



Сергей Анатольевич Жуматий
Cуперкомпьютеры: администрирование
Что скрыто от пользователя
Всё, что мы описали выше, – это то, что видно рядовому пользователю. Однако есть и то, что остаётся для него «за кадром», но играет важную роль для администратора. Это те сервисы, которые обеспечивают корректную работу суперкомпьютера: управление учётными записями, распределённой файловой системой, квотами, сервисы удалённого мониторинга узлов, сбора статистики и журналирования, мониторинга оборудования и инфраструктуры, экстренного оповещения и отключения, резервного копирования. Все эти сервисы работают незаметно для пользователя, но их важность трудно переоценить.
Краткое резюме
Собрать простейший вычислительный кластер можно и «на коленке»: взять два ноутбука, подключить в общую сеть, настроить беспарольный доступ по ssh, на одном из них запустить NFS-сервер, а на другом примонтировать по NFS файловую систему, и – готово, можно запускать MPI-программы. Но производительность такого кластера весьма невелика, а при попытке подключить вместо двух ноутбуков двадцать возникают проблемы: сеть не справляется с нагрузкой, NFS тормозит, один ноутбук завис, и мы полчаса выясняем, что же случилось, и многое другое. Увы, если кластер не «игрушечный», а предназначен для реальных задач, то подходить к его построению и эксплуатации надо серьёзно. Мы кратко обозначили основные компоненты программного «стека» суперкомпьютера, далее попробуем рассмотреть их подробнее.
Ключевые слова
MPI, сеанс работы, ssh-клиент, NFS.
Глава 4. UNIX и Linux – основы
Если вы уже используете Linux и имеете неплохое представление о его администрировании, то смело пропустите эту главу. Если информация из неё будет для вас совсем новой, то для дальнейшего чтения желательно почитать дополнительную литературу, потренироваться в написании скриптов на bash.
В любом случае мы рекомендуем ознакомиться с книгами из списка ниже, в них есть масса информации, полезной даже опытным профессионалам:
Эви Немет, Гарт Снайдер, Трент Хейн, Бэн Уэйли
Unix и Linux: руководство системного администратора
Это классический учебник по Unix и Linux. В нём нередко случаются отсылки к таким древним системам, как VAX и PDP-11, тем не менее он отлично отражает суть работы UNIX и остаётся актуальным по сей день.
Томас Лимончелли, Кристина Хоган, Страта Чейлап
Системное и сетевое администрирование. Практическое руководство
Более новый учебник по Linux, содержит массу полезных примеров.
Брайан Керниган, Роб Пайк
Unix – Программное окружение
Эта книга в большей степени посвящена программированию как в оболочке bash, так и с помощью иных инструментов. Даже если вам не приходится регулярно этим заниматься, настоятельно советую прочесть эту книгу, так как она откроет вам те принципы, по которым строится работа в UNIX, вам станут более понятны многие процессы, происходящие внутри ОС.
Томас Лимончелли
Тайм-менеджмент для системных администраторов
Название говорит само за себя. В книге есть множество ситуаций, в которые попадает любой системный администратор, и практические советы, как из них выходить с минимальными потерями.
Эта глава не претендует на статус учебника по UNIX, но мы постарались собрать в ней все основные понятия, знание которых в дальнейшем вам обязательно потребуется. На сегодняшний день на суперкомпьютерах в подавляющем большинстве случаев используется UNIX-подобная операционная система. Мы говорим UNIX-подобная, так как легендарная ОС UNIX в чистом виде сейчас не развивается и практически не используется.
Краткая историческая справка. После разделения компании AT&T, которая и разработала эту ОС, товарный знак UNIX и права на оригинальный исходный код неоднократно меняли владельцев, в частности, длительное время они принадлежали компании Novell. В 1993 г. Novell передала права на товарный знак и на сертификацию программного обеспечения на соответствие этому знаку консорциуму X/Open, который затем объединился с Open Software Foundation и сейчас называется «The Open Group». Этот консорциум занимается разработкой открытых стандартов для ОС, таких как POSIX (сейчас он переименован в Single UNIX Specification).
Согласно положению «The Open Group», название «UNIX» могут носить только системы, прошедшие сертификацию на соответствие Single UNIX Specification. В настоящее время несколько ОС прошли разные версии этой сертификации, например Solaris, AIX.
