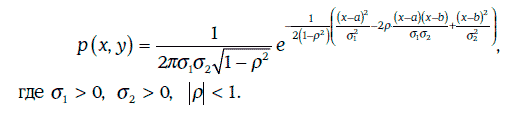
Свойства двумерного нормального распределения

1.23. Расчет волатильности финансовых показателей на основе исторических данных
Волатильность, или изменчивость (volatility), финансовых показателей играет очень важную роль в управлении финансовыми рисками.
Пусть Yt – некоторый финансовый показатель (например, цена или доходность некоторого финансового инструмента), наблюдаемый в день t, t = 0, 1, 2, …, T. Положим
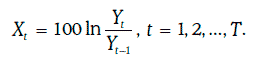
Случайная величина Xt представляет собой натуральный логарифм относительного изменения этого показателя за один день, выраженный в процентах. Тогда дневную волатильность данного показателя можно оценить следующим образом:
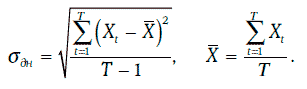
Иными словами, дневная волатильность принимается равной стандартному отклонению логарифма относительного изменения финансового показателя за один день.
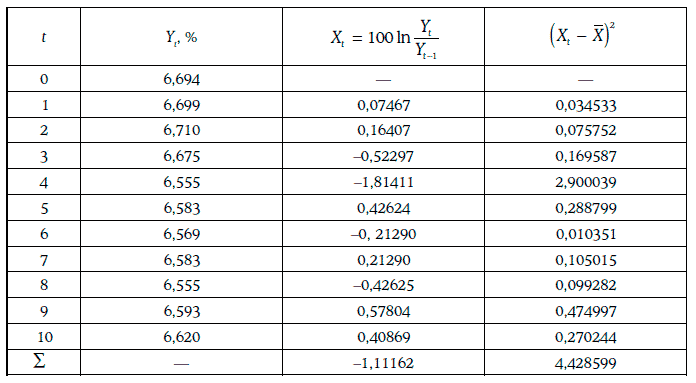
Пример 1.60. В течение 11 последовательных рабочих дней биржи определялась доходность 30-летних казначейских облигаций с нулевыми купонами. Расчет дневной волатильности доходности на основе этой информации приведен ниже.
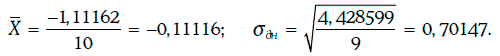
Таким образом, дневная волатильность доходности 30-летних облигаций с нулевыми купонами оценивается в 0,70 %.
Если случайные величины Xt не коррелируют между собой, то, зная дневную волатильность доходности финансового инструмента, можно оценить волатильность доходности этого инструмента за данный период времени:

