



Нина Краус
Мозг слушает. Как создается осмысленный звуковой мир
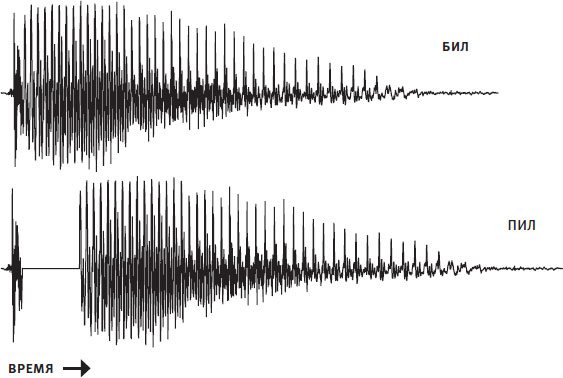
Рис. 1.8. “Бил” превращается в “пил” за счет добавления паузы длительностью 1 /20 с до начала произнесения гласного звука (по оси x отложено время, по оси y – энергия).
Произнесите вслух слово “был”. А потом слово “жил”. Можете описать, чем различаются механические движения вашего рта? Это довольно просто. В первом случае ваши губы смыкаются, а язык занимает некую нейтральную позицию. Во втором случае губы слегка приоткрыты, а задняя часть языка прижата к небу. А теперь скажите “бил” и “пил”. Это сложнее. В чем тут разница? Механическая разница между произнесением “б” и “п” не так уж очевидна. Язык и губы в обоих случаях находятся фактически в одном и том же положении. Основное отличие заключается во временной развертке – когда вы начинаете произносить гласную, то есть когда голосовые складки начинают издавать звук “и”. Произнося слово “бил”, вы включаете голос почти сразу. Однако при произнесении слова “пил” между тем, как ваши губы раскрываются, и тем моментом, когда вы начинаете произносить гласный звук, имеется очень короткий промежуток времени. В верхней части рис. 1.8 изображена звуковая волна слова “бил”. В нижнюю волну я включила паузу длительностью 1/20 секунды. Все колебания двух линий идентичны, за исключением этой добавленной паузы. Небольшой паузы до начала произнесения “и” достаточно, чтобы вторая волна отчетливо звучала как “пил”. Различие во времени в несколько долей секунды создает значительное различие в речи. Это одна из многих причин, почему для обработки таких едва заметных изменений звука нам с вами требуется сверхбыстрый слуховой мозг.
Анализируем изменения частоты во времени
Такие различия во временной развертке, как в “бил” и “пил”, хорошо видны на графиках временной зависимости типа изображенного на рис. 1.8. Различие в частоте, как в “и” и “у”, отражаются на спектрах, подобных тем, что представлены на рис. 1.6. Однако ни один из графиков не смог бы показать акустическое различие между звуками “б” и “г”. Здесь дело заключается в изменении частоты во времени. Чтобы правильно описать различие между “б” и “г”, нам нужен третий и последний график, называемый спектрограммой.
На верхней панели на рис. 1.9 представлен простой пример, изображающий звуковой тон, который со временем переходит от низкочастотного к высокочастотному и обратно, как в одобрительном свисте при виде чего-то впечатляющего. Вспомните звук сирены или представьте себе, что водите пальцем по клавиатуре фортепиано.
Различие между согласными в слогах “ба” и “га” определяется изменением частот полос акустической энергии во времени (нижняя панель). Верхняя полоса гармоник для “ба” и “га” одинаковая: она изменяется во времени от низкой до высокой частоты, пока не выравнивается на звуке “а”. Но на нижней полосе два слога различаются. В случае “ба” частота изменяется от низкой до высокой, а затем выравнивается. В случае “га” звук начинается на относительно более высокой частоте, а затем снижается. Частотная модуляция (ЧМ, или FM, от frequency modulation) – важная характеристика звука, которая отражает это изменение частоты во времени.
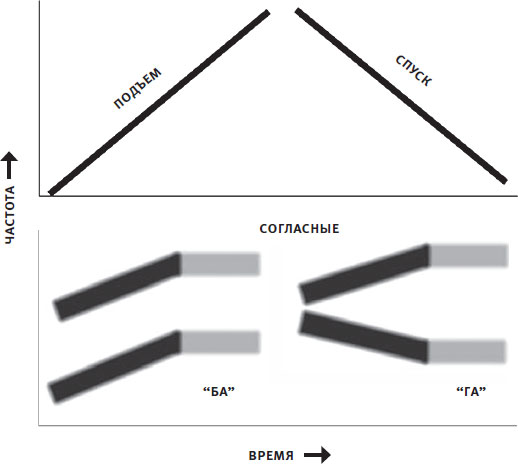
Рис. 1.9. Спектрограмма (график изменения частоты во времени). Вверху: частота увеличивается, затем уменьшается. Внизу: слоги “ба” и “га”. Частоты обеих волн акустической энергии изменяются со временем, пока не стабилизируются на гласном звуке “а”.
