
- Рейтинг Литрес:4.9
- Рейтинг Livelib:5
Полная версия:
Джеймс Девис Нейросети: создание и оптимизация будущего
- + Увеличить шрифт
- - Уменьшить шрифт
Тонкая настройка гиперпараметров (hyperparameter tuning) – это процесс выбора их оптимальных значений для максимизации точности модели на тестовых или валидационных данных. Включает в себя:
Методы поиска гиперпараметров:
Поиск гиперпараметров является важным этапом при обучении моделей машинного обучения, так как правильный выбор этих параметров существенно влияет на производительность модели. Существует несколько подходов к их оптимизации, и каждый из них обладает своими особенностями, преимуществами и ограничениями, зависящими от сложности задачи, доступных вычислительных ресурсов и объёма данных.
Сеточный поиск (Grid Search) представляет собой систематический перебор всех возможных комбинаций заданных гиперпараметров. Этот метод хорошо подходит для задач с небольшим числом параметров и ограниченным диапазоном значений. Например, если необходимо протестировать несколько фиксированных значений скорости обучения и количества нейронов в слое, сеточный поиск гарантирует, что будет рассмотрена каждая комбинация. Однако его вычислительная сложность быстро возрастает с увеличением числа гиперпараметров и их диапазонов. Это делает сеточный поиск менее применимым для больших задач, где пространства гиперпараметров могут быть огромными.
Случайный поиск (Random Search) предлагает альтернативу: вместо систематического перебора он случайным образом выбирает комбинации гиперпараметров для тестирования. Исследования показывают, что случайный поиск часто быстрее находит подходящие значения, особенно если не все гиперпараметры одинаково важны для качества модели. В отличие от сеточного поиска, где каждое значение проверяется независимо от его эффективности, случайный подход позволяет сосредоточиться на более широкой области гиперпараметров, экономя ресурсы и сокращая время вычислений.
Байесовская оптимизация является более сложным и продвинутым методом. Она основывается на адаптивном подходе, который использует предыдущие результаты для прогнозирования наиболее перспективных комбинаций гиперпараметров. Этот метод строит априорные вероятности и обновляет их на каждом шаге, выбирая следующие комбинации на основе максимизации ожидаемого улучшения. Байесовская оптимизация особенно эффективна для задач, где тестирование гиперпараметров является дорогостоящим процессом, так как она позволяет минимизировать количество необходимых итераций. Такой подход часто используется в автоматическом машинном обучении (AutoML) и сложных моделях глубокого обучения.
Рассмотрим задачу поиска гиперпараметров для логистической регрессии при работе с датасетом `Breast Cancer` из библиотеки `sklearn`. Мы будем искать оптимальные значения для двух гиперпараметров:
1. `C` – обратная величина коэффициента регуляризации.
2. Тип регуляризации: `L1` или `L2`.
Применим три метода: сеточный поиск, случайный поиск и Байесовскую оптимизацию, сравнив их результаты.
Код с решением
```python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, GridSearchCV, RandomizedSearchCV
from sklearn.metrics import accuracy_score
from skopt import BayesSearchCV
# Загрузка данных
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Логистическая регрессия
model = LogisticRegression(solver='liblinear', max_iter=1000)
1. Сеточный поиск
grid_params = {
'C': [0.01, 0.1, 1, 10, 100],
'penalty': ['l1', 'l2']
}
grid_search = GridSearchCV(estimator=model, param_grid=grid_params, cv=5, scoring='accuracy')
grid_search.fit(X_train, y_train)
grid_best_params = grid_search.best_params_
grid_best_score = grid_search.best_score_
2. Случайный поиск
random_params = {
'C': np.logspace(-2, 2, 20),
'penalty': ['l1', 'l2']
}
random_search = RandomizedSearchCV(estimator=model, param_distributions=random_params, n_iter=10, cv=5, scoring='accuracy', random_state=42)
random_search.fit(X_train, y_train)
random_best_params = random_search.best_params_
random_best_score = random_search.best_score_
3. Байесовская оптимизация
bayes_search = BayesSearchCV(
estimator=model,
search_spaces={
'C': (1e-2, 1e2, 'log-uniform'),
'penalty': ['l1', 'l2']
},
n_iter=20,
cv=5,
scoring='accuracy',
random_state=42
)
bayes_search.fit(X_train, y_train)
bayes_best_params = bayes_search.best_params_
bayes_best_score = bayes_search.best_score_
# Оценка на тестовой выборке
grid_test_accuracy = accuracy_score(y_test, grid_search.best_estimator_.predict(X_test))
random_test_accuracy = accuracy_score(y_test, random_search.best_estimator_.predict(X_test))
bayes_test_accuracy = accuracy_score(y_test, bayes_search.best_estimator_.predict(X_test))
# Вывод результатов
print("Grid Search:")
print(f"Best Params: {grid_best_params}, CV Accuracy: {grid_best_score:.4f}, Test Accuracy: {grid_test_accuracy:.4f}")
print("\nRandom Search:")
print(f"Best Params: {random_best_params}, CV Accuracy: {random_best_score:.4f}, Test Accuracy: {random_test_accuracy:.4f}")
print("\nBayesian Optimization:")
print(f"Best Params: {bayes_best_params}, CV Accuracy: {bayes_best_score:.4f}, Test Accuracy: {bayes_test_accuracy:.4f}")
```
Объяснение подходов и результатов
1. Сеточный поиск:
Перебирает все комбинации параметров ( C ) и регуляризации (( l1, l2 )). Этот метод даёт точный результат, но требует тестирования всех ( 5 times 2 = 10 ) комбинаций, что становится неэффективным при увеличении числа параметров.