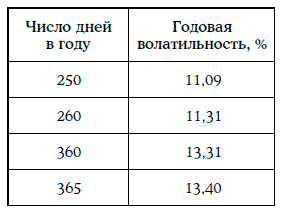
В частности, для того чтобы определить годовую волатильность, необходимо для каждого конкретного случая правильно определить число рабочих дней в году. Число рабочих дней в году может быть равным 250, 260 или 365.
Пример 1.61. В примере 1.60 была найдена дневная волатильность доходности 30-летних казначейских облигаций с нулевыми купонами: σдн = 0,70147.
Ниже указана годовая волатильность доходности при разных оценках числа дней в году:
Предположим, что в данный момент времени доходность финансового инструмента равна r. Можно считать, что доходности за один день распределены логнормально с параметрами 0 и σдн. Если логарифмы относительных изменений доходности не коррелируют между собой, то отношение доходности через год к доходности г будет распределено также логнормально, но с параметрами (0, σгод). Следовательно, сама доходность финансового инструмента через год должна иметь логнормальное распределение с параметрами (ln r, σгод).
Если годовая волатильность доходности достаточно мала, то можно считать, что доходность финансового инструмента через год распределена приблизительно нормально с параметрами r и rσгод.
Пример 1.62. Текущая доходность 10-летних казначейских облигаций с нулевым купоном равна 8 %, а годовая волатильность этой доходности равна 15 %.
Можно предположить, что доходность 10-летних облигаций с нулевыми купонами через год будет приблизительно распределена нормально с ожидаемым значением 0,08 и стандартным отклонением 0,08-0,15 = 0,012. Отсюда, в частности, следует, что с вероятностью 95,5 % доходность через год окажется между 0,08-2 • 0,012 = 0,056 и 0,08 + 2 • 0,012 = 0,104, т. е. будет принимать значение между 5,60 и 10,40 %.
1.24. Элементы регрессионного анализа
Во многих случаях требуется установить зависимость между двумя случайными величинами. Чаще всего предполагается линейная зависимость. Например, при обмене облигаций использовалась линейная зависимость между изменениями доходностей двух облигаций.
Рассмотрим две случайные величины ξ и η и предположим, что когда случайная величина ξ принимает значения X1, X2…., Xn, то случайная величина η принимает соответственно значения Y1, Y2…., Yn.
Линейной регрессионной моделью называют уравнение следующего вида:
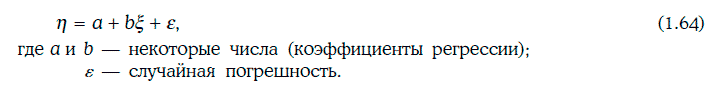
При построении линейной регрессионной модели коэффициенты а и b необходимо подобрать так, чтобы влияние случайной погрешности ξ на случайную величину η было как можно меньше.
Из уравнения (1.64) следует, в частности, что
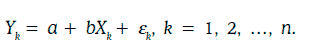
Коэффициенты регрессии а и b чаще всего подбираются методом наименьших квадратов (least squares), который сводится к отысканию значений а и b так, чтобы достигалось наименьшее значение функции

Нетрудно проверить, что наименьшее значение функции (1.65) достигается при
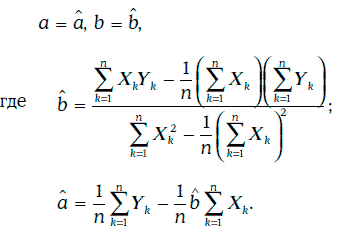
При выборе коэффициентов регрессии указанным выше способом будут выполняться следующие соотношения:
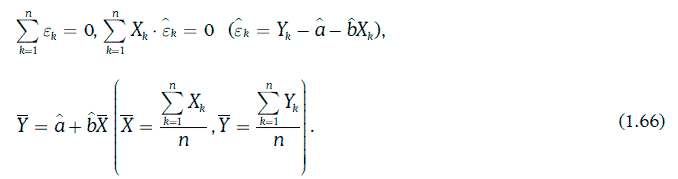
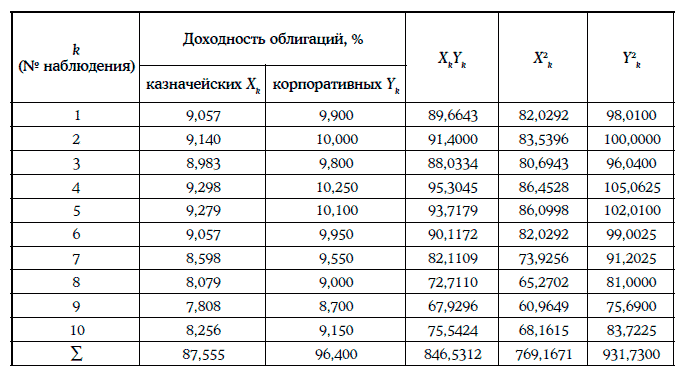
Пример 1.63. Построение линейной регрессионной зависимости доходности среднесрочных корпоративных облигаций одного и того же кредитного рейтинга (η) от доходности 10-летних казначейских облигаций (ξ). Исходная информация и предварительные расчеты приведены в таблице ниже.
Коэффициенты регрессии находят следующим образом:
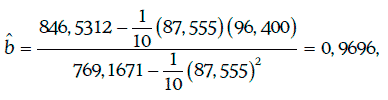
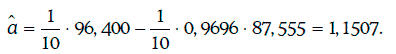
Уравнение регрессии в данном случае имеет вид:
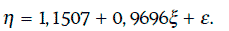
Из соотношения (1.66) следует, что
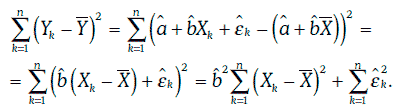

