



Денис Владимирович Соломатин
Основы статистической обработки педагогической информации
укороченный_вариант_таблицы <– select(flights,
year:day,
ends_with("delay"),
distance,
air_time)
Теперь добавим вычисляемые поля с информацией об опоздании, – задержке вылета минус задержка прилета, в минутах, и о средней скорости полёта. Обратите внимание, что можно ссылаться на столбцы, которые уже созданы. Если вдруг захотите сохранить только новые переменные, то используйте transmute() вместо mutate():
mutate(укороченный_вариант_таблицы,
опоздание = dep_delay – arr_delay,
скорость = distance / air_time * 60,
часы_полёта= air_time / 60,
опоздание_в_каждом_часе = опоздание / часы_полёта )
Существует много функций для создания новых переменных, которые можно комбинировать с mutate(). Ключевое их свойство заключается в том, что функция должна быть пригодной для обработки векторов, то есть она должна принимать вектор значений на входе и возвращать вектор с тем же количеством значений на выходе. Нет возможности перечислить все такие функции, но приведём некоторые из реально используемых.
Арифметические операторы: +, -, *, /, ^. Все они работают с векторами используя так называемые «правила рециркуляции», заключающиеся в том, что если один параметр короче другого, то произойдет автоматическое удлинение до равного размера путём клонирования короткого вектора достаточное количество раз. Это полезно, когда один из аргументов – число. В примере выше так были вычислены часы_полёта делением вектора на скаляр, а скорость умножением вектора на скаляр. Арифметические операторы также полезны в связке с агрегирующими функциями, о которых узнаете позже. Например, x / sum(x) вычисляет долю от общей суммы значений переменной, а y – mean(y) вычисляет отклонение величины от среднего.
Модулярная арифметика: %/% (целочисленное деление) и %% (остаток), здесь x == y * (x %/% y) + (x %% y). Модулярная арифметика очень удобный инструмент, потому что позволяет представлять большие целые числа сравнительно небольшими остатками. Например, в наборе данных flights можно выделить полные часы и оставшиеся минуты из общей продолжительности полёта, представленной в формате ЧЧММ или ЧММ (dep_time). Тогда вместо хранения и выполнения различных операций над одним большим числом, можно будет хранить и выполнять операции над двумя маленькими:
transmute(flights,
dep_time,
час = dep_time %/% 100,
минута = dep_time %% 100)
Логарифмические функции: log(), log2(), log10(), являются невероятно полезным преобразованием при работе с данными, диапазон которых охватывает несколько порядков наблюдаемой величины. Они также преобразуют мультипликативные операции в аддитивные, к этой особенности вернемся в разделе, посвященном моделированию. При прочих равных условиях, рекомендуется использовать функцию log2() так как её значения легко интерпретировать: разница в 1 на логарифмической линейке соответствует удвоению в исходном масштабе, а разница в -1 соответствует делению пополам.
Смещения: вперёд lead() и назад lag() позволяют просматривать последующие и предыдущие значения списка. Бывают необходимо вычислить приращение аргумента, например, х – lag(x), или проверить неизменность его значений, выражением x != lag(x). Смещения особенно полезны в сочетании с group_by(), но не будем забегать вперёд.
Накопительные и скользящие агрегаторы: R предоставляет функции для вычисления накапливаемой суммы cumsum(), произведения cumprod(), минимума cummin() и максимума cummax() элементов списка; кроме того, dplyr имеет функцию cummean() для вычисления среднего значения. Если нужны скользящие агрегаторы, когда сумма вычисляется по скользящему окну, то обращаются к функционалу пакета RcppRoll.
Логические сравнения: < (меньше), <= (не больше), > (больше), >= (не меньше), != (не равны), и == (равны), о них мы узнали ранее. Напомню лишь, если осуществляется сложная последовательность логических операций, то настоятельно рекомендуется сохранять промежуточные значения в отдельных вспомогательных переменных, чтобы проверить значение выражения на каждом шаге вычислений.
