



Сергей Анисимов
Поисковое продвижение сайтов
10. Поиск и устранение дублей
Идентичный (дублированный) контент на разных страницах сайта может привести к ошибкам индексации и даже свести на нет все усилия по продвижению. Чем опасны дубликаты и почему от них стоит избавляться?
Во-первых, на дубли уходит часть статического веса, а неправильное распределение веса ухудшает ранжирование целевых разделов сайта.
✍ На заметку
Статический вес – это один из важных параметров, влияющих на продвижение сайта в целом и конкретной страницы в частности. Вес определяется количеством и качеством ссылающихся на страницу документов (в основном, html-страниц, но учитываются еще pdf и doc-файлы, а также другие распознаваемые поисковиками документы с гиперссылками).
Во-вторых, на дубли тратится часть драгоценного краулингового бюджета. Особенно остро эта проблема стоит для крупных информационных и e<ommerce (онлайн-торговля) проектов.
✍ На заметку
В Интернете триллионы веб-страниц, и каждый день появляются сотни миллионов новых веб-страниц. В этой связи перед поисковыми системами стоит серьезная проблема: как успевать обходить, скачивать и ранжировать все это огромное хозяйство.
Для обхода страниц используются роботы. Поисковый робот («веб-паук», «краулер») – программа, являющаяся составной частью поисковой системы и предназначенная для перебора страниц Интернета и занесения информации о них в базу данных. Очевидно, что каким бы мощным и быстрым не был краулер, скачать единовременно все обновления со всех сайтов у него не получится.
Из-за этого паук скачивает сайты постепенно, небольшими «порциями», например, по нескольку десятков или сотен страниц в день. Размер этой порции на профессиональном сленге специалистов по продвижению и называется краулинговым бюджетом.
По сути, бюджет – это то количество страниц сайта, которое обновится в базе поисковика за определенный период. Чем больше бюджет, тем лучше, так как при большом бюджете можно быть уверенным, что все изменения на сайте быстро попадут в базу данных поисковика.
Краулинговый бюджет зависит от многих факторов (уровня траста, размера сайта, частоты обновления, тематики, региона) и рассчитывается по специальному алгоритму. Самостоятельно увеличить его на нужную величину довольно сложно.
Поэтому при продвижении сайта стоит обратная задача: вместить в имеющийся бюджет все изменения, которые произошли на сайте. Для этого применяется комплекс мер, от удаления дублей до управления индексацией с помощью служебных файлов. Все эти меры мы последовательно рассмотрим на страницах данной книги.
Остается добавить, что получить представление о краулинговом бюджете для продвигаемого сайта можно с помощью статистики, которую предоставляют поисковые системы в панелях для веб-мастеров, или анализа логов сервера.
В-третьих, из-за ошибок в алгоритмах поисковых систем после очередного обновления поискового индекса дубль может заменить в выдаче целевую страницу. Как правило, после этого позиции сайта в выдаче существенно ухудшаются.
Но даже если этого не произойдет, может возникнуть ряд негативных эффектов: например, падение конверсии[26] и накопление поведенческой статистики на неправильной странице. Целевая страница при этом может вообще пропасть из индекса (в самом деле, зачем держать в базе несколько копий одной и той же страницы?).
В-четвертых, может возникнуть ситуация, когда поисковая система не сможет разобраться, какой из дублей следует считать основным. В этом случае алгоритм понизит обе страницы (и сайт в целом) в результатах выдачи.
Причины возникновения дублей и методы их обнаружения
Причины возникновения дублей могут быть разными:
1. Дубли штатно или по ошибке может генерировать движок сайта. Например, дублями могут быть страница и ее версия для печати, встречаются дубли главной страницы (site.ru и site.ru/index.php) или одинаковые страницы с разными расширениями (.php и. html).
2. Дубли могут возникнуть из-за невнимательности вебмастера (после изменения адреса страницы она становится доступна и по старому, и по новому URL).
3. Дубли могут генерироваться из-за дизайнерских или контентных особенностей проекта (в интернет-магазинах часто похожие товары отличаются лишь очень кратким описанием или несколькими техническими параметрами).
