



Сергей Анатольевич Жуматий
Cуперкомпьютеры: администрирование
Хранение данных
В каждый узел – управляющий, вычислительный или служебный – могут быть установлены локальные жёсткие диски. Наряду с этим возможно подключение внешних дисковых подсистем, доступ к которым будет производиться со всех узлов одновременно.
Локальные жёсткие диски могут использоваться для загрузки операционной системы, как виртуальная память (область подкачки) и для хранения временных данных. Конечно, вычислительные узлы могут и не иметь локальных дисков, если загрузка операционной системы на них организована через сеть, хотя даже в этом случае локальный диск полезен для области подкачки и хранения временных данных. На управляющем узле локальные жёсткие диски обычно устанавливаются, а сетевая загрузка при этом не предусматривается.
На внешних системах хранения данных (далее – СХД) обычно располагаются программные пакеты и утилиты, запуск которых требуется на всех узлах, а также домашние каталоги пользователей, временные хранилища общего доступа (для хранения временных данных расчётов) и прочие данные, которые должны быть доступны со всех узлов. Внешние СХД обычно различаются по внутреннему устройству и по способу доступа, от чего зависит уровень надёжности хранения данных и скорость доступа к ним. Внутреннее устройство СХД мы разбирать здесь не будем, упомянем лишь различные способы доступа.
По способу доступа СХД разделяются как минимум на три типа:
• непосредственно подключённая СХД – Direct Attached Storage или DAS;
• СХД с доступом по локальной сети или сетевое хранилище данных – Network Attached Storage, или NAS;
• СХД, подключённая через выделенную сеть хранения данных – Storage Area Network или SAN (см. рис. 3).
Непосредственно подключённая СХД подключается либо к выделенному узлу хранения данных, либо к управляющему узлу. Такая СХД всегда видна в операционной системе узла, к которому она подключена, как локально подключённое дисковое устройство (физическое подключение – по SATA, SAS, Fibre Channel).
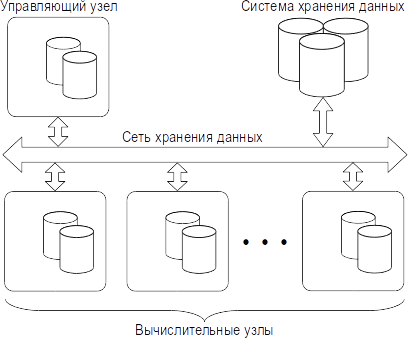
Рис. 3: сеть хранения данных (SAN)
Для обеспечения отказоустойчивости и повышения скорости работы в системах хранения нередко используют технологию RAID (redundant array of independent disks – избыточный массив независимых дисков). В рамках RAID несколько дисков равного объёма объединяются в один логический диск. Объединение происходит на уровне блоков (которые могут не совпадать с физическими блоками дисков). Один логический блок может отображаться на один или несколько дисковых блоков.
Есть несколько «уровней», которые приняты как стандарт de-facto для RAID:
RAID-0 – логические блоки однозначно соответствуют блокам дисков, при этом они чередуются: блок0 = блок0 первого диска, блок1 = блок1 второго диска и т. д.;
RAID-1 – зеркальный массив, логический блок N соответствует логическим блокам N всех дисков, они должны иметь одинаковое содержимое;
RAID-2 – массив с избыточностью по коду Хэмминга;
RAID-3 и -4 – дисковые массивы с чередованием и выделенным диском контрольной суммы;
RAID-5 – дисковый массив с чередованием и невыделенным диском контрольной суммы;
RAID-6 – дисковый массив с чередованием, использующий две контрольные суммы, вычисляемые двумя независимыми способами.
Уровень 0 обеспечивает наибольшую скорость последовательной записи – блоки пишутся параллельно на разные диски, но не обеспечивает отказоустойчивости; уровень 1 – наибольшую отказоустойчивость, так как выход из строя N-1 диска не приводит к потере данных.
Уровни 2, 3 и 4 в реальности не используются, так как уровень 5 даёт лучшую скорость и надёжность при той же степени избыточности. В этих уровнях блоки дисков объединяются в полосы, или страйпы (англ. stripe).