Даже те ОС, которые не проходили сертификации UNIX (например Linux), стараются соответствовать этим стандартам. Именно поэтому архитектура приложений на этих ОС очень похожа, а перенос приложения с одной ОС на другую прост, особенно если при написании программы использовались только стандартные библиотеки и функции. Именно эти качества и огромная популярность UNIX в прошлом, а также отлично зарекомендовавшие себя её наследники – Solaris, OpenBSD, FreeBSD, AIX и, конечно же, Linux – обеспечили UNIX-подобным ОС лидерство на серверах всего мира.
Вычислительные кластеры и суперкомпьютеры не исключение. Здесь стандартом de facto является Linux. Именно на эту операционную систему мы и будем ориентироваться. Несмотря на то что существует немало установок на других операционных системах, таких как Windows, FreeBSD, Solaris и других, в данной книге мы не будем останавливаться на их особенностях в классе HPC.
Процессы
Основное понятие в любой ОС – процесс. Это нечто типа контейнера (реально – описания в таблицах ОС), содержащего уникальный идентификатор (PID), права (владелец, группа и некоторые другие), код программы, область данных, стек, набор страниц памяти, таблицу открытых файлов и прочие атрибуты. Для ОС процесс – единица планирования процессорного времени, каждый процесс может исполняться процессором, быть в ожидании исполнения, быть в состоянии системного вызова (передать запрос к ОС и ждать ответ), быть остановленным или завершившимся. Обозначаются они как R (running), S (sleeping), D (uninterruptable sleep), T (stopped) и Z (zombie).
Например, если запустить на компьютере с 2 ядрами 10 программ расчёта числа пи, то одновременно смогут считаться только 2, но ОС будет с большой частотой (например 100 раз в секунду) приостанавливать выполнение активного процесса, помещать его в очередь и отправлять на выполнение следующий процесс из очереди (очень грубо, но суть именно такая). Для процесса это выглядит как будто он монопольно владеет процессором, просто скорость этого процессора раз в 5 ниже, чем могла бы.
Среднее число процессов в очереди обозначается как «уровень загрузки» – Load Average. Если он больше числа ядер, то обычно это значит, что не всем задачам «достаётся» процессор, и они работают медленнее. Надо учесть что в очередь включаются и процессы в состоянии D, то есть высокий LA могут вызвать процессы, которые, например, много читают с диска или пишут (и постоянно ждут в вызове read или write). То есть высокий LA – это сигнал, что потенциально что-то не так, но хорошо бы проверить.
В состояние stopped процесс переводится, только если другой процесс послал ему сигнал STOP. В этом случае он «замирает» и перестаёт исполняться до тех пор, пока не получит сигнал CONT (или не будет завершён). Если процесс в состоянии D, то сигнал игнорируется. В принципе, сигнал STOP процесс может игнорировать, но так делается очень редко.
Состояние zombie возникает, когда процесс завершился, но его родитель «не подтвердил» это (не вызвал системный вызов wait). Это делается для того, чтобы родительский процесс мог получить данные о том, как завершился процесс. т. е. процессы в состоянии zombie уже не потребляют никаких ресурсов ни процессора, ни памяти. По этой же причине их нельзя принудительно завершить – они уже завершены.
Родительский процесс (PPID) есть у каждого процесса в системе, если родительский процесс завершился, то им становится процесс с PID 1 (обычно это специальный процесс init в системе, мы про него поговорим ниже), который выполняет wait для всех таких процессов.
Посмотреть список процессов и их состояние можно с помощью команды ps. У неё нелёгкая судьба, т. к. в разных вариантах популярных ОС (Unix, BSD, Solaris) исторически у неё было много разных, в том числе конфликтующих опций. В результате в Linux используется вариант GNU, который пытается их сочетать. В частности, есть опции, которые обязательно надо указывать с минусом впереди, а другие – наоборот только без минуса. Ниже самые полезные с нашей точки зрения:

К большинству комбинаций можно добавить w, тогда поле имени процесса (обычно программа с аргументами) будет шире. Если добавить дважды, то будет ещё шире, а если трижды, то ограничений на ширину не будет совсем.
Бывает удобно отслеживать активность процессов в реальном времени. Тут помогут команды top и более новомодная htop. Они показывают процессы в виде таблицы, отсортированной по одному полю, и обновляют её раз в 5 секунд (можно поменять интервал). При этом показываются только те процессы, которые поместились на экране, плюс некоторые общие данные о системе – загрузка процессора, памяти, loadaverage, число процессов в разных состояниях.