Таким образом, в обоих наших примерах с парами согласных звуков (“б”/“п” и “б”/“г”) временная развертка является важнейшим фактором, который необходимо учитывать. В случае слогов “ба” и “па” время является необходимым и достаточным элементом для выявления различия. В случае слогов “ба” и “га” различие определяется взаимодействием обоих факторов – времени и частоты. Хотя мы способны уловить и выделить эти звуковые различия, замедлив произнесение и произведя измерения, на практике они произносятся слишком быстро, чтобы мы могли осознанно воспринимать отличающие их параметры. Удивительно быстро. Подумайте об этом: знали ли вы о разнице между “ба” и “га” в контексте компонентов звука до того, как я вам об этом рассказала? Понимали ли вы, что пара мгновенных частотных модуляций может превратить “пегого дога” в “беглого бога”? Я совершенно определенно не могу определить на слух, что какая-то энергетическая полоса поднимается в “ба” и опускается в “га”. И эта скорость и тонкость объясняют сложность восприятия согласных звуков и требуют применения фонетического алфавита (Антон, Борис, Василий, Григорий…). Тонкость и сложность дифференцирования и трудности в восприятии этих звуков у некоторых людей имеют интересные последствия для речи и даже для чтения, как мы увидим далее.
При обсуждении временных параметров мы сконцентрировались на речи. И это не случайно. Речь функционирует в гораздо более быстрых рамках, чем другие звуки, включая музыку. Например, allegro – это музыкальный темп в диапазоне 120–170 ударов в минуту (уд/мин). Для простоты давайте рассмотрим музыкальную пьесу в темпе аллегро в ритме 150 уд/мин. Это соответствует двум с половиной ударам (четвертным нотам) в секунду. Так что каждая четвертная нота длится целых 400 миллисекунд (тысячных долей секунды), одна восьмая – 200 мс, а одна шестнадцатая – 100 мс. Пьеса “Полет шмеля” исполняется в еще более быстром темпе presto и интересна тем, что обычно для восприятия двух нот раздельно нам требуется целых 100 мс. Заставив шестнадцатые доли главной темы звучать по 80–85 мс, Римский-Корсаков превратил ноты в нечто напоминающее жужжание шмеля. Однако с речью совсем другая история. Согласные в обычной речи длятся так же коротко или еще короче – примерно от 20 до 40 мс. И мы можем почти бесконечно произносить речь, наполненную согласными звуками. К счастью для всех музыкантов, исполнявших “Полет шмеля”, эта пьеса короткая.
Другие компоненты звука
Интенсивность – это мера амплитуды изменений давления воздуха, которую мы воспринимаем как громкость: сколько воздуха сдвигает гитарная струна на рис. 1.1 и насколько высоки создаваемые ею волны, изображенные на рис. 1.3. В абсолютном измерении звук производит едва заметные изменения давления воздуха. Однако мы воспринимаем изменения давления в широчайшем диапазоне – от тишайших до самых громких звуков, различающихся по физическому давлению воздуха в десять триллионов раз. Поэтому, чтобы отобразить наше восприятие громкости звука с помощью каких-то удобных показателей, мы используем логарифмическую шкалу, переводя количество перемещенного воздуха в знакомые всем единицы интенсивности звука – децибелы (дБ). В результате диапазон в десять триллионов раз можно выразить в единицах от 0 дБ (это порог слышимости, ниже предела чувствительности самых чувствительных микрофонов) до 140 дБ – самого громкого звука, который мы в состоянии вынести.
Возможно, термины амплитудная и частотная модуляция (АМ и ЧМ) ассоциируются у вас только с настройкой радиоприемника. Однако АМ и ЧМ чрезвычайно важны для нашего звукового пространства и особенно для речи. АМ – это флуктуации интенсивности звука (амплитуды): громкий-тихий-громкий-тихий. Автомобильная сигнализация часто работает в режиме от громкого к тихому. Колебания голосовых складок при их открытии и закрытии осуществляют амплитудную модуляцию того, что мы произносим на нашей высоте голоса (на основной частоте). На рис. 1.4 отражена обычная форма АМ: один и тот же сигнал модулируется по амплитуде с разными скоростями.
Частотная модуляция отражает изменение частоты во времени. Когда в речи мы переходим от гласных к согласным и наоборот, полосы акустической энергии поднимаются и опускаются. Это и есть частотная модуляция (изменение на рис. 1.9).