В каждом страйпе один блок выделяется для хранения контрольной суммы (для уровня 6 – два страйпа), а остальные – для данных, при этом диск, используемый для контрольной суммы, чередуется у последовательных страйпов для выравнивания нагрузки на диски. При записи в любой блок рассчитывается контрольная сумма данных для всего страйпа, и записывается в блок контрольной суммы. Если один из дисков вышел из строя, то для чтения логического блока, который был на нём, производится чтение всего страйпа и по данным работающих блоков и контрольной суммы вычисляются данные блока.
Таким образом, для RAID-5 можно получить отказоустойчивость при меньшей избыточности, чем у зеркала (RAID-1), – вместо половины дисков можно отдать под избыточные данные только один диск в страйпе (два для RAID-6). Как правило, «ширина» страйпа составляет 3-5 дисков. Ценой этого становится скорость работы – для записи одного блока нужно сначала считать весь страйп, чтобы вычислить новую контрольную сумму.
Часто применяют двухуровневые схемы – RAID-массивы сами используются как диски для других RAID-массивов. В этом случае уровень RAID обозначается двумя цифрами: сначала нижний уровень, затем верхний. Наиболее часто встречаются RAID-10 (RAID-0, построенный из массивов RAID-1), RAID-50 и -60 – массивы RAID-0, построенные из массивов RAID-5 и -6 соответственно. Подробнее о RAID читайте в литературе и Интернете.
Если используется распределённое хранение данных, например, как в Lustre (о ней мы расскажем далее), то узлов хранения данных может быть несколько, а данные, хранящиеся на такой СХД, распределяются по узлам хранения данных. СХД с доступом по локальной сети (или сетевое хранилище данных, NAS) обычно предоставляет дисковое пространство узлам по специальным протоколам, которые можно объединить под общим названием сетевые файловые системы. Примерами таких файловых систем могут быть NFS (Network File System), Server Message Block (SMB) или её современный вариант – Common Internet File System (CIFS).
Строго говоря, CIFS и SMB – два разных названия одной и той же сетевой файловой системы, изначально разработанной компанией IBM и активно используемой в операционных системах компании Microsoft. Сейчас CIFS может применяться практически в любой операционной системе для предоставления доступа к файлам через локальную сеть. Как правило, кроме NFS и CIFS системы NAS могут предоставлять доступ к хранимым данным и по другим протоколам, например FTP, HTTP или iSCSI.
СХД, подключённые через специальные сети хранения данных (SAN), обычно видны в операционной системе как локально подключённые дисковые устройства. Особенность SAN в том, что для формирования такой сети в целях повышения надёжности могут использоваться дублированные коммутаторы. В этом случае каждый узел будет иметь несколько маршрутов для доступа к СХД, один из которых назначается основным, остальные – резервными. При выходе из строя одного из компонентов, через которые проходит основной маршрут, доступ будет осуществляться по резервному маршруту.
Переключение на резервный маршрут будет происходить мгновенно, и пользователь не обнаружит, что вообще что-то вышло из строя. Для того чтобы это работало, необходима поддержка множественных маршрутов (multipath) в оборудовании и ОС. Заметим, что хотя для multipath и есть стандарты, но в реальности часто встречается «капризное» оборудование, для корректной работы которого с multipath требуются нестандартные драйверы или пакеты системного ПО.
Отличие NAS от SAN довольно условное, поскольку существует протокол обмена iSCSI, позволяющий использовать обычную локальную сеть в качестве сети хранения данных. В этом случае сетевое хранилище данных будет видно в операционной системе как локально подключённое дисковое пространство. Сеть хранения данных может объединяться с высокоскоростной коммуникационной сетью. Например, в качестве SAN-сети способна выступать InfiniBand, используемая для высокоскоростного обмена данными между вычислительными узлами кластера.
Особенности аппаратной архитектуры
Ни для кого не секрет, что в самом начале компьютерной эры понятия «процессор» и «ядро» (имеется в виду вычислительное ядро процессора) были синонимичными. Точнее, понятие «ядро» к процессору не относилось вовсе, поскольку многоядерных процессоров ещё не было. В каждом компьютере устанавливался обычно один процессор, который в каждый момент времени мог исполнять лишь один процесс. Современные системы такого типа можно встретить и сейчас, но они, как правило, предназначены для решения специальных задач (контроллеры, встраиваемые системы).
