



Анатолий Левенчук
Методология 2025
Задания: принципиальные схемы
Поставьте отметку о выполнении:
1. Написан пост о принципиальной схеме вашей системы. Особо проверьте, что в принципиальной схеме показаны функциональные, а не конструктивные объекты. Отметьте, вы где-то нашли эту принципиальную схему, или вам пришлось её составить для этого задания самостоятельно?
2. Написан пост о принципиальной схеме организации-создателя вашей системы. Особо проверьте, что в принципиальной схеме показаны оргроли, а не оргзвенья. Отметьте, вы где-то нашли эту принципиальную схему, или вам пришлось её составить для этого задания самостоятельно?
Пример: методы создания систем AI
То, что было рассказано в предыдущем разделе, конечно, применимо не только к «железным» системам, требующим физического моделирования. В качестве примера рассмотрим функциональные описания (то есть описания ролей и методов их работы) в прикладной методологии систем AI. Конечно, если вы никогда не сталкивались с предметной областью разработки систем AI, вам трудно будет понять этот текст в части его содержания. Но вы можете обращать внимание не на собственно содержание (что там говорится про сами системы AI), а обращать внимание на форму того (мета-мета-модель фундаментальной методологии, а не мета-модель методологии систем AI), что о них говорится – какие там используются диаграммы, что рассказывается про сами методы, на какие особенности использования терминологии обращено внимание. Это примерно как логиков тренируют на тексты про сепульки: смысл непонятен, но логические ошибки могут быть очевидны. Вот так и тут: обращайте внимание на то, что говорится про методологию и методы, а термины для самих методов и ролей могут быть загадочны.
Главный посыл этого подраздела: материал курса «Методология» общеприложим к самым разным системам. При этом мы признаём, что начиная со следующего раздела мы главным образом будем рассказывать про методологию в её версии для методов работы систем-создателей в графах создания каких-то систем. Но вот первый раздел показывает, что методология вполне приложима как метод мышления о не слишком интеллектуальных «железных» агентах, хотя там термин больше используется не «метод», а «функция». Методология приложима и к методам/функциям работы таких «не совсем пока интеллектуальным» агентов, как нынешние системы AI.
Сегодня (а про завтра ничего сказать пока нельзя) центральное место в функциональной декомпозиции систем AI занимают искусственные нейронные сети. Поглядим на очень грубо составленное дерево/аутлайн системных уровней систем AI:
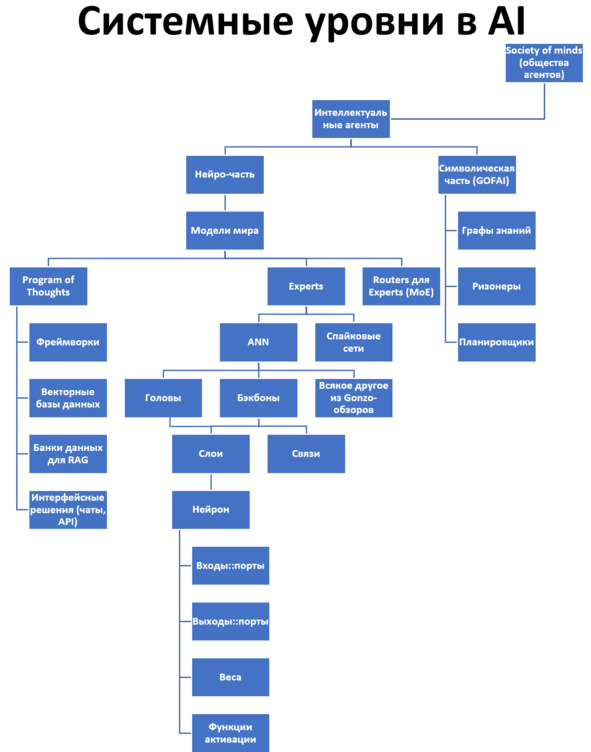
Стек тут – любой проход по одной вертикали в этом дереве, но помним о сложностях разложения методов в дерево. Есть сложности моделирования разбиения функциональных объектов – роли ведь тоже можно декомпозировать по-разному, трудности разложения в спектр их методов работы тут проявляются в полной мере. Так, обратите внимание, что слои есть и у голов, и у бэкбонов как частей ANN, ибо «слой» из «нейронов» вроде как составная часть ANN, но верхние слои – это «головы» (их может быть и несколько), а нижние слои – бэкбоны. Как мы и говорили, очень трудно представить «чистый стек», но и «чистое дерево» представить тоже трудно, и то же самое будет даже с графами. В следующих разделах мы покажем, как многие такие представления конвертировать в табличные, но содержательно это не убавит проблем. При разузловке/разбиении и синтезе что ролей, что их методов, придётся каждый раз в каждом проекте включать голову – и думать.