Для обнаружения дубликатов есть множество эффективных инструментов:
1. Панели для веб-мастеров поисковых систем[27]. С помощью этих веб-сервисов также можно следить за скачиваемыми страницами и находить дубли.
2. Расширенный поиск в поисковых системах. Для Гугла можно использовать site: имя_хоста[28]. В Яндексе можно смотреть индекс по отдельным разделам с помощью url: имя_хоста/категория/*[29] (для этого же можно использовать оператор inurl).
3. Специальные сервисы и программы. Например, можно воспользоваться программой XENU[30], а также некоторыми распространенными веб-сервисами, информацию о которых легко найти в Сети (см. рис. 2 на с. 54).
Устранение дублей может быть сложным и зачастую требует творческого подхода. Однако есть направления, которые однозначно стоит проверить.
Ошибки движка сайта
Разберем типичные ошибки работы движка сайта, которые приводят к появлению дублей:
1. Движок сайта не генерирует 301 редирект при смене адреса страницы (этот редирект либо нельзя поставить вообще, либо нужно ставить в ручном режиме, о чем легко забыть). Данный недостаток легко устранить на программном уровне.
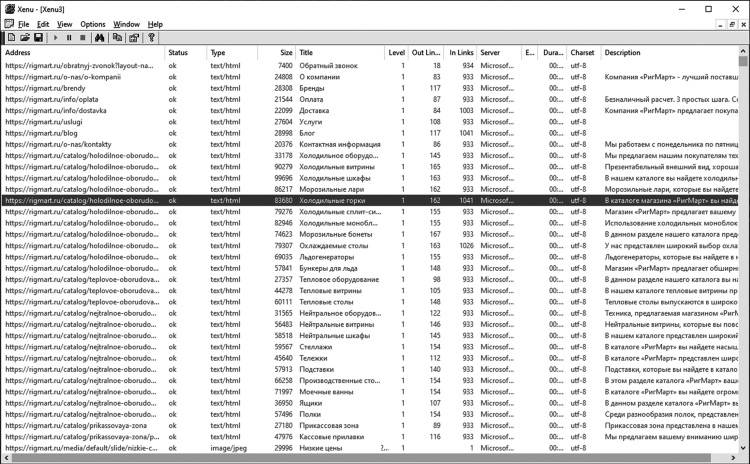
Рис. 2. Результаты сканирования сайта программой XENU: интерфейс безнадежно устарел, но функционал остается полезным при выполнении практических задач
2. Движок отображает один и тот же контент по разным адресам:
a. Разные страницы могут возникать при перестановке частей URL-адреса. Например, одинаковый контент выводится на страницах site.ru/cars/volvo и site.ru/volvo/cars.
b. Отображение страницы происходит при частичном вводе адреса, например по URL site.ru/sumki/cristina-agilera и site.ru/sumki/cristina.
c. Одна и та же страница может отображаться в разных категориях. Особенно это актуально для карточек товаров в интернет-магазине: site.ru/moto/sc-234 и site. ru/moto-s-pricepom/sc-234. Проще всего решить эту проблему, присвоив каждой карточке раз и навсегда свой уникальный адрес.
3. Движок сайта может генерировать сессионные переменные в адресе страниц. Ниже мы разберемся с этим вопросом подробнее.
Сессия – промежуток времени, в течение которого пользователь находился на сайте[31]. Когда пользователь заходит на сайт, последний с помощью cookies[32] браузера его идентифицирует. Это необходимо, чтобы понять, кто этот посетитель, и помочь ему пользоваться сайтом. Например, если при авторизации пользователь поставил галочку «Запомнить меня», то при следующем заходе на сайт он сразу будет залогинен.
Но бывает, что cookies у пользователя отключены. В таком случае возможны три варианта:
– сайт будет работать, как обычно;
– сайт не сможет работать полноценно и выдаст сообщение, что для нормальной работы нужно включить cookies;
– движок сайта постарается компенсировать отсутствие cookies с помощью так называемых сессионных переменных (уникальных идентификаторов, которые будут добавляться к URL тех страниц, на которых побывал пользователь).
Последний подход создает дополнительные проблемы для поисковых систем. Их роботы приходят на сайт, видят новые URL с сессионными переменными и индексируют их. В результате в поисковую базу попадают полные дубликаты уже существующих страниц.