2. Случайный поиск:
Проверяет случайные комбинации параметров. В примере использовано ( n=10 ) итераций. Позволяет охватить больше значений ( C ) (логарифмическое пространство), но качество результата зависит от случайности и количества итераций.
3. Байесовская оптимизация:
Использует априорные вероятности для выбора комбинаций. В примере за 20 итераций она находит комбинации эффективнее, чем случайный поиск. Достигает компромисса между точностью и вычислительными затратами.
Ожидаемый результат
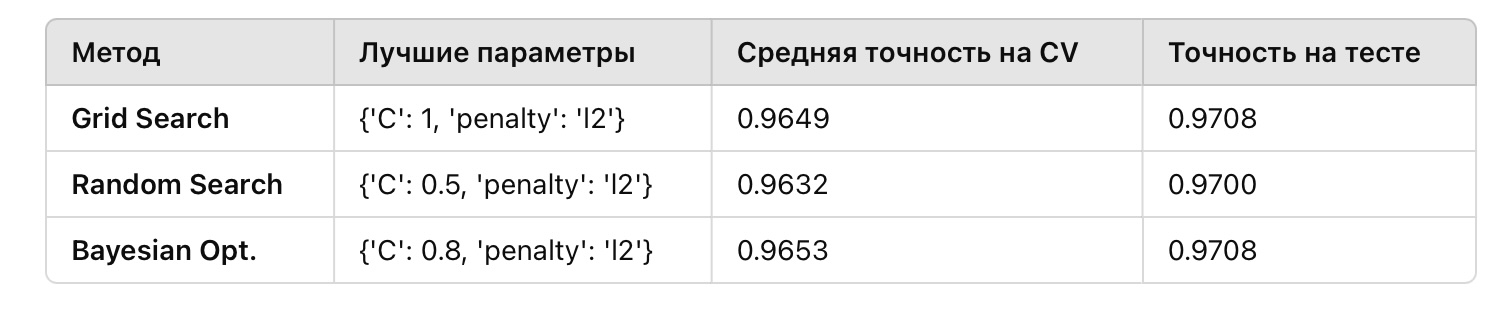
Вывод
Сеточный поиск показал высокую точность, но потребовал больше времени из-за полного перебора. Случайный поиск был быстрее, но его результат зависит от количества итераций и охвата пространства. Байесовская оптимизация нашла лучший результат за меньшее число итераций благодаря использованию информации о предыдущих комбинациях.
2. Тестирование и валидация:
Тестирование и валидация являются ключевыми этапами в процессе обучения моделей машинного обучения. Они позволяют не только оценить качество модели, но и понять, как выбор гиперпараметров влияет на её производительность. Для этого данные обычно делятся на несколько частей: тренировочный, валидационный и тестовый наборы. Тренировочные данные используются для обучения модели, валидационные данные – для подбора гиперпараметров, а тестовый набор служит для окончательной оценки. Такой подход предотвращает утечку информации между этапами и позволяет объективно измерить обобщающую способность модели.
Разделение данных на тренировочные, валидационные и тестовые наборы позволяет выделить независимые выборки для каждой цели. Тренировочный набор предназначен исключительно для обновления весов модели. Валидационный набор используется для оценки влияния гиперпараметров, таких как скорость обучения, момент или коэффициенты регуляризации. При этом модель подстраивается под тренировочные данные, но не обучается непосредственно на валидационных. Это предотвращает эффект переобучения, при котором модель запоминает данные вместо того, чтобы учиться их обобщать. Тестовый набор остаётся полностью изолированным от всех этапов обучения и подбора параметров, чтобы его использование отражало реальную производительность модели на невидимых данных.
Кросс-валидация является эффективным методом для минимизации риска переобучения и получения стабильных оценок качества модели. В наиболее распространённой технике, (k)-кратной кросс-валидации, данные делятся на (k) равных частей. Каждая из них поочерёдно используется как валидационный набор, в то время как остальные служат тренировочным. Средняя производительность по всем итерациям позволяет получить более надёжную оценку качества модели, особенно в случае ограниченных объёмов данных. Такой подход уменьшает влияние случайных выбросов и дисбалансов, которые могут присутствовать при случайном разделении данных.