Ранжирование: объединяет в себе целый ряд функций, начиная с min_rank(), которая осуществляет вычисление простого порядкового номера (например, 1-й, 2-й, 3-й, 4-й). По умолчанию присваиваются меньшие номера меньшим значениям, но можно воспользоваться функцией desc() для обращения порядка значений аргумента, чтобы придать наибольшие порядковым номера наименьшим значениям элементов исходного списка. Если min_rank() не делает то, что нужно, загляните в описание функций ранжирования на страницах справки для получения более подробной информации.
Упражнения
1. На переменные, хранящие длительность перелёта, удобно смотреть, но трудно выполнять операции над ними, так как они не совсем порядковые числа, за 159 (которое символизирует 1 час, 59 минут) идет сразу 200 (2 часа ровно). Конвертируйте их в более удобное представление, чтобы хранилось общее количество минут начиная с полуночи.
2. Сравните значения часы_полёта с опоздание_в_каждом_часе. Что надеялись увидеть и что увидели? Что нужно сделать, чтобы исправить ошибку?
3. Найдите 10 самых задерживаемых рейсов, используя функции ранжирования. Как это связано? Внимательно прочитайте текст документация по min_rank().
4. Что возвращает 2:4 – 5:8 и почему?
5. Какие тригонометрические функции определены в R?
Последняя ключевая функция summary(), – она собирает сводную статистику по переменным при помощи вспомогательных функций. Например, среднее значение (mean) переменной dep_delay посчитается в переменную средняя_задержка_рейсов:
summarise(flights, средняя_задержка_рейсов = mean(dep_delay, na.rm = TRUE))
Ниже объясним подробно, что значит последний параметр na.rm = TRUE. Функция summary() не очень полезна, если используется без вспомогательной функции group_by(), которая переключает разбивает анализ всего набора данных на отдельные группы. Когда вызывается функция из пакета dplyr на сгруппированных данных, автоматически подключается group_by() для распараллеливания вычислений в целях повышения производительности и дробления информации. Например, если применить точно такой же вызов как в предыдущем примере, но для сгруппированных по дате записях, то на выходе получится средняя задержка по дням:
сгруппированные_по_дням <– group_by(flights, year, month, day)
summarise(сгруппированные_по_дням,
средняя_задержка_рейсов_по_датам = mean(dep_delay, na.rm = TRUE))
Вызов функций group_by() совместно с summary() чаще всего используется при работе в пакете dplyr для получения статистических отчетов по группам. Но прежде, чем погрузиться в детали, дополнительно изложим одну техническую идею, касающуюся обработки информации путём её направления по специальным каналам. Представьте, что хотим исследовать закономерность между расстоянием и средней задержкой рейса для каждого пункта назначения. Опираясь на имеющиеся знания о возможностях dplyr, для этого достаточно использовать такой код:
группы_рейсов_по_месту_назначения <– group_by(flights, dest)
задержки <– summarise(группы_рейсов_по_месту_назначения,
опозданий = n(), средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE))
Оставим в выборке рейсы имеющие более сотни регулярных опозданий и, например, не на московских направлениях:
задержки <– filter(задержки, опозданий > 100, dest != "MSK")
Визуализируем оставшиеся записи:
ggplot(data = задержки, mapping =
aes(x = средняя_длина_маршрута, y = средняя_задержка)) +
geom_point(aes(size = опозданий), alpha = 1/5) +
geom_smooth(se = FALSE)
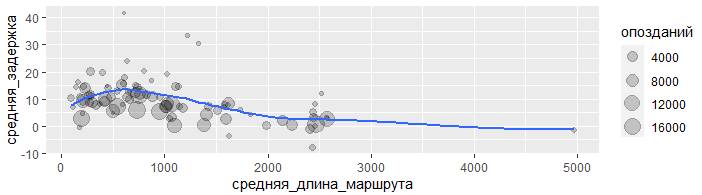
Похоже, что задержки растут с увеличением расстояния до ~750 миль, а затем сокращаются. Неужели, когда рейсы становятся длиннее, появляется возможность компенсировать опоздание находясь в полёте?
Предварительно было пройдено три вспомогательных этапа подготовки данных:
1. Сгруппированы рейсы по направлениям.