Можно переключать режимы отображения и сортировки. Для top есть несколько горячих клавиш, их список можно получить, нажав 'h'. Наиболее удобные варианты сортировки и команды:
<Shift>+<P> – сортировать процессы по использованию процессора;
<Shift>+<M> – сортировать процессы по использованию памяти;
1 – показывать загрузку каждого ядра или суммарную;
k – послать сигнал процессу;
r – изменить приоритет процесса;
u – фильтровать по пользователю;
q – выход.
У htop более дружественный интерфейс, по возможности она использует цветной вывод, загрузку процессора и памяти выводит в виде текстовых прогресс-баров, умеет организовывать процессы в деревья (и схлопывать их с одну строку, что иногда очень удобно). Клавиши управления выведены в нижней строке в стиле Norton Commander (Midnight Commander/FAR manager).
Мы уже не раз упомянули сигналы – это простой способ общения процессов, любой процесс может послать другому сигнал, если он принадлежит тому же пользователю (пользователь root может посылать всем). Сигнал – целое число, так что много информации им не передать, но его функция – попросить процесс выполнить какое-то действие. Все сигналы, кроме KILL, могут быть перехвачены и обработаны, если процесс не обрабатывает сигнал, то ОС выполняет заранее определённое действие за него.
Для большинства сигналов есть стандартные значения и действия, ниже – самые часто используемые:
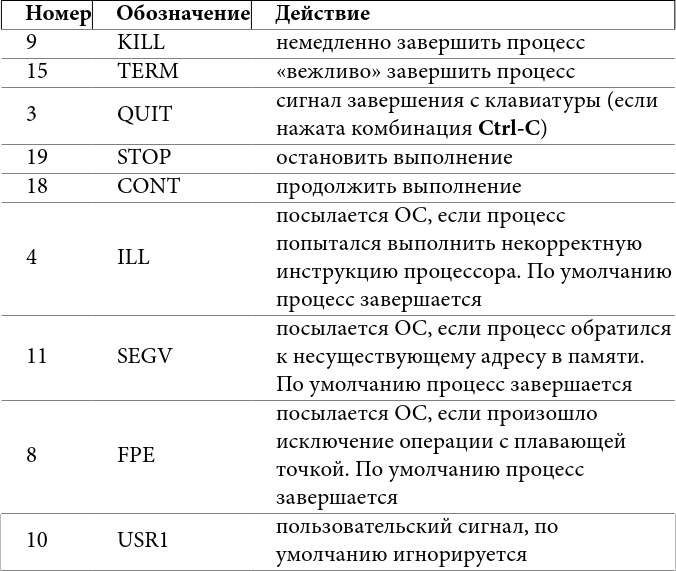
Таблица 3: некоторые сигналы в Linux
Действия «по умолчанию» процесс может изменять (кроме сигнала KILL). Их можно обработать или игнорировать. При корректном завершении память процесса может быть записана в т. н. core-файл для того, чтобы после можно было исследовать причину ошибки отладчиком. Будет ли создан core-файл, определяется настройками ОС и лимитами (см. главу о квотах).
Послать сигнал из командной строки можно командой kill. Например, kill -9 1234 принудительно завершит процесс 1234, а kill -STOP 2345 остановит процесс 2345. Как видно, можно использовать как номер сигнала, так и его обозначение. kill -l покажет список всех сигналов. Иногда требуется послать сигнал не одному процессу, а многим, например всем процессам пользователя. Тогда на помощь приходит программа pkill: pkill -u vasya -TERM пошлёт сигнал TERM всем процессам пользователя vasya.
Выше мы говорили о том, что процессы, желающие выполняться, ставятся в очередь. В ней они выполняются не всегда подряд, у каждого есть приоритет и влияющий на него параметр nice (вежливость). Чем выше приоритет, тем быстрее процесс продвигается к началу очереди. Явно задать приоритет нельзя, но можно поменять вежливость (часто её тоже называют приоритетом для простоты, но это не совсем так). Делается это командой nice или renice, первая запускает программу с заданным приоритетом, вторая меняет приоритет уже запущенной. Чем выше вежливость, тем ниже приоритет, программа чаще будет «пропускать» других вперёд. Исторически вежливость меняется от 20 до +20, и обычный пользователь не может указать её меньше 0. Например:
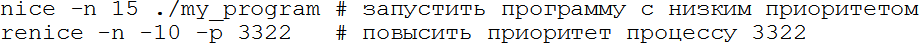
Здесь мы меняем вежливость с 0 до 15 (приоритет понижается) или до -10 (приоритет повышается).