Для увеличения мощности сервера или рабочей станции производители устанавливали несколько «одноядерных» процессоров (обычно от двух до восьми). Такие системы существуют и сейчас и называются симметричными многопроцессорными системами, или SMP-системами (от англ. Symmetric Multiprocessor System) (см. рис. 4).
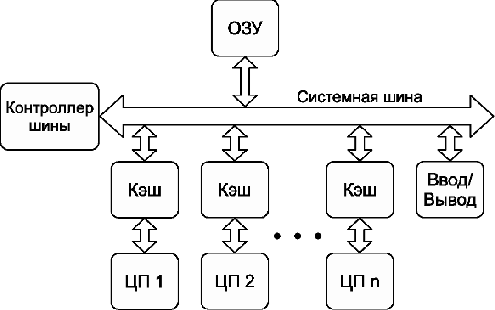
Рис. 4: симметричная многопроцессорная система (SMP)
Как видно из схемы, каждый процессор, представляющий собой одно вычислительное ядро, соединён с общей системной шиной. В такой конфигурации доступ к памяти для всех процессоров одинаков, поэтому система называется симметричной. В последнее время в каждом процессоре присутствует несколько ядер (обычно от 2 до 16). Каждое из таких ядер может рассматриваться как процессор в специфической SMP-системе. Конечно, многоядерная система отличается от SMP-системы, но эти отличия почти незаметны для пользователя (до тех пор, пока он не задумается о тонкой оптимизации программы).
Для ускорения работы с памятью нередко применяется технология NUMA – Non-Uniform Memory Access. В этом случае каждый процессор имеет свой канал в память, при этом к части памяти он подсоединён напрямую, а к остальным – через общую шину. Теперь доступ к «своей» памяти будет быстрым, а к «чужой» – более медленным. При грамотном использовании такой архитектуры в приложении можно получить существенное ускорение.
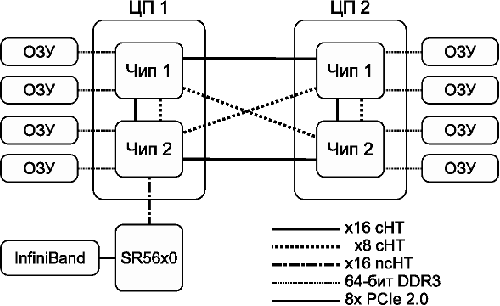
Рис. 5: схема узла NUMA на примере AMD Magny-Cours
Например, в архитектуре AMD Magny-Cours (см. рис. 5) каждый процессор состоит из двух кристаллов (логических процессоров), соединённых между собой каналами HyperTransport. Каждый кристалл (чип) содержит в себе шесть вычислительных ядер и свой собственный двухканальный контроллер памяти. Доступ в «свою» память идёт через контроллер памяти, а в «соседнюю» – через канал HyperTransport. Как видим, построить SMP- или NUMA-систему из двух или четырёх процессоров вполне возможно, а вот с большим числом процессоров – уже непросто.
Ещё одним «камнем преткновения» в современных многоядерных системах является миграция процессов между ядрами. В общем случае для организации работы множества процессов операционная система предоставляет каждому процессу определённый период времени (обычно порядка миллисекунд), после чего процесс переводится в пассивный режим.
Планировщик выполнения заданий, переводя процесс из пассивного режима, выбирает ядро, которое не обязательно совпадает с тем, на котором процесс выполнялся до этого. Нередко получается так, что процесс «гуляет» по всем ядрам, имеющимся в системе. Даже в случае с SMP-системами влияние на скорость работы программы при такой миграции заметно, а в NUMA-системах это приводит ещё и к большим задержкам при доступе в память.
Для того, чтобы избавиться от паразитного влияния миграции процессов между ядрами, используется привязка процессов к ядрам (processor affinity, или pinning). Привязка может осуществляться как к отдельному ядру, так и к нескольким ядрам или даже к одному и более NUMA-узлам. С применением привязки миграция процессов или будет происходить контролируемым образом, или будет исключена вовсе.
Аналогичная проблема присутствует и в механизме выделения памяти пользовательским процессам. Допустим, процессу, работающему на одном NUMA-узле, требуется для работы выделить дополнительную память. В какой области памяти будет выделен новый блок? А вдруг он попадёт на достаточно удалённый NUMA-узел, что резко уменьшит скорость обмена? Для того, чтобы избежать выделения памяти на сторонних узлах, есть механизм привязки процессов к памяти определённого NUMA-узла (memory affinity).