Еще один компонент звука, который стоит упомянуть, это фаза. В начале главы мы обсуждали давление молекул воздуха справа от гитарной струны. Молекулы воздуха слева от струны на рис. 1.1, которые мы не показали, рассеиваются, когда молекулы справа сжимаются, и наоборот. В каждый конкретный момент времени движение струны одновременно сжимает и рассеивает соседние молекулы воздуха. Два человека, сидящие по разные стороны от гитары, слышат музыку, которая по сигналу и давлению различается по фазе на 180 градусов. Графики доходящих до них волн как бы перевернуты по отношению друг к другу. В зависимости от того, где вы находитесь, звук гитары достигает ваших ушей в разное время, или в разной фазе. Эти фазы важны для локализации источника звука, а сложение и погашение фаз играют роль в идентификации звуков в шумном пространстве или при наличии ревербераций (эха).
И, наконец, явление фильтрации. Фильтрация – это избирательное усиление или ослабление некоторых частот звукового сигнала. Мы фильтруем звук миллион раз в день – как преднамеренно, так и непреднамеренно. Любимая песня звучит по-разному, когда вы слушаете ее на домашней стереосистеме, в машине, через компьютер, через наушники или через мобильный телефон. Каждая система воспроизведения звука имеет свои фильтры, которые либо тщательно изготовлены специалистами по звуку, либо просто удовлетворяют таким параметрам товара, как размер и стоимость, или каким-то иным показателям. Ваш голос и голоса ваших друзей звучат по-разному на улице и в кафе. Фильтрация, вызванная твердой поверхностью стен, потолка и ванны, объясняет, почему мы любим петь под душем. Готические соборы имеют фигурные каменные поверхности, вызывающие многократное отражение звука на более высоких частотах, что обеспечивает особую акустическую атмосферу для музыки и речи. Попробуйте послушать звук своего мобильного телефона, переходя из комнаты в комнату. Кроме того, что звук фильтруется во внешнем пространстве, мы сами тоже преднамеренно фильтруем звуки, издаваемые ртом, языком и губами, чтобы произнести слова, требующиеся для передачи сообщения.
Сигналы снаружи и внутри головы: компоненты
Наш мозг придает смысл внешним сигналам (звукам) с помощью сигналов внутри головы – электрических импульсов нейронов.
Каждый ученый выбирает определенную стратегию научного поиска. Одни проводят опросы. Другие используют экспрессию генов. А третьи анализируют биомаркеры в крови. Мой выбор – сигналы. Мне эти сигналы (как снаружи, так и внутри головы) кажутся надежными, поскольку они ощутимые, в каком-то смысле не такие эфемерные, как сам звук. Их можно достоверно измерить, и есть общеизвестные и эффективные способы их визуализации и анализа. Особенно меня привлекает замечательное сходство между сигналами внутри головы и снаружи. Это очень красиво. И поразительно, что так происходит. Эта реальность дает мне нечто надежное, на что можно повесить шляпу, на что можно опереться, когда я исследую такие важные проблемы, как влияние занятий музыкой на звуковой разум, связь поддержания ритма и грамотности или последствия сотрясения мозга для обработки звука. Сигналы направляют ход моих мыслей и открывают мне Истину.
Компоненты звука играют важнейшую роль в понимании того, почему все люди слышат по-разному и как личный звуковой опыт каждого человека может меняться в лучшую или худшую сторону по мере того, как наш звуковой разум сплетается с нашими ощущениями, размышлениями, чувствами и движениями.
Как нейробиолог, я могу привнести эту осязаемость в мое исследование звука и его обработки в мозге. Я могу изучать восприятие высоты, временной развертки и тембра по отдельности и как слуховое целое, чтобы понять, что происходит правильно или неправильно у людей, которые слышат превосходно или испытывают некоторые затруднения. Можно изучать по отдельности обработку разных компонентов звука и их превращение в наши ощущения. Например, некоторые люди плохо различают звуки разной высоты, но без труда воспринимают тембр, или наоборот. У других проблемы возникают только с временными характеристиками звука. Музыканты и двуязычные люди слышат превосходно, но их мастерское восприятие сигналов опирается на разные компоненты звука.
Теперь давайте посмотрим, что происходит, когда звуковая волна снаружи головы создает мозговые волны внутри – когда движение гитарной струны достигает слухового прохода.
Глава 2
Сигналы внутри головы
Компоненты звука внутри и снаружи
В какой-то момент в нашем эволюционном прошлом естественный отбор способствовал развитию у нас способности улавливать ушами изменение давления, вызванное самыми слабыми перемещениями молекул воздуха. В результате у нас появились части тела, которые за несколько удивительных стадий превращают движения воздуха, вызванные вибрацией гитарной струны или произнесением слова, в амальгаму компонентов (высоты, тембра и временной развертки), которые мы воспринимаем как звук гитары или голоса.