На диаграмме представлено функциональное разбиение системы, то есть дерево ролей (подсистемы, функциональные объекты). Но надо понимать, что речь идёт в том числе и о функциях этих ролей, за каждой ролью может быть множество видов методов, которые могла бы выполнять роль (помним, что в актуальной системе метод уже обычно выбран, но вот в момент проектирования системы – ещё нет, обсуждаем множество методов).
В текущем подразделе мы приводим пример разговора про методы работы систем AI: что там делают подсистемы и подсистемы подсистем, обмениваясь данными, это dataflow представление. Центральное место в функциональном разбиении системы AI занимает искусственная нейронная сеть (ANN, artificial neural network), подсистема системы экспертов (несколько нейронных систем объединяются как «эксперты» в смеси экспертов, MoE, mixture of experts)49:
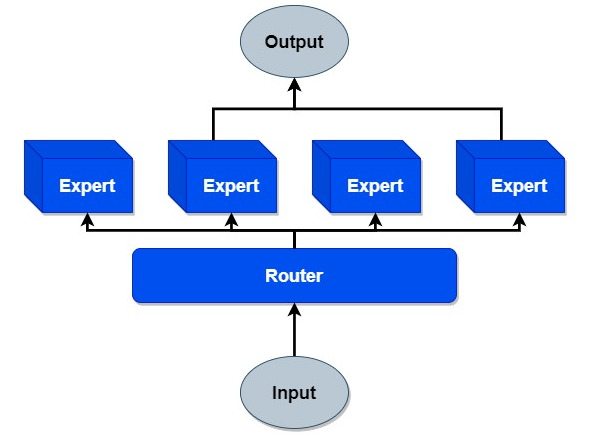
В суперупрощённом виде мы видим функциональную диаграмму: какая-то входная информация даётся на вход маршрутизатора, который выбирает пару экспертов из четырёх возможных, а затем ответы этих экспертов как-то замешиваются в выходную информацию. Вот эти «эксперты» обычно – искусственные нейронные, ANN, artificial neural network сети с классической декомпозицией на «слои» из вычислительных «нейронов»50. Вот типичная функциональная диаграмма для ANN (традиция называет такие диаграммы «архитектурами», но в этой «архитектуре» ни слова не говорится о конструктивах, это в других предметных областях было бы «принципиальная схема»), на ней представлен трансформер/transformer51 как вид ANN, отвечающий подобного сорта функциональной диаграмме, эта «принципиальная схема» была предложена в 2017 году:
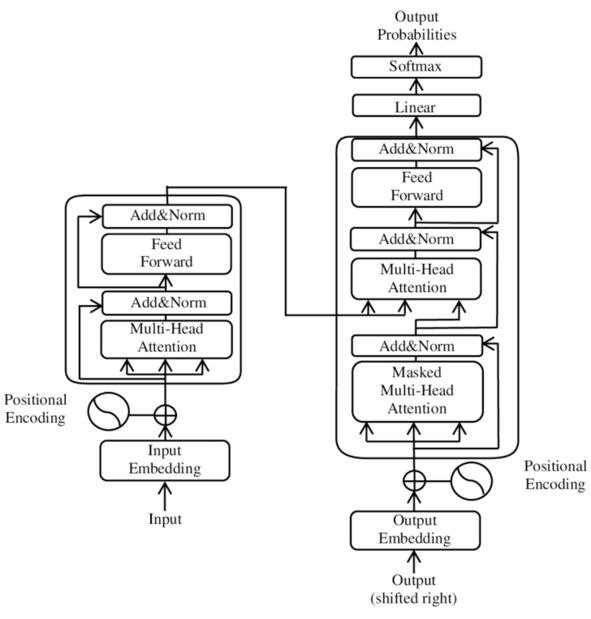
Стрелки тут обозначают движение потоков данных (dataflow), а блоки – обработчики данных (функциональные объекты, выполняющие обработки каждый по своим методам). Обработчики данных представляют по факту как-то модифицированные «слои» из отдельных «нейронов», плотно перевязанных связями.