Конечно, поисковые системы отфильтровывают большинство таких страниц, но эта ситуация негативно влияет на индексацию и ранжирование сайта. Если движок сайта генерирует сессионные переменные, необходимо этот механизм отключить.
301 редирект
В основном 301 переадресацию[33] (жарг. «301 редирект») используют при смене URL-страницы, но эта технология пригодится и для борьбы с дублями.
Дело в том, что код статуса 301 означает, что запрашиваемая страница окончательно перемещена в новое местоположение. А поэтому, если настроить 301 редирект с дубля на основной документ, дубль пропадет из поисковой базы.
Необходимо настроить постраничный 301 редирект:
1. C домена без «www» на домен с «www» (или наоборот, в зависимости от того, какой вариант лучше проиндексирован поисковиками, накопленной ссылочной массой и индивидуальных предпочтений).
2. Со страниц без слэша («/») на конце адреса на страницы со слэшем (или наоборот, в зависимости от особенностей сервера и собственных предпочтений). Отметим, что адреса без косой черты на конце предпочтительнее, так как косая черта ассоциируется с каталогом, а не с конечной страницей на сайте.
3. Со страниц, адрес которых оканчивается на «.htm», на страницы вида «.html».
4. С версии сайта «http» на версию «https».
5. С дублей главной страницы сайта (вида «index.php», «index.html», «default.html») на главную. Если такой редирект невозможен из-за особенностей системы, необходимо запретить дубли в файле robots.txt, а также проверить актуальность проблемы для других разделов сайта.
6. После настройки ЧПУ (о чем мы поговорим позже) страницы сайта могут быть доступны и по старым, техническим адресам. Если это так, необходимо настроить 301 редирект на страницы с ЧПУ.
Атрибут rel=«canonical»
Часто на сайте присутствуют группы страниц с частичным дублированием контента. Например, это могут быть карточки товаров, отличающиеся только отдельными параметрами (например, один и тот же стол с разной длиной столешницы), или страницы блога с одной и той же статьей, но разными URL-адресами.
В этом случае необходимо оптимизировать индексацию страниц сайта с использованием вспомогательного атрибута rel=«canonical»[34], с помощью которого можно указать предпочитаемый (канонический) адрес, который будет участвовать в поиске.
Правильно настроенный атрибут rel=«canonical» помогает существенно упростить настройку индексации сайта и устранить дубликаты страниц для корректного учета всех поведенческих и ссылочных метрик документов. Другими словами, поисковые системы «склеят» страницы с частично дублированным контентом вместе со всеми метриками. Особенно это актуально при проведении рекламных кампаний, например, с использованием UTM-меток[35].
Общий план действий:
1. Проанализировать сайт и определить страницы с частично дублированным контентом (страницы с параметрами в URL, дубли одной страницы в разных категориях, похожие товары и прочее).
2. Из группы похожих страниц выбрать каноническую и добавить в код неканонических страниц атрибут rel=«canonical». Желательно, чтобы атрибут ставился программным способом – это существенно облегчит администрирование сайта.
Остается добавить, что из-за несовершенства алгоритмов rel=«canonical» не всегда обрабатывается корректно. Это приводит к отсутствию «склейки» поведенческих и ссылочных факторов ранжирования. Поэтому надежнее использовать 301 редирект везде, где это только возможно.
301 редирект или rel=«canonical»?
Давайте определим, какой способ и когда лучше использовать.
301 редирект лучше:
1. Просто по умолчанию. Это более предпочтительный метод вследствие того, что rel=«canonical» не всегда обрабатывается корректно.
2. Если у страницы навсегда изменился адрес.
3. Если сайт переехал на новый домен.
4. Если администратор сайта удалил какую-то страницу, но вместо 404 ошибки хочет показать пользователям другую, схожую с удаленной, информацию (например, другой товар взамен удаленного).
rel=«canonical» лучше:
1. Когда 301 редирект не может быть реализован или его внедрение потребует слишком больших затрат.