Трансдукция (от лат. transductio – перемещение) в физиологии означает смену одного состояния на другое. Обменная валюта нервной системы – электричество. Если мы хотим осмыслить звук и подействовать на него, нам нужен способ преобразования, или трансдукции, движения воздуха в электричество мозга. Как мы это делаем? Все начинается в ухе и протекает через элегантную последовательность событий, включающих в себя физические движения костей, перемещение жидкостей и выделение химических соединений. Затем сигнал поступает в мозг в виде электрических импульсов, созданных ухом, и там обрабатывается далее, в результате чего наш звуковой разум может извлечь максимум информации из внешних звуков.
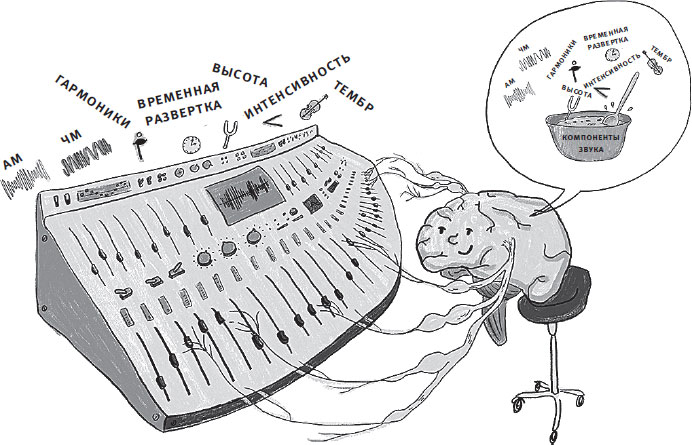
Рис. 2.1. Звуковой разум обрабатывает компоненты звука, извлекая из них максимум возможностей.
Мне нравится сравнивать процесс обработки звука в мозге с микшерным пультом. Как звукоинженер в студии звукозаписи, который перемещает регуляторы (фейдеры) вверх и вниз в поисках равновесия между гитарой и вокалом, так и мозг усиливает одни компоненты звука и ослабляет другие (рис. 2.1).
Когда трансдукция выполнена и мы работаем в удобной среде электрических сигналов, мы можем отображать их с помощью тех же графиков времени, частоты (спектр) и частоты во времени (спектрограмма), которые мы обычно используем, когда говорим о звуке. Как и в случае внешних сигналов, при обработке сигналов внутри головы необходимо, чтобы те же компоненты, такие как частота, временная развертка и гармоники, обрабатывались раздельно, как с помощью фейдеров и потенциометров на микшерном пульте. В каждом мозге фейдеры устанавливаются по-разному в зависимости от опыта, навыков, потери или ослабления слуха. Каждый звуковой разум уникален.
Вверх и вниз
Звуковой разум обширен. Когда мы слушаем, электрические сигналы проходят через мозг, перемещаясь восходящими и нисходящими потоками, взаимодействуя с другими ощущениями – с тем, как мы движемся, что мы думаем и что мы чувствуем. Вся эта мозговая сеть позволяет нам осмысливать звук – извлекать смысл из нашего звукового окружения (рис. 2.2).
Прилагательные эфферентный и афферентный обозначают направление движения – от чего-то или к чему-то соответственно. От чего и к чему? В системе циркуляции крови – от сердца и к сердцу. Сосуды, переносящие кровь от сердца, называются эфферентными, а несущие кровь к сердцу – афферентными. Афферентные и эфферентные потоки есть в лимфатической системе: они переносят лимфу в лимфатические узлы и из них. В нейробиологии мозг – это узел. Афферентная система переносит информацию от уха к мозгу. Эфферентная система переносит информацию от мозга обратно к уху и тем самым играет ключевую роль в том, как мы обучаемся – как мы конструируем нашу звуковую реальность и становимся самими собой в плане звукового восприятия.
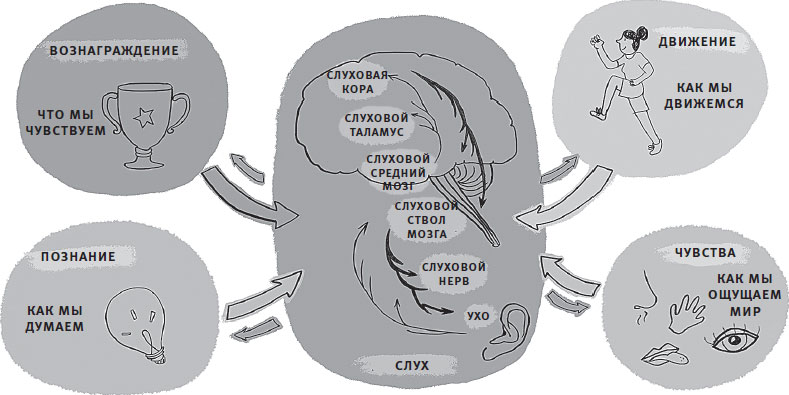
Рис. 2.2. Слуховой путь имеет двунаправленные связи между собственными структурами и областями мозга, ответственными за ощущения, мышление, чувства и движения.