Обзором техноэволюции ANN занимается прикладной методолог систем AI Григорий Сапунов в канале «Gonzo-обзоры ML статей»52. Основное содержание его обзоров много лет было как раз посвящено модификациям принципиальных схем ANN. В Gonzo-обзорах первый раз слово «метод» встречается 25 февраля 2019 в обзоре работы «AET vs. AED: Unsupervised Representation Learning by Auto-Encoding Transformations rather than Data»53, там фраза «Дальше в работе рассматривают только параметрические преобразования. Это типа проще реализовывать, а также проще сравнивать с другими unsupervised методами». Онтологически из фразы следует, что «unsupervised learning»:: метод – это род методов, в котором есть множество видов методов. Обратите внимание, что методы – это поведение, а до этого в подразделе мы обсуждали вроде как функциональные разбиения ролей на подроли (систем на подсистемы, в функциональном рассмотрении – разбиение функциональных объектов, а не поведения). Вот эта связанность роли и метода должна как-то удерживаться, нельзя думать про одно без другого: не может «никто» делать что-то, и «кто-то» не может ничего не делать! Опять же, роль может работать по какой-то сигнатуре метода, а там внутри можно даже менять методы в их разложении для этой сигнатуры, а роль поможет удерживать внимание на результирующем методе, абстрагируясь от его разложения.
Если продолжить читать текст статьи, пытаясь найти там «методы», то придётся признать, что в статье они обсуждаются, но называются крайне разнообразно – и меньше всего словами, которые у нас в курсе даны как синонимы слова «метод». В статье «метод» обозначен то как «подход», то как «архитектура», и даже «efforts» как метонимия усилий команды, разработавшей метод, в фразах типа «Among the efforts on unsupervised learning methods, the most representative ones are Auto-Encoders and Generative Adversarial Nets (GANs)». Весь наш курс посвящён тому, что мы под всеми этими именами распознаем метод::тип – и с этого момента всё содержание нашего курса «Методология» приложимо к этим «подходам», «архитектурам» и даже «efforts». Заодно заметьте, что слово representative в текущей фразе не имеет отношения к representation learning, хотя казалось бы, могло бы и иметь. Со всем этим можно разобраться из контекста, как это и изучалось в курсе «Рациональная работа».
Помянутые методы «Auto-Encoders and Generative Adversarial Nets» (ещё раз внимание: методы называют как функциональные объекты, «автоэнкодеры» и «сети», а не поведения!) в их совокупности называют вместе родом Auto-Encoding Data (AED) как выучивание распределения по данным (выучивание – глагол, «выучивание распределения по данным» – это таки метод), и вводят ещё один род на этом же уровне: Auto-Encoding Transformations (AET, и transformations – это опять-таки отглагольное существительное, метод), где могут быть ещё и виды таких трансформаций: large variety of transformations can be easily incorporated into the AET formulation. Так, виды будут – параметрические преобразования::метод (Parameterized Transformations, как подвиды там пример – афинные и проективные), а ещё GAN (generative adversarial network – сеть, неожиданно существительное, то есть роль, а не способ работы, имеется в виду метонимия – «преобразования, которые производят GAN») и непараметрические преобразования.
Преобразования – это transformations, в русском тексте gonzo-обзора синонимизируются трансформации и преобразования. Вопрос, преобразования чего – какой предмет метода? Ведь «данные» – это явно совсем высокий уровень мета-моделирования, надо всегда стараться слова «информация» и «данные» как слишком общие типы мета-мета-модели в предметной области заменять на типы мета-модели (в курсе «Системное мышление» специально подчёркивалось, что сверхобобщения – вредны). В статье речь идёт о данных изображений, ибо текст 2019 года обсуждает главным образом распознавание изображений на тестах типа CIFAR-1054.
Статья, несмотря на всё разнообразие используемой терминологии по части методов, следует давней традиции: роды самых разных методов называют именно «методом», а всё более мелкое в видах методов и разложениях выбранного вида метода называют «как бог на душу положит», и только иногда – методом, рабочим процессом, культурой, практикой и т. д. В обсуждаемой статье supervised learning консистентно называют «метод машинного обучения» (то есть вид «машинного обучения»:: метод работы какой-то «статистической модели»:: «функциональный объект», познающей/выучивающей/learn какое-то статистическое распределение), а вот виды этого метода как рода (то есть разные варианты supervised learning, из которых в конечном итоге будет выбран только какой-то один) и методы в разложениях этих видов (составляющие метода, которые будут задействованы «одновременно», отражены одной принципиальной схемой) называются уж как придётся. Но мы-то знаем, что всё это методы!