Кроме очереди на ресурсы процессора есть очередь к ресурсам жёстких дисков, несколько процессов могут одновременно читать-писать, и их запросы будут конкурировать. В этой очереди тоже есть приоритет, им управляет команда ionice. Есть три класса приоритетов – idle (выполнять запрос, если больше никого в очереди нет), best effort (нормальная очередь) и real time (запрос должен быть выполнен за заданное время). Внутри классов, кроме idle, есть собственные приоритеты, но в наших задачах можно ограничиться назначением класса idle процессу, занимающему много времени на дисковых операциях, но не приоритетному:
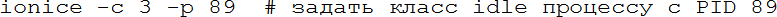
Понятие процесса – основное в любой ОС. Не следует путать процессы и нити, важно знать, что такое реальная и виртуальная память процесса, как работают разделяемые библиотеки (shared objects, so) и динамический линкер (ld.so). Изучите документацию на эту тему в дистрибутиве своей ОС или в обширной документации в Интернете.
Права
Unix-подобные ОС изначально проектировались как многопользовательские системы, а значит, нужно защитить данные и процессы пользователей от нежелательных посягательств других пользователей. Чуть выше мы уже упомянули права процесса и отметили, что, например, нельзя послать сигнал процессу другого пользователя (если нет особых прав на это). Подобный принцип применяется и для разделения прав на прочие объекты в ОС.
Базовый механизм разделения прав в UNIX-подобных системах основан на понятиях UID, или User ID (идентификатор пользователя) и GID, или Group ID (идентификатор группы, которой принадлежит пользователь). UID и GID – числа, но обычно с ними связывают текстовые имена. Каждый процесс имеет «реальные» UID и GID (ruid/rgid), которые не меняются со временем, а также список дополнительных групп, в которые он входит. Кроме реальных, процесс имеет «эффективные» UID и GID (euid/egid), которые определяют его текущие возможности (т. е. именно по ним определяются его права), а также «сохранённые» UID и GID (suid/sgid) – в них копируются эффективные UID/GID при смене UID/GID. Смена UID/GID может происходить, если у процесса есть такое разрешение (capability) или его EUID либо SUID равен 0.
Пользователь с UID = 0 обычно имеет текстовое имя 'root' и имеет почти неограниченные права, поэтому часто его называют «суперпользователь».
Чаще всего, наверное, приходится сталкиваться с правами на файловой системе. Здесь каждый объект (файл, ссылка, каталог, устройство, сокет, канал, далее будем для краткости писать «файл») имеет владельца и группу, а также связанные с ними права – чтение, запись и исполнение. Часто для их записи используют восьмеричную запись или формат команды ls. Например, права с восьмеричным кодом 750 (в выдаче ls rwxr-x–) обозначают, что владельцу разрешено чтение, запись и исполнение (rwx / 7), группе – чтение и исполнение (r-x / 5), остальным – ничего (-– / 0).
Проверка прав производится в таком порядке – если владелец файла совпадает с EUID, берутся права владельца. Иначе, если группа или одна из дополнительных групп совпадают с группой файла, то берутся права группы, и в противном случае – права «остальные».
Для каталога право на «исполнение» означает возможность войти в каталог. При этом посмотреть список файлов в нём не гарантируется – для этого нужно право на чтение. Право на запись означает возможность создавать и удалять файлы в каталоге. Сменить права на файл (или другой объект) может только его владелец. Если нужно сменить права для группы, то владелец должен в неё входить. Ну и конечно, суперпользователь может менять любые права, а также владельца и группу любого файла.
Как уже было сказано, право записи в каталог позволяет создавать и удалять в нём файлы. В том числе чужие. Чтобы обеспечить комфорт работы с общими каталогами, например /tmp, и не позволять удаление чужих файлов, был придуман дополнительный «липкий» флаг (sticky). Если каталог обладает им, то удаление файлов разрешается только тем, кто владеет файлом и имеет право записи в каталог (и root-у, конечно).
Раз уж мы коснулись файловой системы, то стоит отметить ещё два флага – suid и sgid. Если файл имеет флаг suid, то при его запуске EUID процесса сменится на владельца файла. Для sgid – аналогично, но для группы. Чаще всего он ставится на файлы, исполнение которых необходимо с правами суперпользователя, например passwd. Для скриптов они не работают. Если флаг sgid устанавливается на каталог, то созданные в нём файлы и каталоги автоматически наследуют группу. Флаг suid на каталогах игнорируется.