Восходящий поток (афферентный путь)
Эта глава рассказывает о путешествии электрического сигнала “вверх”[13] от уха через мозг. В Google по запросу “слуховой путь” появляются картинки, подкрепляющие классическое представление об иерархии слуховых механизмов, – в основном блок-диаграммы с однонаправленными стрелками, ведущими от уха к мозгу, как на рис. 2.3. Это не ошибка: действительно, слуховой ствол мозга располагается между нервом и слуховым средним мозгом. Таламус находится между средним мозгом и корой. Но это лишь одна часть общей картины. На самом деле существует двунаправленный поток информации, который обычно не следует иерархическим путям. Но хотя я не согласна с иерархическим описанием слуховой системы, я считаю, что однонаправленная модель полезна для описания слухового пути. Сейчас мы проследуем по стрелкам афферентной (направленной к мозгу) обработки сигнала, идущим вверх. И закончим главу кратким обзором нисходящих влияний на эту обработку, чтобы позднее исследовать их подробнее.
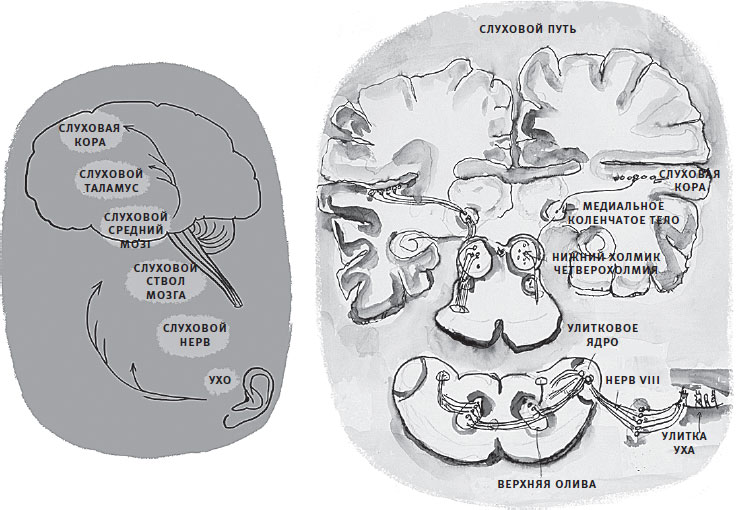
Рис. 2.3. Слуховой путь в мозге, соответствующий схеме слева. Акварельная иллюстрация д-ра Арнольда Старра, впервые использовавшего реакции мозга на звук для оценки неврологического здоровья. Воспроизведено с разрешения; фото Тома Лэмба.
Ухо
Наружное ухо. Наружное ухо – видимая часть уха – воронкой направляет звук в слуховой канал к среднему уху.
Среднее ухо. Когда волна давления, вызванная движением воздуха, попадает в ухо, проходит через его наружную часть и слуховой канал, она ударяется о барабанную перепонку, иначе называемую тимпанической мембраной. В отличие от некоторых общеупотребимых названий анатомических структур, таких как адамово яблоко или коленная чашечка, слово “барабан” вполне точно описывает эту преграду на пути в среднее ухо. Как и кожаная мембрана барабана, барабанная перепонка – тоже мембрана, растягивающаяся при ударе звукового давления. Когда эта крошечная мембрана движется, она толкает первую из трех самых маленьких костей нашего тела – слуховых косточек[14], которая, в свою очередь, толкает вторую и, наконец, последнюю косточку, называемую стремечком. Далее стремечко ударяется о другую анатомическую мембрану – еще более крошечное овальное окно, закрывающее проход во внутреннее ухо. Зачем нам нужны две перепонки, разделенные тремя косточками? Затем, что с другой стороны овального окна внутри внутреннего уха находится жидкость. Перемещения воздуха недостаточно, чтобы напрямую надавить на овальное окно, поскольку жидкость внутри слишком плотная, чтобы перемещаться только под действием воздуха. Цепочка из трех косточек действует по принципу рычага и усиливает давление примерно в 20 раз[15]. Минимальный толчок по барабанной перепонке превращается в сильный удар, достаточный, чтобы подтолкнуть овальное окно. Заметьте, что мы все еще находимся на механической стадии процесса. Мы перешли от движения воздуха к движению жидкости. Но самая важная трансдукция в электричество еще впереди.