Поэтому наше мышление тут работает одинаковыми ходами, чему и посвящён наш курс. Вы можете не быть большим специалистом в машинном обучении – но если вы читаете статью про машинное обучение, то сможете разобраться, как минимум, какие типы объектов там рассматриваются и как они соотносятся друг с другом. Это существенно помогает разбираться с новыми предметными областями.
Как же выглядит разложение методов работы нейросетей? Когда вы смотрите на диаграммы «архитектуры нейросетей», то вы должны понимать, что это функциональные диаграммы, которые по принципу мало отличаются от принципиальной схемы холодильной установки. Эта «принципиальная схема»/«функциональная диаграмма»/«dataflow diagram», показывающая потоки данных примерно так же, как электрическая принципиальная схема показывает потоки электрического тока, а гидравлическая схема показывает потоки жидкости – это и есть один из способов показать работу ролей по их методам работы, разложение метода, ответ на вопрос «как оно работает».
С показом разложения метода обычно никаких затруднений не бывает. Но бывают затруднения с методами в их родо-видовых отношениях, они показываются как классификаторы. По большому счёту родо-видовые отношения задаются произвольно, а спор о том, как мы определяем род и вид конкретного объекта – это обычно «спор о терминах», онтологический спор, который непродуктивен. Но делать нечего, работаем с ламаркианскими классификаторами, как биологи работали со своими классификаторами до той поры, когда разобрались в генетике. Так что мы вынуждены будем разбираться в меметике AI-систем, ибо речь идёт о техно-эволюции со smart mutations (если вам эти термины показались незнакомы, попробуйте перепройти курс «Системное мышление», это всё там обсуждалось).
Пробегаем Gonzo-обзоры до 30 апреля 2024, когда там55 появилась ссылка на обзор PEFT (Parameter-Efficient Fine-Tuning) алгоритмов для LLM. Смотрим на то, как употреблено слово «алгоритм» – ах, это те же методы! Как проверить? Берём картинку из статьи56 и видим типичную ламаркианскую классификацию родов-видов именно методов, причём картинка названа именно классификаторски, «таксономией», аж на пять уровней:

Но если мы поглядим на то, что же такое PEFT даже не в самой статье, а просто аннотации, то увидим, что слово «метод» употребляется не как объект первого класса, а как что-то литературно-художественное, что тоже требует синонимизации, для пущей выразительности, термином авторы «метод» не считают: один раз это род разных видов «процессов» (но из курса «Методология» мы знаем, что «процесс» – это тоже часто синоним «метода», а уж «рабочий процесс» – это точно «метод», только в менеджменте), а вот в другой раз – это род алгоритмов. Как это читать? А так и читать: алгоритм/теория/объяснение описывает метод (а чтобы не было сомнений, что теория и алгоритм – это одно и то же, то можно вспомнить про соответствие Curry-Howard – императивные и логические программы суть одно и то же, математические доказательства – это программы). Метод – это то, что делают в жизни нейросетки, проявляя «мастерство выполнения метода», а алгоритм – это то, что было взято для реализации этого мастерства для программирования вычислителя, проявляющего затем метод.