2. Когда имеет смысл показывать частично дублированный контент пользователям. Например, несколько страниц стола с разной длиной столешницы можно показывать в расчете на более высокую конверсию, особенно если на эти страницы ведут специальные объявления из систем контекстной рекламы.
3. Когда нужно показывать страницы с почти одинаковым содержимым (например, сортировки каталога, отслеживания партнерских ссылок).
4. Для кросс-доменов, когда оба сайта похожи, но похожий контент нужно оставить на каждом из доменов. Эта ситуация может быть опасна из-за аффилирования, о чем мы поговорим в разделе, посвященном санкциям поисковых систем.
Ошибки при использовании редиректов
Закрывая тему редиректов, хочется рассказать об ошибках, которых стоит избегать:
1. Необходимо делать правильный выбор между 301 редиректом и rel=«canonical».
2. Нужно избегать любых многошаговых редиректов. Одношаговый редирект быстрее работает и сохраняет максимум ссылочного веса. Кроме того, если на сайте будут замечены многошаговые редиректы, поисковая система может решить, что ваша страница – дорвей. А это повлечет серьезнейшие санкции для сайта.
✍ На заметку
Дорвей[36] (от англ. doorway – входная дверь, портал) или входная страница, – один из видов поискового спама. Это веб-страница, специально оптимизированная под один или несколько поисковых запросов с целью ее проникновения на высокие места в результатах поиска и дальнейшего перенаправления посетителей на другой сайт или страницу.
Дорвей не представляет никакой ценности, и пользователь даже не успевает его рассмотреть – его сразу перенаправляют на другой сайт. Контент дорвея, как правило, лишен смысла и генерируется автоматически по специальным алгоритмам (писать руками слишком затратно). Часто это просто набор фраз, в который внедрены ключевые слова.
Дорвеи – это веб-мусор, поэтому все поисковые машины беспощадно с ними борются.
3. Нужно применять правильные виды редиректов[37], чтобы не запутать поискового робота.
4. При внедрении редиректа необходимо позаботиться о том, чтобы на сайте не осталось ссылок со старым URL-адресом (с которого и выполняется перенаправление).
5. Редирект желательно ставить на максимально релевантную страницу. Например, на похожую карточку товара или ветку каталога, к которому принадлежала страница. Если это невозможно, лучше выдавать 404 ошибку, о которой мы поговорим чуть позже.
6. Редирект должен вести на действующую страницу (с кодом ответа 200 ОК). Иначе нужно вернуть 404 ошибку.
Robots.txt
Robots.txt – это специальный служебный файл, расположенный в корневом каталоге сайта[38], который является незаменимым помощником в борьбе с дублями и нецелевыми страницами, попавшими в индекс. Следует обязательно создать этот файл в соответствии с рекомендациями поисковых систем[39], а затем указать в нем страницы и данные, которые поисковым роботам не следует индексировать.
Перечислим типичные разделы и страницы с дублированным контентом, индексацию которых стоит запретить в файле robots.txt:
– страницы фильтраций и сортировок с дублированным контентом;
– страницы с UTM-метками;
– результаты поиска;
– тестовые страницы, поддомены и серверы;
– RSS-фиды.
В файл также следует добавить разделы с малоинформативным и служебным контентом:
– служебные страницы и файлы, логи сайта, страницы с внутренней статистикой, вход в административную панель, кэш страниц, подгружаемые модули и другие технические страницы;
– страницы авторизации, смены и напоминания пароля;
– «висячие узлы», то есть страницы, с которых нет ссылок на другие страницы сайта (например, версия страницы для печати);
– страницы совершения действия (добавления в корзину, оформления заказа и прочее);
– страницы с динамическими параметрами[40];
– неинформативные или пустые doc- и pdf-файлы (такие файлы лучше не просто закрывать от индексации, а удалять с сайта). При этом надо помнить, что, если такие файлы уникальны и несут полезную информацию, их не закрывают от индексации.
Приведенные списки не являются исчерпывающими. Каждый движок имеет свои особенности, поэтому желательно делать регулярную проверку, выявлять дубли и «мусорные» страницы и запрещать их к индексации.
Надо отметить, что запрещение индексации разделов через файл robots.txt без скрытия ссылок на них может приводить к тому, что эти разделы все же попадут в индекс со всеми вытекающими последствиями.