Как уже упоминалось выше, посмотреть права можно командой ls. В строке прав первым символом показывается тип файла ('-' = файл, 'd' = каталог, 'l' = ссылка, 's' = сокет и т. п.), далее три группы прав владельца, группы и остальных по три символа 'r/-', 'w/-' 'x/-' для чтения, записи и исполнения соответственно ('-' означает отсутствие прав). Флаг sticky обозначается символом 't' вместо 'x' в группе «остальные». флаги suid/sgid – символом 's' вместо 'x' в группе «владелец» или «группа» соответственно. Если за этой строчкой идёт символ '+', это значит, что на этот файл установлены acl (см. ниже).
Менять права на файл можно командой chmod. Сменить владельца файла – командой chown, группу – chgrp. Для того, чтобы сменить права на файл, команде chmod нужно указать новые в восьмеричном виде или в символьном. Последний вариант позволяет добавить или удалить отдельные права для владельца, группы или остальных, например:
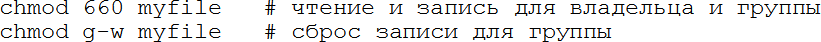
В символьном виде для chmod указывается один или более символов 'u/g/o/a' (владелец, группа, остальные, все три группы вместе), затем символ '+' или '-' для установки или сброса прав, и затем один или более символов 'r/w/x' – какие права затрагиваются. Например, chmod go+rx myfile добавит права на чтение и исполнение для группы и остальных файлу myfile.
Описанная выше система покрывает множество потребностей, но не все. В попытках улучшить её были созданы различные расширения, реализованные в файловых системах Linux. Одно из них – расширенные атрибуты файлов. Они включены по умолчанию, и их можно смотреть и изменять командами lsattr и chattr. Самые важные для нас:
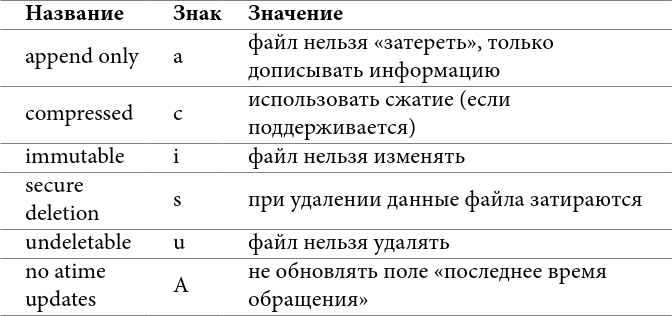
Таблица 4: некоторые расширенные атрибуты
Если расширенный атрибут запрещает какое-то действие (например удаление), то это распространяется даже на суперпользователя (в отличие от обычных атрибутов). Но суперпользователь может легко снять или установить любой из них.
Другое расширение, как правило требующее активации на файловой системе, – ACL (Access Control List), списки контроля доступа. Посмотреть и изменить их можно командами getfacl и setfacl. Они работают аналогично традиционным правам доступа, рассмотренным выше, однако права на чтение/запись/исполнение теперь можно устанавливать отдельным пользователям и/или группам, а также ограничивать эти права маской. Маска – набор «максимальных» прав из правил acl (традиционные к ним не относятся), которые будут работать. Например, разрешим пользователю vasya чтение файла и запись в файл test.txt:

Здесь ключ '-m' указывает модифицировать правила acl. Указав ключ '--set', можно заменить правила, т. е. удалить старые и заменить новыми (в setfacl можно указать несколько правил одновременно). Ключом '-x' правила можно удалять. Строка 'u:vasya;rw' указывает на то, что правило относится к пользователю (u = user, g = group, o = others), его и<я vasya, и устанавливаются права на чтение и запись. Теперь установим маску – разрешим пользователю vasya (и другим, имеющим доступ через правила acl) «не более чем» чтение:
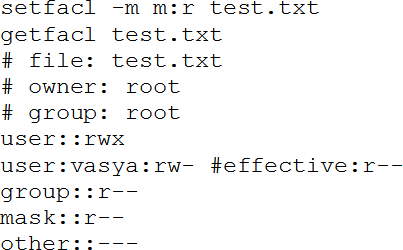
Как видим, правило осталось, но права на запись ограничены маской.