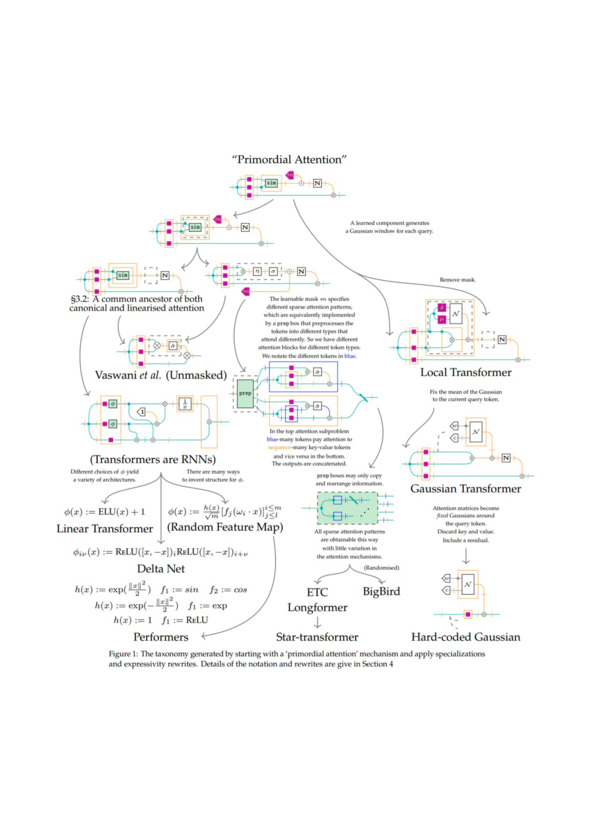
Если попытаться формализовать методологическую работу для систем AI, то от простых dataflow диаграмм можно перейти к псевдокоду, используя парадигму функционального программирования, а потом и просто к программному коду (возможно, уже мультипарадигмальному) – и там кодировать алгоритм метода с точностью, достаточной для машинного исполнения этого кода. Но если пытаться строже формализовать описание методов работы систем AI, не погружаясь в детальные описания на языках программирования, на помощь приходит теория категорий, дающая удобный формализм для математического описания методов/функций, в том числе и дающая диаграммную нотацию. Примером тут может служить работа «On the Anatomy of Attention»57, где приводится диаграммная теоркатегорная нотация для методов работы систем AI, при этом особое внимание уделяется методам внимания. Вот пример диаграммы таксономии методов из этой работы (см. диаграмму ниже).
Отдельно заметим, что в тексте текущего подраздела ничего не говорилось про конструктивы систем AI: мы понимаем, что алгоритмы, описывающие методы работы нейросетей реализуются на каких-то вычислителях, и эти вычислители – физические устройства со своими ограничениями. Например, где-то может быть ограничение по размеру памяти, и нужно будет выбрать вид метода, который даёт нужные результаты, но задействует немного памяти.
А где-то будет достаточно памяти, но важна будет латентность: сколько времени будет занимать обработка входной информации, сколько ждать результата. И надо будет выбирать метод, дающий меньшую латентность. Ну, или оставлять тот же метод, только поручая выполнение алгоритма этого метода какому-нибудь более быстрому ускорителю вычислений методов в его разложении – то есть используя специальный инструментарий. Об этом иногда говорят как hardware aware architectures. Тут архитектура уже не совсем «принципиальная/функциональная схема», «алгоритм работы», ибо хоть как-то упомянуто и конструктивное/материальное описание системы, зацеплена работа современного архитектора, предписывающего ограничения на конструктивы и способы их взаимодействия.
Представление метода работы как алгоритма: методология как алгоритмика-на-стероидах
Материал этого раздела весьма сложен, может оказаться, что вам нужно освежить азы алгоритмики. Как минимум, вы проходили алгоритмику в школе, возможно, сдавали по ней ЕГЭ, но методология требует, конечно, не школьного понимания алгоритмики. Увы, даже азам алгоритмики мало где учат. Мы можем указать на курс «Интеллект-стек» и дополнительные материалы к этому курсу58, посмотрите там, чем же занимается алгоритмика. Конечно, программистам материал этого раздела будет понимать легче, но наш опыт показывает, что и это не всегда так: материал отсылает не к «программистскому опыту», а к теоретическому знанию – объяснениям азов алгоритмики в её связи с математикой и физикой. Увы, этому даже в вузах учат отнюдь не всех «программистов с высшим образованием».
Мастерство выполнения метода – программа, которая описана алгоритмом. Мы пока опустим тот нюанс, что алгоритма совершенно недостаточно для описания программы, ибо программа – это алгоритм плюс структуры данных59, да ещё и реализованные каким-то вычислителем (подробней это обсуждалось в курсе «Системное мышление»). В случае методов мы говорим, что создатели – это обобщение «вычислителя» до «создателя» (то есть не только работаем с данными на входе и получаем данные на выходе, но берём какие-то предметы метода на входе и получаем предметы метода на выходе – делаем физические преобразования). Так что «программа метода» понимается не просто как «вычислительная программа», а как «преобразовывающая мир», «программа для станка с ЧПУ» в простейшем случае. А если создатель умный и эта программа – алгоритм в мокрой нейросети, или даже гибридной нейросети предприятия (из мокрых нейросетей множества людей и компьютерных сухих нейросетей плюс много компьютерной памяти и ещё станки в поддержку вычислений и преобразований), то мы назовём её «мастерство».