Про robots.txt профессионалы даже шутят, что он как презерватив: вроде бы защищает, но гарантий никаких.
Поэтому желательно просто убирать ссылки на нежелательные разделы из клиентской части сайта: так вы надежно скроете их и от поисковых роботов, и от пользователей.
В файле robots.txt следует указать ссылку на карту сайта с помощью директивы Sitemap[41].
Остается добавить, что для анализа корректности файла robots.txt нужно воспользоваться валидаторами поисковых систем[42].
11. Оптимизация заголовков
При оптимизации заголовков встречается много ошибок. Давайте разберем типичные недостатки и поймем, как их избежать.
Заголовок hl
Согласно многим исследованиям, заголовок h1[43] зачастую работает как «второй тайтл», поэтому к нему нужно относиться максимально внимательно:
1. Заголовок h1 единожды должен присутствовать на каждой странице сайта. Повторное использование тегов заголовка h1 на странице недопустимо.
2. Заголовок должен «перекликаться» с тегом <title>, допускается частичное или даже полное дублирование.
3. Заголовок должен однозначно визуально идентифицироваться на странице, чтобы пользователь сразу понимал содержание текущего раздела. Добиться выделения заголовка можно с помощью размера букв, шрифта, цвета и других приемов.
4. В теле заголовка желательно использовать ключевые слова, но переоптимизация (чрезмерное употребление) недопустима.
Рис. 3. Сайт htmlbook.ru – полезный справочник для любого вебспециалиста
Теги h2-h6
Перечислим основные рекомендации, которые помогут правильно применять второстепенные заголовки:
1. Заголовки пришли в Интернет со страниц газетных полос и по возможности должны следовать газетной традиции визуального оформления: h1 должен быть самым крупным и заметным, h2 – меньше, h3 – еще мельче. Так пользователь сможет легче понять иерархию текста на странице.
2. Оптимально использовать только теги h1-h3. Теги h4-h6 почти бесполезны для поискового продвижения, а их использование свидетельствует о проблемах с текстом на странице: он слишком подробно поделен на отдельные части и его необходимо сделать более однородным. Для больших информационных порталов (словарей, справочников и т. п.) допускается также использование h4. Теги h5-h6 лучше не использовать никогда.
3. Ключевые слова в заголовках h2 и h3 могут быть слабым сигналом релевантности, поэтому этим надо пользоваться. Нужно размещать ключевые слова в этих элементах, но не во всех, так как это может быть признаком текстовой переоптимизации, за которую поисковые системы наложат на страницу санкции.
Типичные ошибки
Перечислим типичные ошибки, которых следует избегать:
1. Тегами заголовков можно выделять только заголовки в контентной (текстовой) части страницы. Другие варианты их применения в верстке недопустимы.
Для оформления контента вне основной области страницы (шапка, левая/правая колонка, подвал сайта) можно создать и использовать специальные css-классы.
2. По возможности нужно стараться делать код заголовков более «чистым», без дополнительных тегов и классов. Идеально: <й1>Текст заголовка< /h1>. Это не влияет на продвижение сайта, но поможет придерживаться единого стиля заголовков на всем сайте.
3. Не следует перебарщивать с количеством подзаголовков h2 и h3 на странице. Их количество должно быть адекватно количеству текста (в среднем – один подзаголовок на 800-1500 символов).
Помимо технических задач, связанных с продвижением, заголовки играют большую роль в удержании пользователей и повышении конверсии. Эти аспекты мы подробно разберем в соответствующих разделах.
12. Настройка адресации
Правильная адресация помогает пользователям ориентироваться на сайте и способствует повышению позиций сайта в поисковой выдаче. Ее необходимо оптимизировать на самом раннем этапе работ, иначе можно потерять часть уже достигнутых при продвижении результатов.
ЧПУ
Как известно, к сайту можно обратиться по его URL[44]. URL (англ. Uniform Resource Locator, «урл») – это единый указатель (адрес) ресурса. URL служит стандартизированным способом записи адреса ресурса в Интернете.
Все без исключения страницы сайта должны иметь человеко-понятный урл (ЧПУ). Так на профессиональном жаргоне называют веб-адрес, содержащий читаемые слова вместо служебных параметров, более удобных для компьютера, чем для людей (например, числовых идентификаторов страницы).