В нормальном случае каждый процесс параллельной программы привязывается к определённым NUMA-узлам как по ядрам, так и по памяти. В этом случае скорость работы параллельной программы не будет зависеть от запуска и будет достаточно стабильной. При запуске параллельных программ такая привязка не просто желательна, а обязательна. Более подробно данный вопрос рассмотрен в главе «Библиотеки поддержки параллельных вычислений», где описываются различные среды параллельного программирования.
В большинстве современных процессоров компании Intel используется технология HyperThreading. Благодаря этой технологии каждое вычислительное ядро представлено в системе как два отдельных ядра. Конечно, эффективность использования аппаратных ресурсов в этом случае сильно зависит от того, как написана программа и с использованием каких библиотек и каким компилятором она собрана. В большинстве случаев параллельные вычислительные программы написаны достаточно эффективно, поэтому ускорения от использования технологии HyperThreading может не быть, и даже наоборот, будет наблюдаться замедление от её использования.
На суперкомпьютерах эта технология вообще может быть отключена в BIOS каждого узла, чтобы не вносить дополнительных трудностей в работу параллельных программ. Как правило, эта технология не приносит ускорения для вычислительных программ. Если вы используете небольшой набор программ на суперкомпьютере, проверьте их работу с включённым и отключённым HyperThreading и выберите лучший вариант. Обычно мы рекомендуем включить её, но при этом указать системе управления заданиями число ядер, как с отключённым HT. Это позволяет получить дополнительные ресурсы для системных сервисов, минимально влияя на работу вычислительных заданий.
Ещё одна особенность архитектуры касается уже не отдельного, а нескольких узлов. Как мы ранее указывали, вычислительные узлы в вычислительном кластере объединены высокоскоростной коммуникационной сетью. Такая сеть может предоставлять дополнительные возможности обмена данными между процессами параллельных программ, запущенных на нескольких вычислительных узлах. В рамках одного узла применяется технология прямого доступа в память (Direct Memory Access, или DMA), позволяющая устройствам узла связываться с оперативной памятью без участия процессора. Например, обмен данными с жёстким диском или с сетевым адаптером может быть организован с использованием технологии DMA.
Адаптер InfiniBand, используя технологию DMA, предоставляет возможность обращаться в память удалённого узла без участия процессора на удалённом узле (технология Remote Direct Memory Access, или RDMA). В этом случае возникнет необходимость синхронизации кэшей процессоров (данный аспект мы не будем рассматривать подробно). Применение технологии RDMA позволяет решить некоторые проблемы масштабируемости и эффективности использования ресурсов.
Существует достаточно серьёзная критика данной технологии. Считается, что модель двухстороннего приёма-передачи (two-sided Send/Receive model), применяемая в суперкомпьютерах компании Cray (коммуникационная сеть SeaStar) и в коммуникационных сетях Quadrics QsNet, Qlogic InfiniPath и Myrinet Express, более эффективна при использовании параллельной среды программирования MPI. Конечно, это не исключает эффективного использования технологии RDMA, но применение её ограничено. В большинстве практических приложений использование RDMA даёт снижение латентности, но на больших приложениях (сотни узлов) может вылиться в чрезмерное использование системной памяти.
Краткое резюме
Знание аппаратуры, основных принципов работы ваших сетей, хранилищ данных и прочих «железных» компонент очень важно для администратора суперкомпьютера. Без этих знаний часто бывает невозможно решить проблемы, возникающие в таких вычислительных комплексах.
Ключевые слова для поиска
rdma, hpc interconnect, numa, smp, cache, latency.
Глава 3. Как работает суперкомпьютер
Рассмотрим стек ПО, который необходим для обеспечения работы суперкомпьютера. Очевидно, что в первую очередь это операционная система, затем системное ПО, которое требуется для работы аппаратной части, – драйверы и т. п., а также ПО для файловой системы.
Следующая часть – набор ПО для организации загрузки и ПО для удалённого доступа. Далее – система контроля запуска заданий (система очередей, batch system). Потом следует ПО, необходимое для работы параллельных программ: готовые параллельные пакты и библиотеки – MPI, Cuda и т. п.