При этом интеллект – это тоже мастерство, которое задействуется в ситуации, когда метод действия неизвестен. В курсе «Интеллект-стек» рассказывается про интеллект как мастерство в методах фундаментального мышления, а дальше демонстрируется разложение методов фундаментального мышления в стек, причём шкала там упорядочена по отношению простоты объяснения методов (понятизация позволяет объяснить собранность, собранность позволяет объяснить семантику, семантика – математику, и так далее).
С подробным описанием метода плохо справится даже граф (визуально это будет «диаграмма», «принципиальная схема» и небольшое количество типов узлов графа и типов рёбер графа), но хорошо справится алгоритмическое представление в виде:
• алгоритма и предметов метода на естественном языке, это самая маленькая формальность представления метода на шкале формальности
• алгоритма и предметов метода на псевдокоде (похоже на какой-то формальный язык – но на самом деле формализация недостаточна для полностью машинного выполнения на классическом компьютере с языком программирования)
• алгоритма и предметов метода в виде кода на каком-то языке программирования, полностью формальное (подразумевающее «машинное» однозначное) выполнение.
И тут важная особенность: разложение метода очень плохо прописывать императивно (как пошаговое выполнение каких-то отдельных операций), но хорошо прописывать функционально или в какой-то другой парадигме вычислений (в нашем случае – обобщённых вычислений, с выходом в изменения физического мира и получением информации замерами состояний предметов метода в физическом мире). В программной инженерии есть огромное число обсуждений того, чем лучше и чем хуже декларативное программирование по сравнению с императивным. Первый же аргумент против декларативного программирования, из вариантов которого наиболее проработано функциональное программирование – оно слишком сложное. Вот пример декларативного и императивного подхода к разложению методов «варка борща» и «нахождение клада» из текста, который так и озаглавлен «Почему функциональное программирование такое сложное»60:
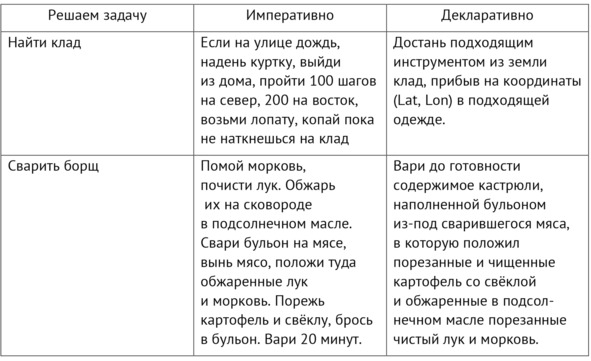
Пример замечателен тем, что описание разложения методов как алгоритма даётся сразу для создателя, то есть описываются действия в реальном физическом мире, а не с данными программы. Но весть текст статьи – про программирование и потоки данных в функциональном подходе к описанию алгоритмов, а не потоки управления в императивном подходе. А в примере – потоки предметов метода, а не потоки данных, то есть изменение состояния объектов в реальном мире.
В самом тексте делается попытка объяснить программистам, что же такое функциональное программирование, и зачем оно нужно (таких текстов тысячи!), и зачем там вообще нужна математика, включая не самый её простой раздел – теория категорий61. Автор курса многократно сталкивался с тем, что профессиональные программисты буквально сражаются за то, чтобы разобраться с функциональным программированием, оно очень нелегко даётся. Но те, у кого произошла метанойя (термин объяснялся в «Системном мышлении») уже не помнят, что там у них было сложного – поэтому комментарии к этим всем статьям разнятся от «всё равно сложно, ничего не понял» от новичков до «зачем это разжёвывать, ничего сложного» от давно прошедших метанойю.
Тут можно напомнить, что когда-то школьное программирование вводилось в школах СССР в 1985 году ровно как попытка научить школьников планировать какие-то последовательности действий с условиями, описывать какое-то поведение. Под планированием имелось в виду не ресурсное планирование, то есть составление плана-графика (кто когда что с чем делает), но как раз методологическая работа – описание того, что вообще надо делать. В обосновании звучало, что выражению алгоритма как описанию каких-то действий (слово «метод работы» тогда не звучало, в лучшем случае звучало «описание работы», а не «описание методов работы») не учат ни в одном предмете, изучаемом в школе – физика, математика, география и любой другой предмет мог сам рассказывать о каких-то методах работы, но вот записать какой-то метод работы хоть в каком-то формальном виде ни один предмет не учил. Как и во всём мире для обучения школьников, для выражения алгоритма был выбран императивный язык.