Такой адрес состоит из букв латинского (английского) алфавита, цифр и знака «-» (дефиса), который используется для отделения слов друг от друга вместо пробела. ЧПУ отражает виртуальную иерархическую структуру сайта (физически такая структура папок и файлов на сервере может и не существовать). Пример такого адреса: http://site.ru/katalog/igrushki/kubik-rubika
В Гугле такие адреса называют простыми[45]. И действительно, чтобы добиться такой адресации, структуру сайта нужно делать предельно простой, логичной и понятной. Это поможет пользователям просматривать сайт, а роботам – правильно его индексировать.
ЧПУ должен дублировать структуру сайта. Вот примеры того, как он должен выглядеть для разных разделов:
– [главная страница]
– [главная страница] + [раздел]
– [главная страница] + [раздел] + [подраздел]
– [главная страница] + [раздел] + [подраздел] + [страница]
Приведем простой алгоритм образования URL-адреса из заголовка страницы. Это оптимальный способ автоматического формирования ЧПУ, но важно соблюдать последовательность действий:
1. Преобразовать строку заголовка страницы в нижний регистр.
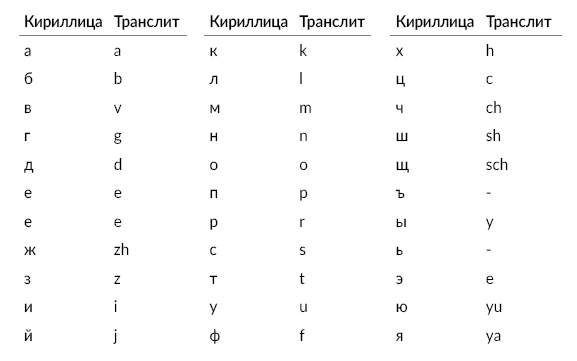
2. Заменить символы кириллицы согласно таблице ниже.
1. Все символы, кроме допустимых (знака тире, букв и цифр), заменить на «-» (включая пробел). Регулярное выражение для замены [^-a-zQ-9].
2. Заменить несколько идущих подряд «-» на один «-».
3. Проверить и удалить, в случае необходимости, символ «-» на первой и последней позиции в строке.
4. К полученному результату слева присоединить косую черту и ЧПУ раздела, находящегося на один уровень выше текущего. Понятно, что самым верхним уровнем будет домен сайта.
Для проверки качества ЧПУ можно провести простой тест: дать контрольной группе пользователей только URL-адрес нескольких разделов сайта и попросить описать, чему посвящены эти страницы. Если у них возникнут проблемы – стоит внести коррективы.
Важные замечания
Спам. ЧПУ не должен быть заспамлен, то есть в нем не должно быть слишком много ключевых слов (тем более они не должны повторяться!). Если ЧПУ формируется из заголовка, то сначала необходимо оптимизировать заголовки согласно ранее данным рекомендациям.
Длина. URL-адрес должен быть коротким. Хорошим тоном считается удерживать длину адреса в пределах 150–200 символов. Это удобно для пользователей и радует поисковых роботов.
Ключевые слова. В адресе обязательно нужно использовать ключевые слова. Это не только поможет пользователям лучше понимать структуру адресов сайта, но и может улучшить кликабельность на странице поисковой выдачи, так как ключевые слова там выделяются жирным шрифтом.
Подразделы вместо поддоменов. Без крайней необходимости не стоит выносить контент за пределы основного домена сайта (на поддомены).
В общем случае домен и его поддомен поисковыми системами воспринимаются как два разных сайта. Соответственно, если весь контент агрегируется на основном домене, можно получить синергетический эффект при продвижении за счет роста размера сайта, ссылочной массы и поведенческой статистики. Если вынести часть контента на поддомены, в общем случае вместо одного «сильного» сайта получится несколько «слабых», которые даже в совокупности будут генерировать гораздо меньше трафика.
Нижний регистр. Все URL должны быть в нижнем регистре. Если на сайте использовался верхний регистр, нужно настроить 301 редирект на страницы в нижнем регистре.