Ещё одно полезное свойство acl – наследование правил. На каталог можно установить acl «по умолчанию», они могут не совпадать с acl на сам каталог, и они будут автоматически применяться ко всем создаваемым файлам и каталогам.
Советуем подробнее прочесть о правах в Linux и опциях вышеупомянутых команд, тут мы их коснулись совсем немного.
Понятие сервиса, ключевые сервисы
Выше мы уже не раз использовали термины «сервис», «демон», «служба». Все они обозначают одно и то же: процесс или группу процессов, которые работают постоянно или автоматически запускаются по запросу. Их задача – обслуживать определённые запросы от пользователей, других процессов, других компьютеров в сети. Например, web-сервер apache – сервис, обслуживающий запросы по http-протоколу. SMTP-сервер отвечает за запросы на передачу почтовых сообщений и т. д. Рассмотрим сервисы, часто используемые в суперкомпьютерах. О некоторых из них мы уже говорили выше и здесь только перечислим их.
Некоторые сервисы запускаются через «супердемон» inetd или более новую его реализацию – xinetd. В этом случае в конфигурационном файле inetd/xinetd описываются необходимые сервисы: команда запуска, на каком порту слушать, от имени какого пользователя запускать и т. п. После запуска inetd/xinetd начинает слушать на указанных портах и при получении запроса запускает соответствующую команду, которой на стандартный поток ввода направляется установленное сетевое соединение. Такой принцип облегчает написание сервиса, а также позволяет более гибко настраивать политику доступа к нему. Например, xinetd позволяет задать диапазон адресов, с которых разрешён доступ, максимальное число одновременных запросов к сервису и т. п.
Чтобы узнать, работает ли конкретный сервис, можно проверить, запущен ли соответствующий процесс (за исключением сервисов, запускаемых через inetd/xinetd), слушает ли какой-либо процесс нужный порт (если сервис привязан к порту) командой netstat -lpn.
Основные (но не все) сервисы для кластера:
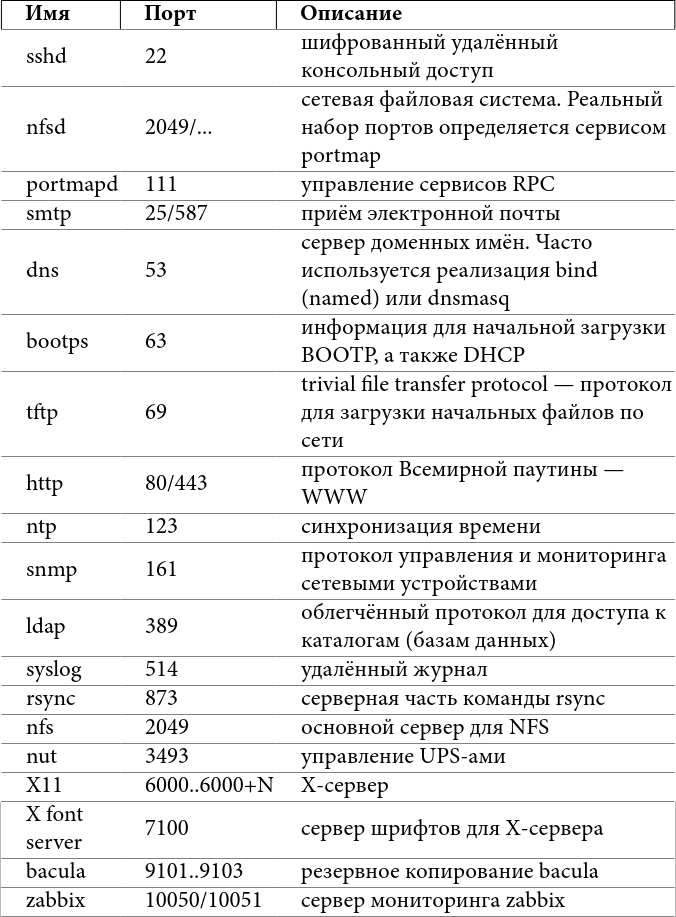
Таблица 5: некоторые стандартные сервисы и их порты
Более полный список можно найти в файле /etc/services – он содержит соответствие номера порта традиционно используемому сервису. Некоторые сервисы в нём не представлены ввиду не очень широкого распространения, и, конечно, ничто не мешает запустить какой-либо сервис на нестандартном порту, не забывайте об этом. Через супердемон inetd/xinetd часто запускаются такие сервисы, как tftp, echo, ftp.