Отношение суммы квадратов, объясняемой регрессией, к полной сумме квадратов называют коэффициентом детерминации и обозначают R2. Таким образом,
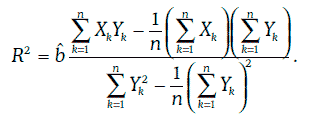
Коэффициент детерминации всегда находится между 0 и 1, причем чем ближе коэффициент детерминации к единице, тем выше качество регрессионной модели.
Пример 1.64. Оценим качество регрессионной модели, построенной в примере 1.63.
В данном случае коэффициент детерминации может быть найден следующим образом:
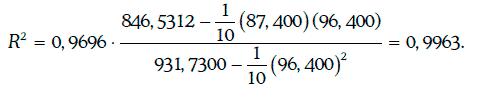
Так как коэффициент детерминации очень близок к единице, то качество регрессионной модели достаточно высокое.
Оценка коэффициентов регрессии получена нами в зависимости от выборки значений X1, X2…., Xn независимой случайной величины ξ и соответствующих им значений зависимой случайной величины η. Для другой выборки значений случайной величины ξ будут получены, вообще говоря, другие оценки коэффициентов регрессии и другая случайная погрешность. В связи с этим возникает задача построения доверительных интервалов для коэффициентов регрессии.
Если предположить, что случайные погрешности не коррелируют между собой (т. е. отсутствует автокорреляция), то доверительные интервалы для коэффициентов регрессии с надежностью 95 % строятся следующим образом:
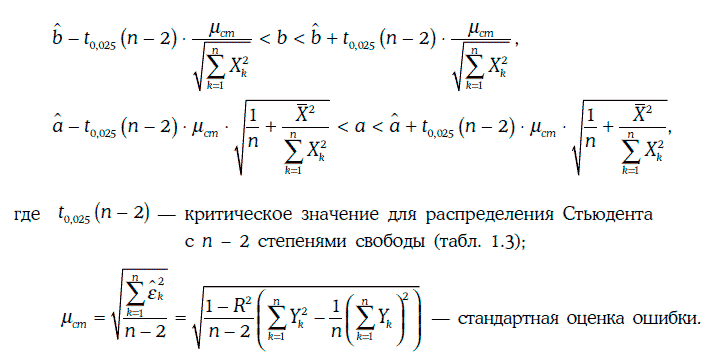
Если случайная величина ξ принимает значение Х, то согласно линейной регрессионной модели:
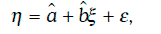
а ожидаемое значение случайной величины η равно
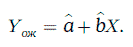
При отсутствии автокорреляции[17] и гетероскедастичности[18] доверительный интервал для значения случайной величины η при заданном уровне надежности может быть найден в виде:
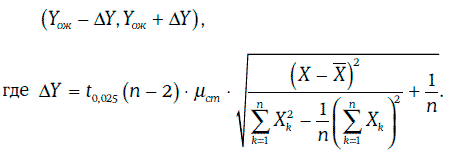
Пример 1.65. Инвестор считает, что через месяц доходность 10-летних казначейских облигаций окажется равной 8 %. Тогда согласно регрессионной модели, построенной в примере 1.63, ожидаемое значение доходности корпоративных облигаций будет равно
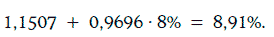
Для определения доверительного интервала для доходности корпоративных облигаций с надежностью 95 % найдем:
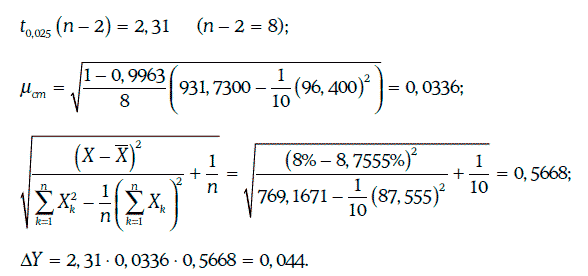
Следовательно, искомый доверительный интервал: (8,87 %; 8,95 %).
1.25. Метод Монте-Карло
Случайная величина γ, принимающая 10 значений: 0, 1, 2, 3, …, 9 с одинаковой вероятностью, называется случайной цифрой.
Предположим, что мы произвели N независимых опытов, в результате которых получили N случайных цифр. Записав эти цифры (в порядке их появления) в таблицу, получим то, что называется таблицей случайных цифр. Например, таблица из 150 случайных цифр может иметь следующий вид (цифры разбиты на группы для удобства чтения таблицы):