Внутреннее ухо (улитка). Теперь крохотное стремечко оказывает достаточно сильное давление, чтобы сместить овальное окно и находящуюся с другой стороны жидкость. Жидкость со свистом проносится через волосковые клетки Кортиева органа; эта структура расположена по всей длине свернутой в спираль улитки, и в соревновании на звание самого крохотного органа тела она проигрывает лишь одному органу (вот ведь!) – шишковидной железе. Посмотрите на рис. 2.4. По всей длине улитки располагаются волосковые клетки; и именно здесь происходит таинство трансдукции[16]. Волосковые клетки располагаются рядами – один внутренний и три внешних, – и каждый покрыт слоем еще более тонких ресничек под названием “стереоцилии”, плавно раскачивающихся в жидкости, как волосы ныряльщика. Волосковые клетки, как в сэндвиче, зажаты между базилярной и текториальной мембранами, названия которых происходят от архитектурных терминов: слово “базилярный” этимологически связано со словом “база” (основание), а слово “текториальный” происходит от латинского tectum, что означает “крыша”. Волосковые клетки встроены в основание, и стереоцилии не могут двигаться свободно, поскольку их кончики прикреплены к крыше. Когда жидкость начинает двигаться в результате толчка в овальное окно, некоторые волосковые клетки раскачиваются вверх и вниз, заставляя стереоцилии упираться в текториальную мембрану, что приводит к их отклонению вбок. Это движение как бы “открывает” внутренние волосковые клетки, так что в них могут проникать электрически заряженные химические частицы, в частности ионы кальция и калия. Эти ионы запускают цепную реакцию, заканчивающуюся высвобождением нейромедиаторов в синапс – место соединения волосковой клетки и слухового нерва, что приводит к быстрому изменению электрического напряжения в слуховом нерве. Наконец, мы дошли до трансдукции. Движение воздуха снаружи головы преобразовано в электричество внутри головы.
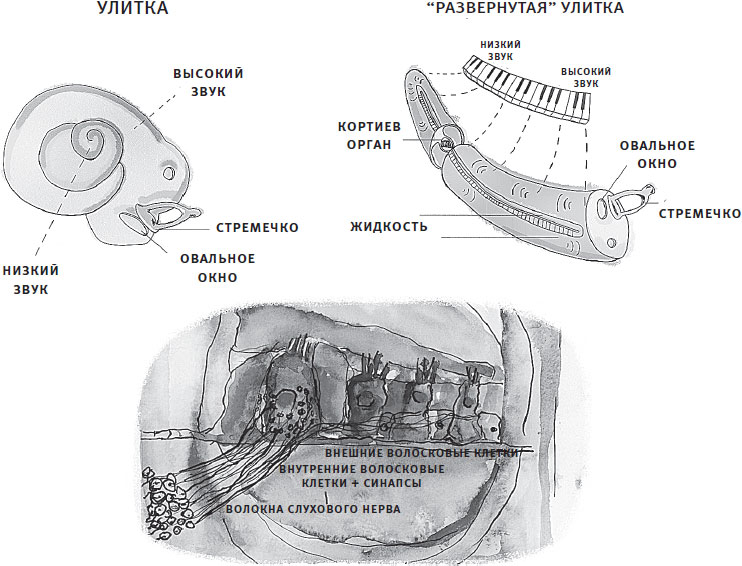
Рис. 2.4. Вверху: улитка в свернутом и развернутом виде. Основание свернутой улитки, где стремечко сталкивается с овальным окном, настроено на восприятие высокочастотных звуков. Верхушка (центр) улитки предпочитает низкочастотные звуки. На “развернутой” улитке справа это изображено схематически по аналогии с клавиатурой, а на срезе виден кортиев орган. Внизу: кортиев орган. Мы видим одну внутреннюю и три внешние волосковые клетки (зажатые в виде сэндвича между текториальной и базилярной мембранами) и их связь со слуховым нервом. Воспроизводится с разрешения из статьи Арнольда Старра. Фото Тома Лэмба.
Любая отдельно взятая волосковая клетка в улитке (их около 30 тысяч) не движется в ответ на каждый звук. Базилярная мембрана, к которой прикреплены волосковые клетки, по всей длине имеет разную ширину и жесткость. Ближайший к овальному окну конец самый узкий и жесткий, а при удалении от основания и приближении к верхушке мембрана становится шире и гибче (как “конский хвост”). Из-за этого физического различия волосковые клетки на узком и жестком конце реагируют на высокочастотные звуки. По мере того как звуки становятся все более и более низкочастотными, они начинают воздействовать на волосковые клетки, располагающиеся все ближе и ближе к гибкой верхушке. Такую упорядоченность называют тонотопией (“тональной топографией”). Впервые возникнув в улитке, тонотопическая карта, как крохотная фортепианная клавиатура, появляется вновь и вновь во всей слуховой системе от улитки до коры. Мозговые карты – это важнейший организационный принцип, определяющий функционирование наших чувств.