Обучение алгоритмике как разговору о методах работы, «планированию» или даже «программированию» в смысле «программы работ», провалилось, вместо этого пошло обучение алгоритмике как «олимпиадному программированию» (решение коротких учебных задач на алгоритмическом языке) с обоснованием того, что «всем придётся программировать на компьютере, вот и научим». Сейчас понятно, что изначально цели ровно такими и были: методологическое обоснование (обучение методологии, описанию методов своей работы) было только для того, чтобы протащить обоснование для изучения информатики (computer science).
Так что для возвращения тематики «обучения составлению алгоритмов выполнения работ» в обучение программированию нужно сделать довольно много:
• Сразу вводить понятие метода как работ не только с описаниями (абстрактными объектами, информацией, работы с данными – «компьютерное программирование»), но и с предметами метода. Алгоритмика не компьютерная, а созидательная (программирование создателей/constructors из теории создателей).
• Добавить обсуждение работы с типами предметов метода (а не только типами данных и структурами данных), ибо программа = алгоритм плюс данные.
• Алгоритмы надо будет выражать на декларативном (скорее всего, функциональном) языке. Хотя, по большому счёту, нужно владеть мультипарадигмальным программированием – ибо для разных вариантов алгоритмов удобней разные варианты парадигм программирования62, отражённые в разных языках программирования, всё большее число современных языков программирования сегодня – мультипарадигмальные языки, поддерживают и процедурную, и функциональную парадигмы.
• Придётся освоить азы математической теории категорий и конструктивного математического мышления, это нужно для глубокого понимания природы функционального программирования, а также природы компьютерных вычислений в связи с эквивалентностью всех возможных вычислений по каким-то алгоритмам на машине Тьюринга: логическое программирование (декларативное программирование логических рассуждений), функциональное программирование (декларативное программирование выполнения функций, в том числе функций над функциями), объект-ориентированное программирование, процедурное программирование, акторское программирование, аспектное программирование и т. д. – это просто разные способы описания разложения одного и того же метода.
Алгоритмика сама по себе связана как с выражением способа вычислений на языке какой-то парадигмы (выражение способа – это методология), так и скоростью вычисления (это операционный менеджмент, исследование операций), что зависит от физики компьютера. Так что алгоритмика – экспериментальная наука, физика компьютера вносит реализм, а формальность вычисления – математику. Поскольку каждая программа – это доказательство (соответствие Curry-Howard63), то соответствие физического процесса в компьютере (классическом, квантовом, оптическом и т.д.) и абстрактного процесса вычислений «в математике» может быть проверено только экспериментально, через экспериментальную науку. Deutsch прямо называет алгоритмику «наукой о доказательствах», ведь программы – это доказательства, конструктивная математика – это программирование, и дальше через алгоритмику можно делать ходы на выполнение доказательств (алгоритмов) на компьютерах, проекты унивалентных оснований математики и языков Agda и Coq как раз нацелены на помощь математикам со стороны компьютерной техники (подробней об этом – в курсе «Интеллект-стек», и там много ссылок на литературу).
Если расширить алгоритмику компьютеров (информатику) до алгоритмики для создателей, то описания методов – это в какой-то мере доказательства того, что предметы метода будут приведены в необходимое конечное состояние. Физическая сторона алгоритмики потребует ещё и задействования иерархии хардвера (транзисторы из разных материалов, логические ключи из транзисторов, какие-то вычислительные «ядра» из логических ключей, программирование и микропрограммирование этих самых «ядер» с выходом на софт – и так дальше вплоть до «алгоритма программы, выполняемой на микросервисах в разных датацентрах мира»), это тоже должно быть обобщено на аппаратуру мастерства и инструментария создателя. Не только вычислители/компьютеры, но и манипуляторы (например, станки) и датчики (например, видеокамеры) тоже многоуровневы, для мышления о них нужно задействовать системное мышление.