Случайным числом (random number) называется случайная величина
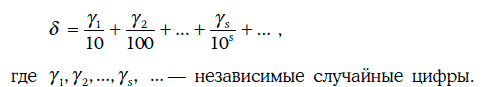
Иными словами, случайное число – это случайная величина, равномерно распределенная на промежутке [0, 1).
Если задана таблица случайных цифр, то можно строить различные случайные числа, как, например:
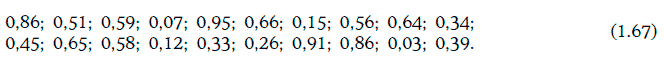
В настоящее время существуют специальные компьютерные программы для построения случайных чисел в любом количестве. Такие программы называют генераторами случайных чисел.
Рассмотрим теперь дискретную случайную величину ξ, распределение которой имеет вид:


Равенство (1.68) позволяет каждому случайному числу приписать определенное значение случайной величине ξ. Такой процесс приписывания значений случайной величине ξ часто называют разыгрыванием этой случайной величины.
Пример 1.66. Случайная величина ξ принимает значения 1 и 2 с вероятностью 0,6 и 0,4 соответственно. В данном случае
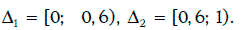
Значения этой случайной величины, приписываемые случайным числом из последовательности (1.67), приведены ниже:

Частоты появления 1 и 2 соответственно равны 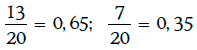 и близки к их вероятностям. Чтобы получить лучшую модель, необходимо рассмотреть большее количество случайных чисел.
и близки к их вероятностям. Чтобы получить лучшую модель, необходимо рассмотреть большее количество случайных чисел.
Предположим, что даны две случайные величины ξ и η, совместное распределение которых имеет вид:
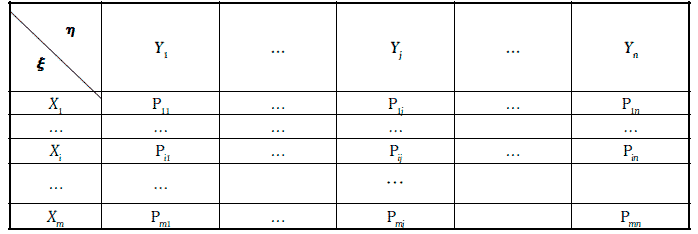

Равенство (1.69) позволяет каждому случайному числу приписать определенную пару значений случайных величин ξ и η. Такой процесс приписывания значений паре случайных величин (ξ, η) называют разыгрыванием этой пары.
Если случайные величины ξ и η независимы, то для разыгрывания пары (ξ, η) достаточно разыграть каждую случайную величину в отдельности. Для разыгрывания непрерывной случайной величины можно вначале найти дискретную случайную величину, близкую к данной случайной величине, а затем разыграть эту дискретную случайную величину.
Метод Монте-Карло позволяет численно находить различные вероятностные характеристики случайной величины η, зависящей от большого числа других случайных величин ξ1, ξ2…., ξn. Этот метод сводится к следующему: разыгрывается последовательность случайных величин (ξ1, ξ2…., ξn), для каждого розыгрыша определяется соответствующее значение случайной величины η, а по найденным значениям строится эмпирическое распределение вероятностей этой случайной величины.
Пример 1.67 [5]. Инвестор владеет портфелем, состоящим из одной казначейской облигации и двух корпоративных облигаций одного и того же кредитного рейтинга. Основные параметры портфеля указаны в таблице:

Инвестора интересует реализуемая доходность портфеля облигаций за 6 месяцев. По его мнению, реализуемая доходность портфеля будет определяться следующими двумя факторами: кривой доходностей казначейских облигаций через 6 месяцев и спредом между доходностями корпоративных и казначейских облигаций. Предположим, что инвестор располагает еще и следующей информацией:
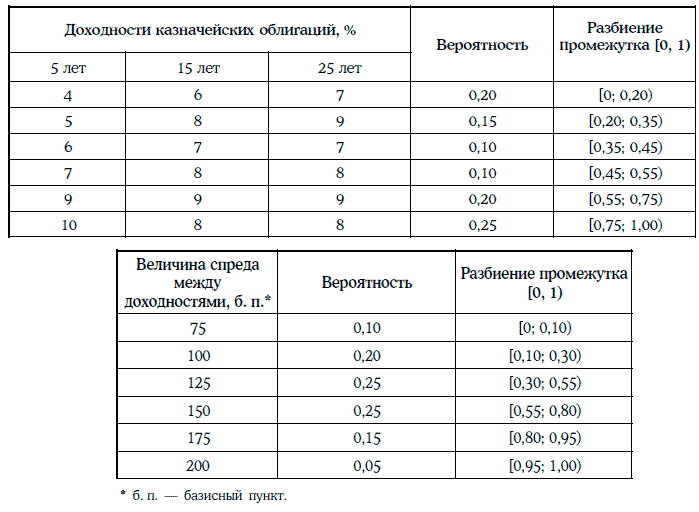
Для определения реализуемой доходности портфеля облигаций можно использовать метод Монте-Карло.
Первая итерация (случайные числа: 0,91 для кривой доходностей и 0,12 для спреда между доходностями). В этом случае доходности казначейских облигаций со сроком до погашения 5, 15 и 25 лет составят соответственно 10, 8 и 8 %, а доходности корпоративных облигаций со сроком до погашения 15 и 25 лет – 9 и 9 %.
Тогда цены облигаций (на номинал в 100 долл.) через 6 месяцев определяются следующим образом:

Предположим, что было проведено 100 итераций. При этом оказалось, что наименьшая реализуемая доходность портфеля равна -3,905 %, а наибольшая реализуемая доходность составляет 24,97 %.
Разделив отрезок [-3,905 %; 24,97 %] на достаточно большое число частей, подсчитаем для каждой части число итераций, дающих реализуемую доходность из этой части.
Таким образом, будет построено эмпирическое распределение вероятностей реализуемой доходности портфеля облигаций. После чего можно получить различные числовые характеристики этой реализуемой доходности: среднее значение, стандартное отклонение и т. д.
1.26. Случайные процессы и их основные характеристики
Дано основное вероятное пространство
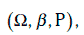
где Ω – пространство элементарных событий;
β – σ-алгебра случайных событий;
Р – вероятностная мера.
Рассмотрим некоторое числовое множество V, элементы которого в дальнейшем будем считать моментами времени.
Функция ξ(w, t) двух переменных w ∈ Ω и t ∈ V называется случайным процессом (stochastic process), определенным на множестве V, если для любых t ∈ V и x ∈ R (R – множество всех действительных чисел) множество

