



Равиль Ильгизович Мухамедиев
Введение в машинное обучение
2.9. Алгоритм k ближайших соседей (k-Nearest Neighbor – k-NN)
Алгоритм [[58], [59]] основан на подсчете количества объектов каждого класса в сфере (гиперсфере) с центром в распознаваемом (классифицируемом) объекте. Классифицируемый объект относят к тому классу, объектов у которого больше всего в этой сфере. В данном методе предполагается, что веса выбраны единичными для всех объектов.
Если веса не одинаковы, то вместо подсчета количества объектов можно суммировать их веса. Таким образом, если в сфере вокруг распознаваемого объекта 10 эталонных объектов класса А весом 2 и 15 ошибочных/пограничных объектов класса Б весом 1, то классифицируемый объект будет отнесен к классу А.
Веса объектов в сфере можно представить как обратно пропорциональные расстоянию до распознаваемого объекта. Таким образом, чем ближе объект, тем более значимым он является для данного распознаваемого объекта. Расстояние между классифицируемыми объектами может рассчитываться как расстояние в декартовом пространстве (эвклидова метрика), но можно использовать и другие метрики: манхэттенскую (Manhattan), метрику Чебышева (Chebyshev), Минковского (Minkowski) и др.
В итоге метрический классификатор можно описать так:
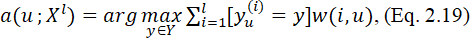
где w(i, u) – вес i-го соседа распознаваемого объекта u; a(u;Xl) – класс объекта u, распознанный по выборке Xl.
Радиус гиперсферы может быть как фиксированным, так и изменяемым, причем в случае с изменяемым радиусом радиус для каждой точки подбирается так, чтобы количество объектов в каждой сфере было одинаковым. Тогда при распознавании в областях с разной плотностью выборки количество «соседних» объектов (по которым и происходит распознавание) будет одинаковым. Таким образом, исключается ситуация, когда в областях с низкой плотностью не хватает данных для классификации.
В целом это один из самых простых, но часто неточных алгоритмов классификации. Алгоритм также отличается высокой вычислительной сложностью. Объем вычислений при использовании эвклидовой метрики пропорционален квадрату от числа обучающих примеров.
Рассмотрим пример.
Загрузка соответствующей библиотеки и создание классификатора выполняются командами:
from sklearn import neighbors
clf = neighbors.KNeighborsClassifier(n_neighbors=5, weights='distance')
Используем уже упомянутый ранее набор данных Fashion-MNIST. Однако в связи с тем, что скорость обучения и особенно классификации KNeighborsClassifier значительно ниже, чем MLP, будем использовать только часть набора: 10 000 примеров для обучения и 2000 для тестирования:
X_train1=X_train1[0:10000,:,:]
y_train=y_train[0:10000]
X_test1=X_test1[0:2000,:,:]
y_test=y_test[0:2000]
Процесс обучения классификатора:
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors = 5, weights='distance')
clf.fit(X_train, y_train)
Вывод результатов выполняется практически так же, как и в предыдущем примере. Качественные показатели классификатора, примерно следующие:
Accuracy of kNN classifier on training set: 1.00
Accuracy of kNN classifier on test set: 0.82
Примечание. Программу MLF_KNN_Fashion_MNIST_001.ipynb, использованную в данном разделе, можно получить по ссылке – https://www.dropbox.com/s/ei1tuaifi2zj2ml/MLF_KNN_Fashion_MNIST_001.html?dl=0
2.10. Алгоритм опорных векторов
Алгоритм опорных векторов (Support Vector Machines) [[60]] относится к группе граничных методов: он определяет классы при помощи границ областей. В основе метода лежит понятие плоскостей решений. Плоскость решения разделяет объекты с разной классовой принадлежностью. В пространствах высоких размерностей вместо прямых необходимо рассматривать гиперплоскости – пространства, размерность которых на единицу меньше, чем размерность исходного пространства. В R3, например, гиперплоскость – это двумерная плоскость.
Метод опорных векторов отыскивает образцы, находящиеся на границах классов (не меньше двух), т.е. опорные векторы, и решает задачу нахождения разделения множества объектов на классы с помощью линейной решающей функции. Метод опорных векторов строит классифицирующую функцию f(x) в виде:

где ⟨w,s⟩ – скалярное произведение; w – нормальный (перпендикулярный) вектор к разделяющей гиперплоскости; b – вспомогательный параметр, который равен по модулю расстоянию от гиперплоскости до начала координат. Если параметр b равен нулю, гиперплоскость проходит через начало координат.
Объекты, для которых f(x) = 1, попадают в один класс, а объекты с f(x) = -1 – в другой.
С точки зрения точности классификации лучше всего выбрать такую прямую, расстояние от которой до каждого класса максимально. Такая прямая (в общем случае – гиперплоскость) называется оптимальной разделяющей гиперплоскостью. Задача состоит в выборе w и b, максимизирующих это расстояние.
В случае нелинейного разделения существует способ адаптации машины опорных векторов. Нужно вложить пространство признаков Rn в пространство H большей размерности с помощью отображения: φ = Rn → H. Тогда решение задачи сводится к линейно разделимому случаю, т.е. разделяющую классифицирующую функцию вновь ищут в виде: f(x)=sign(⟨w,ϕ(x)⟩+b).
Возможен и другой вариант преобразования данных – перевод в полярные координаты:

В общем случае машины опорных векторов строятся таким образом, чтобы минимизировать функцию стоимости вида:

где S1 и S0 – функции, заменяющие log(hθ) и log(1–hθ) в выражении для логистической регрессии (f2) (обычно это кусочно-линейные функции); fk – функция ядра, выполняющая отображение φ и определяющая значимость объектов обучающего множества в пространстве признаков. Часто используется гауссова функция  , которая для любого x позволяет оценить его близость к x(i) и тем самым формировать границы между классами, более близкие или более отдаленные от опорного объекта, устанавливая значение δ, С – регуляризационный параметр (C=1/λ).
, которая для любого x позволяет оценить его близость к x(i) и тем самым формировать границы между классами, более близкие или более отдаленные от опорного объекта, устанавливая значение δ, С – регуляризационный параметр (C=1/λ).
Существенным недостатком классификатора является значительное возрастание времени обучения при увеличении количества примеров. Другими словами, алгоритм обладает высокой вычислительной сложностью.
Рассмотрим пример.
Подключение алгоритма и создание классификатора выполняются командами:
from sklearn.svm import SVC
clf = SVC(kernel = 'rbf', C=1)
Используем еще раз набор данных Fashion-MNIST. Скорость обучения и особенно классификации SVC значительно ниже, чем MLP, поэтому, как и в случае с KNeighborsClassifier, будем использовать только часть набора: 10 000 примеров для обучения и 2000 для тестирования. Обучение классификатора со стандартными параметрами:
from sklearn.svm import SVC
clf = SVC(kernel = 'rbf',C=1).fit(X_train, y_train)
В результате получим примерно следующие значения accuracy:
Accuracy of SVC classifier on training set: 0.83
Accuracy of SVC classifier on test set: 0.82
Отметим, что, применив поиск оптимальных параметров классификатора (см. далее раздел «Подбор параметров по сетке»), можно получить значение accuracy, близкое к 0.87.
Примечание. Ноутбук MLF_SVC_Fashion_MNIST_001.ipynb, реализующий упомянутый пример, можно загрузить по ссылке – https://www.dropbox.com/s/0p1i1dqk8wqwp5x/MLF_SVC_Fashion_MNIST_001.html?dl=0
Набор классификаторов scikit-learn включает кроме упомянутых алгоритмов еще и GaussianProcessClassifier, DecisionTreeClassifier, GaussianNB и др. Сравнение между собой классификаторов, имеющих стандартные параметры, описано в классическом примере [[61]], который можно рекомендовать как первую ступень в разработке программы выбора лучшего классификатора.
2.11. Статистические методы в машинном обучении. Наивный байесовский вывод
2.11.1. Теорема Байеса и ее применение в машинном обучении
Машинное обучение использует теорию вероятности для предсказания и классификации. Особенностью ML является создание алгоритмов, способных обучаться. Способ обучения в данном случае заключается в использовании статистических закономерностей. Одна из таких относительно простых возможностей – использование теоремы Байеса.
Напомним, что теорема Байеса говорит о том, что если известна априорная вероятность гипотезы А – P(A), априорная вероятность гипотезы B – P(B) и условная вероятность наступления события B при истинности гипотезы A – P(B|A), то мы можем рассчитать условную вероятность гипотезы А при наступлении события B:

Рассмотрим пример.
Предположим, что нам известна статистика дворовых игр в футбол и погода, при которых они состоялись, например, в таком виде:

То есть мы имеем информацию о количестве игр (14) и сведения о трех видах погоды, при которой они проходили: sunny – солнечно, rainy – дождливо, overcast – пасмурно. Попробуем рассчитать, состоится ли очередная игра, если на улице солнечно (sunny). Для этого нам нужно рассчитать вероятность того, что игра состоится ('yes') при условии 'Sunny', то есть нам нужно рассчитать:
P('yes'|'Sunny').
Другими словами, мы хотим оценить вероятность справедливости гипотезы, что А = 'yes' – игра состоится при условии, что B = 'Sunny'.
Для такого расчета нам нужно вычислить априорные вероятности того, что погода солнечная – P('Sunny') и что игра вообще состоится P('yes'). Кроме этого, рассчитать условную вероятность того, что погода является солнечной при состоявшейся игре P('Sunny'|'yes'). Тогда в соответствии с теоремой Байеса мы сможем рассчитать искомую вероятность:
P('yes'|'Sunny') = P('Sunny'|'yes') * P('yes') / P('Sunny')
Используя таблицу, легко посчитать оценки указанных вероятностей. Положим, что:
A_value = 'yes'
B_hypothes = 'Sunny'
Тогда цель нашего расчета – получить значение величины:
P(A_value|B_hypothes) = P('yes'|'Sunny') = P('Sunny'|'yes') * P('yes') / P('Sunny')
Рассчитаем условную вероятность:
P('Sunny'|'yes') = 3 / 9 = 0.33
Рассчитаем априорные вероятности солнечной погоды и того, что игра состоится:
P('Sunny') = 5 / 14 = 0.36
P('yes') = 9 / 14 = 0.64
Подставив полученные значения, получим:
P('yes'|'Sunny') = 0.33 * 0.64 / 0.36 = 0.60.
2.11.2. Алгоритм Naïve Bayes
Однако как быть, если игра зависит не только от погоды, но и от других условий, например, готовности поля, здоровья игроков и т.п.? В этом случае вывод классификатора можно строить на отношении условных вероятностей следующим образом:

где NBI1 – вывод наивного байесовского классификатора (Naïve Bayes Inference); сi – i-e свойство или признак из F (features), влияющий на вывод классификатора. Отметим, что если P('yes')= P('no'), то первый сомножитель будет равен 1. Это означает, что если априорные вероятности исходов одинаковы, то формула упрощается к виду:
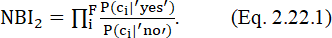
Оценки вероятностей вычисляются следующим образом:
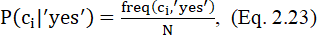
где freq – частота; N – частота всех случаев данного класса. Примером служит выражение P('Sunny'|'yes') = 3 / 9 = 0,33.
В выражении Eq. 2 величина NBI принимает значения от 0 до +∞. Если NBI < 1, то это свидетельствует в пользу отрицательной гипотезы ('no'). Если NBI > 1, то это свидетельство того, что текущее сочетание условий дает возможность положительного вывода ('yes'). Отметим, что если мы используем выражение Eq. 2, то мы должны примириться с неравновесностью такого вывода.
Кроме того, если некоторые признаки встречаются только в сочетании с 'yes' или 'no', то мы можем получить ошибку вывода, когда произведение обращается в ноль либо происходит деление на ноль. Третья проблема связана с тем, что оценки условных вероятностей обычно имеют небольшое значение, и если их много, то итоговое произведение может стать меньше машинного нуля. Эти вычислительные недостатки разрешаются путем сглаживания и использования суммы логарифмов вместо произведения вероятностей. Чаще всего для исключения деления на ноль применяется сглаживание по Лапласу, например, для положительной гипотезы:

В этом выражении F – количество свойств или параметров. В примере ниже F = 2 – параметры: погода (Weather) и состояние поля (Field). В свою очередь, N – частота всех случаев для данного класса, то есть для нашего примера это количество случаев, когда игра состоялась, – 9.
Применение логарифмов позволяет перейти от произведения отношений вероятности к суммам логарифмов этих отношений, так как log(a*b) = log(a) + log(b). Тогда вывод классификатора можно рассчитать следующим образом:

Применение логарифмов позволяет работать с очень небольшими значениями вероятностей. Второе преимущество заключается в том, что при применении логарифмов шкала вывода будет равномерной в диапазоне от -∞ до +∞. Величина NBIlog будет либо больше 0, что означает верность положительной гипотезы, либо меньше 0, что означает справедливость отрицательной гипотезы (рисунок 2.14).
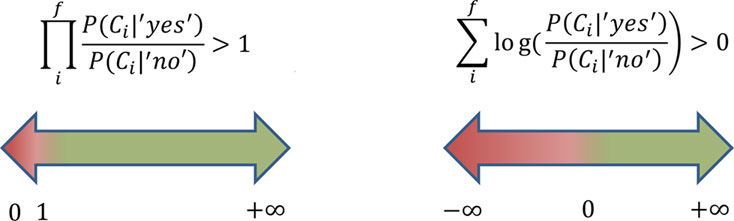
Рисунок 2.14. Шкала вывода алгоритма Naïve Bayes при использовании выражений Eq. 2.21 (слева) и Eq. 2.24 (справа)
Обучение алгоритма Naïve Bayes выполняется просто путем расчета оценок вероятностей (Eq. 2.23, 2.24). После этого вывод обеспечивается по формуле Eq. 2.24.
Рассмотрим пример.
За основу возьмем данные, приведенные в предыдущем параграфе. Добавим еще одно свойство – состояние игрового поля Field. Теперь набор данных содержит два свойства (Weather, Field) и целевую колонку Play:

По-прежнему будем предсказывать возможность игры, но уже не только в зависимости от погоды, но и принимая во внимание состояние поля (bad, good):
(P('yes'|'Sunny' & 'good').
Так же, как и ранее:
P('Sunny'|'yes') = 3 / 9 = 0.33
В дополнение рассчитаем:
P('Sunny'|'no') = 2 / 5 = 0.4
P('good'|'yes') = 5 / 9 = 0.5555
P('good'|'no') = 2 / 5 = 0.4
Результат с использованием выражения Eq. 2.1:
P('yes'|'Sunny' & 'good') = [P('Sunny'|'yes') / P('Sunny'|'no')] * [P('good'|'yes') / P('good'|'no')] = 1.574,
то есть в предположении, что априорная вероятность того, что игра состоится – P('yes'), равна априорной вероятности того, что игра не состоится – P('no'), получаем значение больше 1, и, следовательно, игра состоится.
Примечание. Поэкспериментировать с NBA можно путем решения задач ML_Lab01.2_NaiveBayesSimpleExampleByPython – https://www.dropbox.com/sh/oto9jus54r4qv7x/AAAcOtl9SE-i6b1zViwMP6Wga?dl=0
2.11.3. Положительные и отрицательные свойства Naïve Bayes
Положительные стороны
Классификация, в том числе многоклассовая, выполняется легко и быстро. Когда допущение о независимости выполняется, Naïve Bayes Algorithm (NBA) превосходит другие алгоритмы, такие как логистическая регрессия (logistic regression), и при этом требует меньший объем обучающих данных.
NBA лучше работает с категорийными признаками, чем с непрерывными. Для непрерывных признаков предполагается нормальное распределение, что является достаточно сильным допущением.
Отрицательные стороны
Если в тестовом наборе данных присутствует некоторое значение категорийного признака, которое не встречалось в обучающем наборе данных, тогда модель присвоит нулевую вероятность этому значению и не сможет сделать прогноз. Это явление известно под названием «нулевая частота» (zero frequency). Данную проблему можно решить с помощью сглаживания. Одним из самых простых методов является сглаживание по Лапласу (Laplace smoothing).
Хотя NBA является хорошим классификатором, значения спрогнозированных вероятностей не всегда являются достаточно точными. Поэтому не следует слишком полагаться на результаты, возвращенные методом predict_proba.
Еще одним ограничением NBA является допущение о независимости признаков. В реальности наборы полностью независимых признаков встречаются крайне редко.
Наивный байесовский метод называют наивным из-за допущений, которые он делает о данных. Во-первых, метод предполагает независимость между признаками или свойствами. Во-вторых, он подразумевает, что набор данных сбалансирован, то есть объекты разных классов представлены в наборе данных в одинаковой пропорции. На практике ни первое, ни второе предположения полностью не выполняются: чаще всего признаки связаны между собой, а реальные наборы данных редко бывают сбалансированными. Типичным примером является задача поиска окончания предложения, например: «Очень сухо, солнечно и жарко в Сахаре». Если полагать что мы должны найти последнее слово (Сахара), то его вероятность, исходя из сочетания слов, должна быть выше, чем, например, Магадан. Но с точки зрения независимости слов алгоритм может с равной вероятностью поставить в качестве окончания предложения любой город или место. Другой пример может быть связан с наборами данных о проникновении в закрытую компьютерную сеть. В таких наборах данных примеров зафиксированных проникновений обычно намного меньше, чем стандартных транзакций. Это приводит к тому, что алгоритм становится излишне «оптимистичным» или, наоборот, «пессимистичным».
Еще одно неудобство связано с тем, что если в тестовом наборе присутствует значение признака, которое не встречалось в обучающем наборе, то модель присвоит этому значению нулевую вероятность или нулевую частоту и не сможет сделать прогноз. С этим недостатком борются, применяя сглаживание по Лапласу так, как описано выше.
2.11.4. Приложения наивного байесовского алгоритма
Мультиклассовая классификация в режиме реального времени. NBA очень быстро обучается, поэтому его можно использовать для обработки данных в режиме реального времени. NBА обеспечивает возможность многоклассовой классификации.
Классификация текстов, фильтрация спама, анализ тональности текста, определение авторства, поиск информации, устранение неоднозначности слов. При решении задач автоматической обработки текстов часто используется статистическая модель естественного языка, NBA ей идеально соответствует. Поэтому алгоритм находит широкое применение в задаче идентификации спама в электронных письмах, анализа тональности текста (sentiment analysis), поиска информации, соответствующей запросу (information retrieval), определения авторства текста (author identification), устранения неоднозначности слов (word disambiguation).
Рекомендательные системы. NBA – один из методов, который эффективно применяется в решении задач совместной фильтрации (collaborative filtering) [[62]]. То есть алгоритм позволяет реализовать рекомендательную систему. В рамках такой системы информация о товарах или услугах отфильтровывается на основании спрогнозированного мнения пользователя о ней. Совместная фильтрация подразумевает, что пользователь относится к некоторой типичной группе пользователей, а прогноз вычисляется с учетом большого количества мнений пользователей.
2.12. Композиции алгоритмов машинного обучения. Бустинг
Представим ситуацию, что мы имеем несколько простых алгоритмов классификации, дающих результат лишь немного лучше случайного выбора. Оказывается, что, используя группу из нескольких таких алгоритмов, можно получить хороший результат, строя итоговый алгоритм так, чтобы каждый простой алгоритм, включаемый в группу, компенсировал недостатки предыдущего.
Суть градиентного бустинга, введенного в [[63]], заключается в том, что после расчета оптимальных значений коэффициентов регрессии и получения функции гипотезы hθ(x) с помощью некоторого алгоритма (a) рассчитывается ошибка и подбирается, возможно, с помощью другого алгоритма (b) новая функция hbθ(x) так, чтобы она минимизировала ошибку предыдущего:
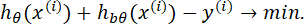
Иными словами, речь идет о минимизации функции стоимости вида:

где L – функция ошибки, учитывающая результаты работы алгоритмов a и b. Для нахождения минимума функции Jb(θ) используется значение градиента функции следующим образом.
Пусть мы имеем некоторую функцию ошибки:
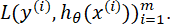
Учитывая, что минимизация функции  достигается в направлении антиградиента функции ошибки, алгоритм (b) настраивается так, что целевым значением является не
достигается в направлении антиградиента функции ошибки, алгоритм (b) настраивается так, что целевым значением является не  , а антиградиент
, а антиградиент 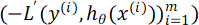 , то есть при обучении алгоритма (b) вместо пар (x(i), y(i)) используются пары (x(i), –L'(y(i), hθ(x(i)). Если Jb(θ) все еще велико, подбирается третий алгоритм (с) и т.д.
, то есть при обучении алгоритма (b) вместо пар (x(i), y(i)) используются пары (x(i), –L'(y(i), hθ(x(i)). Если Jb(θ) все еще велико, подбирается третий алгоритм (с) и т.д.
При этом, как указывается в [[64]], «во многих экспериментах наблюдалось практически неограниченное уменьшение частоты ошибок на независимой тестовой выборке по мере наращивания композиции. Более того, качество на тестовой выборке часто продолжало улучшаться даже после достижения безошибочного распознавания всей обучающей выборки. Это перевернуло существовавшие долгое время представления о том, что для повышения обобщающей способности необходимо ограничивать сложность алгоритмов. На примере бустинга стало понятно, что хорошим качеством могут обладать сколь угодно сложные композиции, если их правильно настраивать».
При решении задач классификации наиболее эффективным считается бустинг над деревьями решений. Одной из самых популярных библиотек, реализующих бустинг над деревьями решений, является XGBoost (Extreme Gradient Boosting). Загрузка библиотеки и создание классификатора выполняются командами:
import xgboost
clf = xgboost.XGBClassifier(nthread=1)
Применим XGBClassifier для решения задачи Fashion-MNIST:
clf = xgboost.XGBClassifier(nthread=4,scale_pos_weight=1)
clf.fit(X_train, y_train)
nthread – количество потоков, которое рекомендуется устанавливать не по количеству процессорных ядер вычислительной системы.
Результат, который получен в этом случае:
Accuracy of XGBClassifier on training set: 0.88
Accuracy of XGBClassifier on test set: 0.86
Важной особенностью является нечувствительность к нормировке данных. То есть если мы будем рассматривать исходные данные изображения в их первозданном виде, исключив операторы:
##X_train1=X_train1/255.0
##X_test1=X_test1/255.0
Мы получим те же самые показатели качества, что и для нормированных данных.
Примечание. При проведении экспериментов с большим набором данных нужно учесть, что алгоритм довольно долго обучается. В частности, при решении задачи Fashion-MNIST время обучения превышает 10 минут. Программу, решающую задачу Fashion-MNIST с помощью XGBoost (MLF_XGBoost_Fashion_MNIST_001), можно загрузить по ссылке https://www.dropbox.com/s/frb01qt3slqkl6q/MLF_XGBoost_Fashion_MNIST_001.html?dl=0