Обязательный компонент – компиляторы и дополнительные библиотеки, часто требующиеся для вычислительных программ, такие как BLAS, FFT и др. Для организации полноценного управления суперкомпьютером также потребуются ПО для организации резервного копирования, мониторинга, ведения статистики, визуализации состояния суперкомпьютера.
Как происходит типичный сеанс пользователя
Существует множество вариантов организации работы с конкретными вычислительными пакетами, которые предоставляют собственный интерфейс для работы с суперкомпьютером. Мы будем рассматривать «общий» вариант.
Итак, пользователь работает на своём компьютере – рабочей станции, ноутбуке, планшете и т. п. Для начала сеанса он запускает ssh-клиент (putty, openssh и т. п.), вводит адрес, логин, указывает пароль или файл с закрытым ключом (или загружает профиль, где всё это уже указано) и открывает соединение с суперкомпьютером. Попав на узел доступа, пользователь может отредактировать и откомпилировать собственную параллельную программу, скопировать по протоколу sftp входные данные. Для запуска программы пользователь выполняет специальную команду, которая ставит его задание в очередь. В команде он указывает число требуемых процессов, возможно, число узлов и другие предпочтения, а также свою программу и её аргументы. Пользователь может проверить статус своего задания, посмотреть список заданий в очереди. Если он понял, что в программе ошибка, то может снять её со счёта или удалить из очереди, если она ещё не запустилась.
При необходимости можно поставить в очередь и несколько заданий (например, если нужно обработать несколько наборов входных данных). После того как задание поставлено в очередь, его ввод/вывод будет перенаправлен в файлы, поэтому можно спокойно завершить сеанс и проверить состояние задания или посмотреть/скачать результаты позже, в другом сеансе. Большинство систем управления заданиями позволяют запустить задание и интерактивно, связав её ввод/вывод с терминалом пользователя. В этом случае придётся оставлять сеанс открытым до тех пор, пока задание стоит в очереди и работает.
Вся работа происходит в командной строке, поэтому пользователь должен знать минимальный набор команд Linux (как правило, это не составляет проблем). Элементарного самоучителя Linux или даже странички на сайте с описанием нужных команд обычно бывает достаточно. Для управления файлами многие пользователи применяют программу Midnight Commander (mc), которая ещё больше упрощает задачу.
Жизненный цикл задания
Типичное задание на суперкомпьютере проходит несколько фаз. Первая – постановка задания в очередь. На этом этапе пользователь указывает путь к исполняемой программе, её аргументы и параметры запуска, такие как число MPI-процессов, число узлов, требования к ним и т. д. Явно или неявно пользователь указывает также способ запуска задания – через команду mpirun (для MPI-приложений), как обычное приложение и т. д.
Система управления заданиями регулярно проверяет, можно ли запустить новую задание, просматривая очередь. Как только наше задание подойдёт к началу очереди или по каким-то иным критериям подойдёт для запуска, система управления (точнее, её планировщик) выберет набор узлов, на которых будет произведён запуск, оповестит их, возможно, выполнит скрипт инициализации (так называемый пролог) и приступит к запуску задания.
Фаза запуска может отличаться в разных системах, но общий смысл одинаков: на вычислительном или управляющем узле запускается стартовый процесс, например mpirun, которому передаётся список узлов и другие параметры. Этот процесс запускает на вычислительных узлах рабочие процессы задания – самостоятельно (через ssh) или используя помощь системы управления заданиями. С этого момента система управления заданиями считает, что задание работает. Она может отслеживать состояние рабочих процессов на узлах, если это поддерживается, или отслеживать только состояние стартового процесса. Как только стартовый процесс завершается либо задание снимается со счёта принудительно (пользователем или самой системой управления), задание переходит в фазу завершения.
В этой фазе система управления пытается корректно завершить работу задания – убедиться, что все её процессы завершились, не осталось лишних файлов во временных каталогах и т. п. Для этого часто используется отдельный скрипт, так называемый эпилог. По окончании фазы завершения задание считается завершённым. Какое-то время информация о ней может сохраняться в системе управления, но обычно данные о ней теперь можно найти только в журналах.
В описанном цикле могут быть и нестандартные действия, например изменение приоритета задания, меняющее скорость его прохождения в очереди, блокировка, временно запрещающая запуск задания, приостановка работы и некоторые другие.