Слышащий мозг
Мы слышим мозгом. Одно из моих любимых рассуждений на эту тему приводится в книге Робина Уоллеса “Слышащий Бетховен”[17]. Как Бетховен сочинил некоторые из своих шедевров после того, как потерял слух? Так же, как делал всегда:
Он импровизировал. Он набрасывал. Он исправлял. Не было никакой принципиальной разницы между состоянием до глухоты и после ее появления. Было только постоянное уточнение его взаимоотношений с фортепиано. О Бетховене можно думать не как о птице без крыльев или рыбе без воды, но скорее как о пилоте, летящем без работающих навигационных инструментов, но с глубоким физическим пониманием того, как вести самолет.
После того как внешняя, средняя и внутренняя части уха выполнили свою работу, предстоит еще долгий путь, прежде чем мы сможем сказать, что “слышим”, то есть до того, как мы придадим звуку смысл. Зайдем в мозг. На нашем слуховом пути будет множество остановок.
Под словом “мозг” часто подразумевают кору – изрытую бороздками, состоящую из различных долей внешнюю оболочку мозга, покрывающую левое и правое полушарие. Я считаю, что следует уделить такое же внимание и менее известным участкам мозга, на которых располагается кора. Между слуховым нервом и корой находятся улитковое ядро, верхний оливарный комплекс (ствол мозга), нижний холмик четверохолмия (средний мозг) и медиальное коленчатое тело (таламус). Возникающие электрические сигналы при путешествии по мозгу проходят через эти структуры. На этом пути встречается гораздо больше промежуточных структур, чем в любой другой сенсорной системе.
Давайте рассмотрим путь от слухового нерва к слуховой коре. Обработка звука изменяется в процессе прохождения звукового сигнала через слуховой мозг. Воспитанница лаборатории Brainvolts Дженна Каннингем одновременно регистрировала сигналы нейронов среднего мозга, таламуса и коры и показала, что ответы нейронов, расположенных вдоль слухового пути, различаются между собой. Ее эксперименты позволили увидеть, что ответ на один и тот же звук в разных структурах разный[18].
Слуховой нерв. Слуховой нерв представляет собой пучок волокон (примерно 30 тысяч в каждом ухе), настроенных на определенную частоту в зависимости от того, в каком месте они встречаются с базилярной мембраной улитки. Обнаруженная нами в улитке тонотопическая карта (маленькая фортепианная клавиатура) далее повторяется в слуховом нерве. Частота звука определяется тем, в каком месте тонотопической карты располагается нейрон. По мере углубления в мозг тонотопические карты множатся.
При продвижении от уха к мозгу мы наблюдаем еще один организационный принцип: по мере восхождения по мозговой лестнице понижается скорость возбуждения нейронов[19]. Иными словами, скорость синхронизации конкретных нейронов со звуком в реальном времени систематически снижается при продвижении от уха к мозгу. Волокна слухового нерва являются самыми быстрыми.
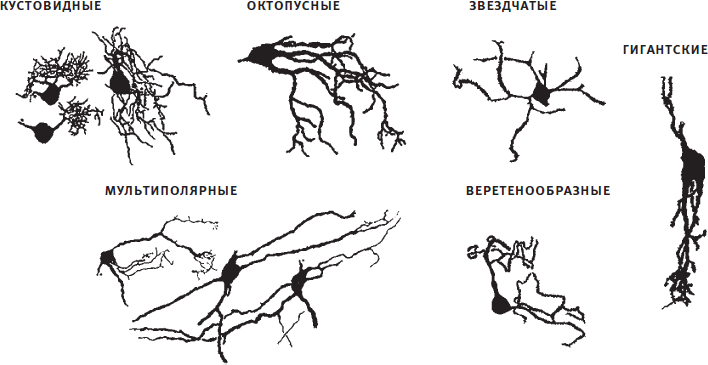
Рис. 2.5. Типы клеток в улитковом ядре. Воспроизводится в адаптированном виде из книги The Mammalian Auditory Pathway: Neuroanatomy с разрешения издательства Springer Nature.
Улитковое ядро. Первой структурой на пути к слуховой коре после возникновения электрического сигнала в месте соединения улитки со слуховым нервом является улитковое ядро. В нем содержится множество типов клеток с замечательными названиями (кустовидные, веретенообразные, октопусные!)[20] и характеристиками ответа[21], необходимыми для выполнения их работы. На рис. 2.5 я показываю, как выглядят эти клетки, просто потому, что мне они кажутся изумительными[22].