Алгоритмика должна экспериментально подтверждать, что алгоритм эффективно выполним на каком-то железе. В силу no free lunch theorem нет универсально быстрого алгоритма для всех задач, для разных ситуаций будут эффективны разные алгоритмы, а разница в эффективности алгоритмов на разном «железе» с разной физикой может быть драматической, в пересчёте на методы – это как копать котлован лопатой по сравнению с экскаватором, по сравнению с гидромеханическим размытием, по сравнению со взрывным способом. Методология с задействованием исследования операций в паре с операционным менеджментом должна экспериментально подтверждать, что создатель с его мастерством (реализованным тоже аппаратно!) и инструментарием (tooling), реализуя метод, будут получать результаты заданного качества/точности (предметы метода в заданном состоянии) в приемлемое время и при приемлемом расходе ресурсов. В алгоритмике говорят, что синтез алгоритмов должен быть hardware aware для того, чтобы алгоритм был эффективен. Вот и метод должен быть оптимизированным по инструментам (hardware aware), то есть учитывать наличные особенности инструментария, включая аппаратуру для мастерства как «управляющей программы».
Алгоритм – это вроде как последовательность вычислений, а тут – последовательность каких-то трансформаций для создателя, обобщение алгоритма для вычислителя (машины Тьюринга) на материальный/физический мир. И тут надо разбираться с теоретическими обобщениями, например, constructor theory64 как обобщения машины Тьюринга как универсального вычислителя в сторону универсального преобразователя. С помощью подобной теории мы можем пробовать выдать какие-то достижения современной алгоритмики за начальные идеи в методологии, мы вполне можем понимать алгоритмы как «алгоритмы в том числе для станка с ЧПУ» и теории не математические, а вполне себе теории про реальный мир.
Вполне можно рассматривать методологию как учение по «программированию роботов и людей» (включая «нейролингвистическое программирование» людей в его оригинальном понимании, как бы оно ни было скомпрометировано, и современный prompt engineering систем AI). Эта идея тоже может быть обобщена и на организации. Скажем, какой-нибудь стадион со всем его персоналом и сооружениями – робот, хотя и неантропоморфный. Этот робот выполняет работы по каким-то методам (описанным алгоритмами разной степени формальности), чтобы как-то загнать в себя несколько десятков тысяч человек, малая часть из которых будут развлекать другую часть, затем провести развлечение, включая пропуск только по билетам, затем кормление всей этой толпы, физическую безопасность, предоставление услуг туалетов. Часть оборудования робота-стадиона – живые люди, которые ещё не заменены каким-то оборудованием, но они выполняют относительно простые программы. Надо понимать, какими методами работает такой робот, как эти методы непротиворечиво описать и поставить, как отследить их выполнение, как разработать и построить такого робота, как эксплуатировать такого робота – и это «как» тоже про методы, и это тоже про общую алгоритмику, ибо выполнение должно быть эффективно при заданном качестве выполнения! И ещё «цифровая трансформация стадиона», то есть сдвиг выполнения методов работы в стадионе с людей на какое-то оборудование.
В существенной мере алгоритмы методов работы зависят от представления/representation знаний о предметной области: алгоритм сложения чисел с мастерством, реализующимся мокрой нейронной сеткой в человеческой голове, даже при условии её усиления ручкой-бумажкой для безошибочно работающей памяти и облегчения удержания внимания существенно зависит от нотации. В римской нотации всё плохо, а в арабской65 нотации (позиционная запись и явно представленный ноль) – даже дети справляются не только с умножением десятизначных чисел, но и с делением, что казалось бы чудом ещё тысячу лет назад. Есть разница с нотациями, которые пригодны для непосредственно мышления об объектах (операции со знаками соответствуют операциям в реальном мире – вот как с арабскими цифрами, «рассуждение легко алгоритмизируется»), и «описаниями» каких-то операций в естественном языке или даже псевдокоде, которые не так-то легко алгоритмизируются66. Хорошие нотации позволяют описать простые одинаковые последовательности операций с предметами метода для получения конечного состояния предметов метода. Плохие нотации заставляют каждый раз изобретать последовательность операций – это возможно, конечно, но только самым одарённым. А вот не для самых одарённых (тем более для компьютеров!) надо бы делать операции простыми и одинаковыми. Можно не «творить» каждый раз, а просто «посчитать по предлагаемой инструкции счёта». Не делать догадки и опровергать их, а просто «взять входные значения и без содержательного разбирательства с ними механически посчитать выходные значения».