т. е. является случайным событием.
Из условия (1.70) следует, что если на множестве V определен случайный процесс ξ(w, t), то каждому моменту времени t ∈ V поставлена в соответствие случайная величина ξt(w) = ξ(w, t). Случайная величина ξt(w) называется сечением случайного процесса в момент времени t.
Таким образом, чтобы на множестве V задать некоторый случайный процесс, достаточно каждому моменту времени t ∈ V поставить в соответствие ту или иную случайную величину ξt(w) – сечение этого случайного процесса. В силу этого случайный процесс можно обозначить как ξt(w) или просто ξt.
Если на множестве V задан случайный процесс ξ(w, t), то при каждом фиксированном элементарном событии w ∈ Ω мы имеем функцию одного переменного t. Эту функцию, определенную на множестве V, называют траекторией, или реализацией, случайного процесса ξ(w, t).
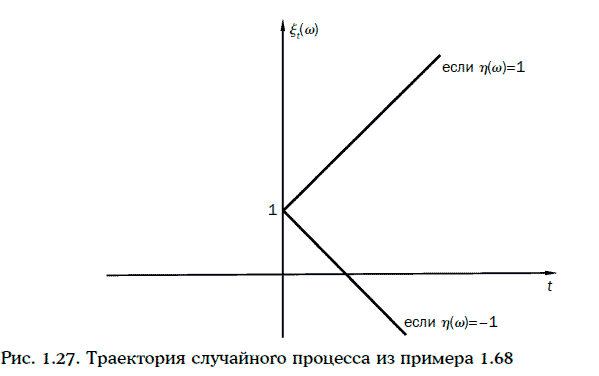
Пример 1.68. Рассмотрим случайный процесс
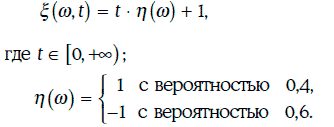
Сечением данного случайного процесса в момент времени t = 2 является случайная величина 2η(w) + 1. Траектории случайного процесса ξ(w, t) изображены на рис. 1.27.
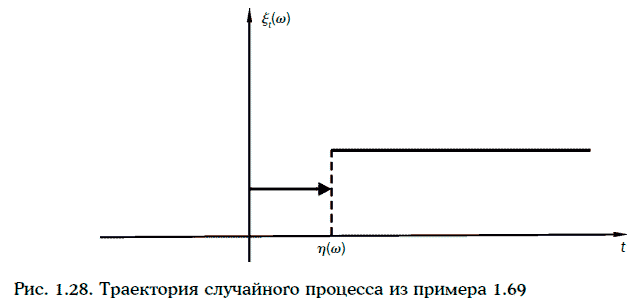
Пример 1.69. Случайный процесс на [0, +∞) определен следующим образом:
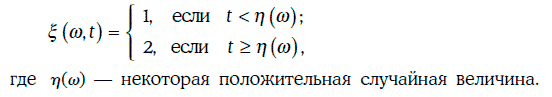
Сечением случайного процесса ξ(w, t) в момент времени t является случайная величина, принимающая значение 1 с вероятностью, равной P{η(w) > t}, и значение 2 с вероятностью, равной P{η(w) ≤ t}.
Траектория случайного процесса ξ(w, t) имеет вид, изображенный на рис. 1.28. Важнейшими характеристиками случайных процессов являются математическое ожидание и дисперсия.

Пример 1.70. Найдем математическое ожидание и дисперсию случайного процесса из примера 1.68.
Пример 1.71. Рассмотрим случайный процесс из примера 1.69, считая, что случайная величина η(w) распределена показательно с плотностью
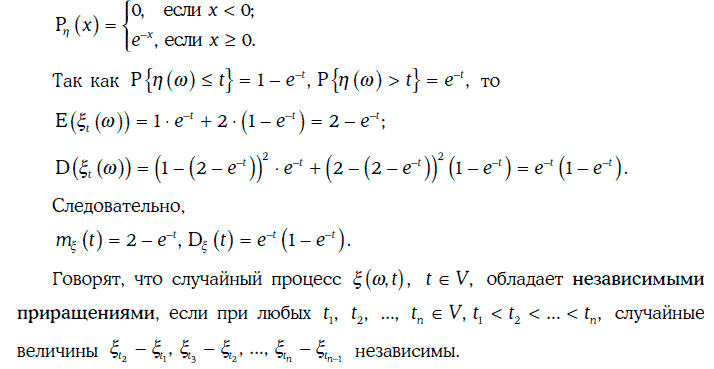
Случайные процессы с независимыми приращениями играют важную роль при моделировании эволюции финансовых показателей. Это объясняется тем, что финансовый рынок принято считать эффективным (efficient), если цены активов на этом рынке полностью отражают всю имеющуюся информацию об этих активах. На эффективном финансовом рынке изменения цен активов могут происходить только из-за появления новой информации (которая, вообще говоря, непредсказуема). Это означает, что изменения цены активов на таком рынке должны быть в некотором смысле независимы.