По мере восхождения по цепочке от уха к мозгу ответ нейронов на звуковой сигнал становится все более специализированным, благодаря принципу торможения. В отсутствие звука нейроны не полностью неактивны, они производят спонтанные импульсы. Ответом на звуковой сигнал может быть как возбуждение (выше частоты спонтанных импульсов), так и торможение (снижение активности ниже частоты спонтанных импульсов). Когда раздается звук с определенной частотой, пульсация настроенных на эту частоту нейронов начинает превышать спонтанный уровень. А пульсация нейронов, настроенных на близкие частоты, замедляется и становится ниже спонтанного уровня. Торможение позволяет выделить некоторые компоненты звука, повышая точность и настройку.
К области специализации улиткового ядра относится амплитудная модуляция (АМ)[23]. Клетки этой структуры специализируются на АМ некоторых частот. Высота голоса определяется АМ. Когда мы говорим, наш голос подвергается АМ в соответствии с колебаниями наших голосовых связок (с их открытием и закрытием).
После настройки в улитковом ядре нейронные импульсы проходят к следующей структуре цепи, однако это путешествие длится дольше, поскольку на этом уровне впервые нейронные электрические сигналы от каждого уха направляются в оба полушария мозга.
Верхний оливарный комплекс. Когда речь заходит о точности во времени, слуховая система по-настоящему восхищает и оставляет далеко позади систему зрительного восприятия. Микросекундные нюансы звука требуют микросекундной точности мозга. Волшебство временной настройки в значительной степени обеспечивается верхним оливарным комплексом, особенно в отношении бинауральной (bi – два, aural – ушной) обработки, локализации источника звука и избирательного улавливания конкретных звуков из звукового окружения.
Любой звук, источник которого находится не прямо перед нами, достигает двух ушей в разное время и с разной громкостью. Если звук доносится слева, он достигает левого уха на какую-то долю секунды раньше, чем правого уха. Если источник звука хоть в какой-то степени сдвинут относительно центрального положения, эта разность во времени может составлять порядка одной стотысячной доли секунды (10 мкс). Кроме того, слева он будет чуть громче, чем справа, поскольку его путь был чуть короче и его не преграждала голова. Эти различия во времени прибытия и громкости звука, достигающего двух ушей, вносят разный вклад в зависимости от частоты звука. Низкочастотные звуки с большей длиной волны проделывают путь вокруг головы с меньшей потерей громкости. Однако такой звук прибывает в два уха не одновременно, и мы способны уловить это различие в несколько микросекунд. Напротив, высокочастотный звук блокируется головой, так что два уха могут уловить различие в громкости. Поскольку каждое ухо направляет информацию как в левый, так и в правый верхний оливарный комплекс, есть возможность сравнить время прибытия и громкость звука[24]. Это помогает понять, из какой точки пространства идет звук. Давай, мозг, сделай свой расчет, пойми, какое положение может объяснять такое различие во времени прибытия и громкости звука, которое воспринимают мои уши. Кроме фиксации источника звука в пространстве, эта способность помогает составить из звуков “звуковые объекты”, такие как голос собеседника, так что мы способны улавливать его даже при наличии других звуков в звуковом пространстве. Если ваша приятельница сидит слева от вас в шумном ресторане, чрезвычайно полезно иметь возможность не обращать внимания на женщину с похожим голосом, сидящую за соседним столиком справа. Бинауральная обработка звука, позволяющая понять, где что, любезно обеспечивается верхним оливарным комплексом.
Слуховой средний мозг – нижний холмик четверохолмия. Следующая остановка на афферентном пути – верхушка нижнего холмика, расположенного в среднем мозге. Нижним он является по отношению к другому холмику, называемому верхним. Поскольку эта активная в метаболическом плане (жадно потребляющая энергию) структура одновременно является узлом обработки афферентной слуховой информации и главным перекрестком эфферентных, мультисенсорных и несенсорных нервных процессов, функционирование среднего мозга, названного так вполне обоснованно, представляет чрезвычайно большой интерес для нейробиологов, занимающихся слухом, поскольку характеризует слуховую функцию в целом.

Рис. 2.6. Сигналы от обоих ушей сливаются в верхнем оливарном комплексе, где анализируется относительное время их прибытия и интенсивность. Воспроизводится с разрешения Арнольда Старра. Фотография Тома Лэмба.
Все сигналы от перечисленных выше слуховых структур приходят в слуховой средний мозг из обоих ушей, как и сигналы из других частей мозга. Таким образом, в среднем мозге совершаются расчеты, связанные с избирательной настройкой, определением локализации источника звука и созданием “звуковых объектов”[25]. Поскольку слуховой средний мозг играет центральную роль в качестве комплектующего звена и точки слияния мозговых сигналов от многих источников, он имеет важнейшее значение для осмысления звука.