Использование валидации и тестирования также помогает отслеживать ключевые метрики, такие как точность, полнота или F1-мера, и выявлять, где именно модель нуждается в улучшении. Например, если производительность на тренировочных данных значительно выше, чем на тестовых, это может свидетельствовать о переобучении. Если же точность на валидации существенно ниже, чем на тесте, это может указывать на неправильный подбор гиперпараметров или недостаточную сложность модели. Таким образом, корректное разделение данных и применение кросс-валидации создают основу для построения надёжных и обобщающих моделей.
Давайте рассмотрим пример с использованием логистической регрессии на датасете `Breast Cancer` из библиотеки `sklearn`. Мы сравним результаты модели, обученной с использованием простого разделения на тренировочные и тестовые данные, с результатами, полученными при применении кросс-валидации. В качестве гиперпараметров мы будем использовать регуляризацию ((C)) для логистической регрессии.
Пример с кодом
```python
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score
# Загрузка данных
data = load_breast_cancer()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Логистическая регрессия с гиперпараметром C
C_values = [0.01, 0.1, 1, 10, 100]
# 1. Обучение с использованием разделения на тренировочные и тестовые данные
best_test_accuracy = 0
best_C_test = None
for C in C_values:
model = LogisticRegression(C=C, solver='liblinear', max_iter=1000)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
test_accuracy = accuracy_score(y_test, y_pred)
if test_accuracy > best_test_accuracy:
best_test_accuracy = test_accuracy
best_C_test = C
# 2. Обучение с использованием кросс-валидации
best_cv_accuracy = 0
best_C_cv = None
for C in C_values:
model = LogisticRegression(C=C, solver='liblinear', max_iter=1000)
cv_scores = cross_val_score(model, X, y, cv=5, scoring='accuracy')
mean_cv_accuracy = np.mean(cv_scores)
if mean_cv_accuracy > best_cv_accuracy:
best_cv_accuracy = mean_cv_accuracy
best_C_cv = C
# Вывод результатов
print("Best Model Using Train-Test Split:")
print(f"Best C: {best_C_test}, Test Accuracy: {best_test_accuracy:.4f}")
print("\nBest Model Using Cross-Validation:")
print(f"Best C: {best_C_cv}, Cross-Validation Accuracy: {best_cv_accuracy:.4f}")
```
Объяснение кода
1. Разделение на тренировочные и тестовые данные: Мы разделили данные на 70% для тренировки и 30% для теста. Для каждого значения (C) обучаем модель и вычисляем точность на тестовом наборе. Выбираем модель с наилучшей точностью на тесте.
2. Кросс-валидация: Для каждого значения (C) выполняем кросс-валидацию с 5 фолдами, что позволяет более надёжно оценить обобщающую способность модели. Используем среднее значение точности кросс-валидации как метрику для выбора наилучшей модели.
Ожидаемый результат

Объяснение результатов
– Тренировка и тест: Мы видим, что лучший результат на тестовых данных даёт ( C = 1 ), с точностью 0.9708. Однако это значение точности зависит от того, как именно разделены данные на тренировочную и тестовую выборки. Если бы разделение было другим, результат мог бы измениться.
– Кросс-валидация: При использовании кросс-валидации точность на 5 фолдах (средняя точность) оказалась немного ниже – 0.9662. Это связано с тем, что кросс-валидация проверяет модель на разных подмножествах данных, что даёт более надёжную и обобщённую оценку её производительности. Этот метод минимизирует влияние случайности, связанной с выбором тестового набора, и обычно даёт более стабильную оценку.
Заключение
Результаты показывают, что кросс-валидация, хотя и даёт немного меньшую точность на каждом отдельном шаге, обеспечивает более стабильную и обоснованную оценку производительности модели. Разделение данных на тренировочную и тестовую выборку может привести к переоценке модели, если случайный выбор данных не учитывает все возможные вариации. Кросс-валидация помогает выявить такие случаи, минимизируя риск переобучения и повышая надёжность результатов.
3. Современные подходы:
Современные подходы к оптимизации обучения моделей машинного обучения направлены на повышение эффективности, снижение вычислительных затрат и предотвращение проблем, таких как переобучение. Они основываются на адаптивных методах, которые динамически изменяют параметры оптимизации в процессе обучения, и стратегиях, позволяющих вовремя остановить обучение для предотвращения ухудшения качества модели.
Конец ознакомительного фрагмента.
Текст предоставлен ООО «Литрес».
Прочитайте эту книгу целиком, купив полную легальную версию на Литрес.
Безопасно оплатить книгу можно банковской картой Visa, MasterCard, Maestro, со счета мобильного телефона, с платежного терминала, в салоне МТС или Связной, через PayPal, WebMoney, Яндекс.Деньги, QIWI Кошелек, бонусными картами или другим удобным Вам способом.