2. В каждой из групп усреднены расстояния, длительность задержки и вычислено количество опоздавших рейсов.
3. Отфильтрованы шумы и аэропорт, который не подчиняется законам логики.
Этот код немного перегружен, так как каждому промежуточному блоку данных присвоено имя. Вспомогательные таблицы сохранялись, даже когда их содержимое не востребовано на заключительном этапе, и замедляли анализ. Но есть отличный способ справиться с обозначенной проблемой посредством настройки каналов передачи данных служебным оператором %>%:
задержки <– flights %>%
group_by(dest) %>%
summarise(
опозданий = n(),
средняя_длина_маршрута = mean(distance, na.rm = TRUE),
средняя_задержка = mean(arr_delay, na.rm = TRUE) ) %>%
filter(опозданий > 100, dest != " MSK ")
Такой синтаксис фокусирует внимание исследователя на выполняемых преобразованиях, а не на том, что получается на каждом из вспомогательных этапов, и делает код более читаемым. Это звучит как ряд предписаний: сгруппируй, после этого подведи итоги, после этого отфильтруй полученное. Как подсказывает здравый смысл, можно читать %>% в коде как «после этого». По сути же, формируется информационный канал последовательной передачи данных на обработку от одной функции через другую к третьей. Технически, x %>% f(y) превращается в f(x, y), а x %>% f(y) %>% g(z) превращается в композицию функций g(f(x, y), z) и так далее, что позволяет использовать канал для объединения нескольких операций в одну, которую можно читать слева направо, сверху вниз. Будем часто пользоваться каналами, так как это значительно упрощает читаемость кода, разберём их более подробно в соответствующем разделе.
Работа с каналами это одна из ключевых особенностей tidyverse. Единственным исключением является ggplot2, так как библиотека была написано до появления такой возможности в R. К сожалению, являющаяся наследником ggplot2 библиотека ggvis хотя и поддерживает работу с каналами, но пока еще не в полной мере.
Внимательный читатель наверняка задавался вопросом о смысле и предназначении аргумента na.rm. Что будет, если его не писать? Получим много пропущенных значений! Дело в том, что агрегационные функции подчиняются обычному правилу пропущенных значений: если на входе есть какое-либо отсутствующее значение, то выход будет отсутствующим значением. К счастью, все функции агрегации имеют аргумент na.rm, который удаляет пропущенные значения перед началом вычислений. В том случае, где пропущенные значения представляют отмененные рейсы, мы также могли бы решить эту проблему, сначала удалив отмененные рейсы. Сохраним этот набор данных, чтобы использовать его повторно в нескольких следующих нескольких примерах:
неотмененные <– flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
Сгруппируем получившиеся данные о неотмененных рейсах по датам и посчитаем среднюю задержку на каждую дату в отдельности:
неотмененные %>%
group_by(year, month, day) %>%
summarise(средняя_задержка = mean(dep_delay))
Всякий раз, когда осуществляется подобная агрегация, правилом хорошего тона является добавление счетчика числа учтенных значений функцией n(), либо путём подсчета используемых непустых значений командой sum(!is.na(x)). Таким способом можно удостовериться, что не делается поспешных выводов на основании выборок очень малых объемов. Например, сгруппировав рейсы по бортовому номеру, хранящемуся в переменной tailnum из таблицы неотмененных рейсов, на графике посмотрим каковы самые высокие задержки в среднем на борт:
задержки <– неотмененные %>%
group_by(tailnum) %>%
summarise(
средняя_задержка = mean(arr_delay)
)
ggplot(data = задержки, mapping = aes(x = средняя_задержка)) +
geom_freqpoly(binwidth = 5)
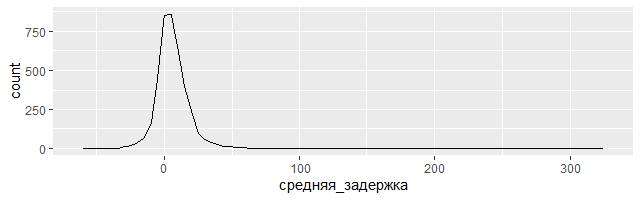
Неужели много самолетов со средней задержкой рейса более 5 часов (300+ минут)? На самом деле не всё так печально, как могло показаться при поверхностном ознакомлении. Можно получить более глубокое представление об опозданиях, если нарисовать диаграмму рассеяния количества рейсов относительно средней задержки:
задержки <– неотмененные %>%
group_by(tailnum) %>%
summarise(
средняя_задержка = mean(arr_delay, na.rm = TRUE),
количество_выполненных_рейсов = n()
)
ggplot(data = задержки, mapping = aes(x = количество_выполненных_рейсов,
y = средняя_задержка)) +
geom_point(alpha = 1/15)
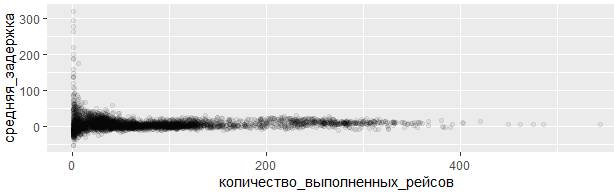
Неудивительно, что на частых рейсах задержек практически не наблюдается, а в основном задерживаются те борта, чьих рейсов мало. Что характерно, и в принципе соответствует статистическому закону больших чисел: всякий раз, когда ищется среднее значение (или другая сводка) в сравнении с размером группы, приходят к выводу, что вариативность вычисленного значения уменьшается по мере увеличения объема выборки.
Именно поэтому, когда решаете аналогичные задачи, полезно отфильтровывать группы с наименьшим количеством наблюдений, тогда можно будет увидеть общие закономерности и уменьшить выбросы значений на малых группах. На примере следующего кода будет демонстрирован удобный шаблон интеграции ggplot2 с каналами в dplyr. Немного странным может показаться смешение стилей %>% и +, дело привычки, со временем это станет естественным. Отфильтруем на предыдущем графике экспериментальные самолёты с малым количеством вылетов, не превышающим 33:
задержки %>% filter(количество_выполненных_рейсов > 33) %>%
ggplot(mapping = aes(x = количество_выполненных_рейсов,
y = средняя_задержка)) +
geom_point(alpha = 1/15)
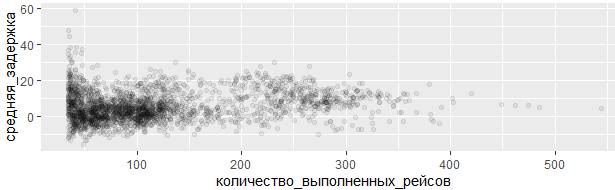
Полезным сочетанием клавиш RStudio является Ctrl + Shift + P, для повторной отправки ранее отправленного фрагмента из редактора в консоль. Это очень удобно, когда экспериментируете с граничным значением 33 в приведенном выше примере: отправляете весь блок в консоль нажатием Ctrl + Enter, а затем изменяете значение границ фильтрации на новое и нажимаете Ctrl + Shift + P, чтобы повторно отправить весь блок в консоль.
Есть еще одна хрестоматийная иллюстрация к применению изложенного метода. Рассмотрим среднюю эффективность бейсбольных игроков относительно количества подач, когда они находятся на базе. Воспользуемся данными из пакета Lahman для вычисления среднего показателя эффективности (количество попаданий / количество попыток) каждого ведущего игрока бейсбольной лиги.
 Историческая справка. Не сказать чтобы бейсбол был нашей национальной забавой, но многие в России знают «сколько пинчеров на базе», и именно россиянин, уроженец Нижнего Тагила, Виктор Константинович Старухин стал первым питчером, кто одержал 300 побед в японской бейсбольной лиге, являясь одним из лучших бейсболистов мира в 20 веке.
Историческая справка. Не сказать чтобы бейсбол был нашей национальной забавой, но многие в России знают «сколько пинчеров на базе», и именно россиянин, уроженец Нижнего Тагила, Виктор Константинович Старухин стал первым питчером, кто одержал 300 побед в японской бейсбольной лиге, являясь одним из лучших бейсболистов мира в 20 веке.
Когда строится график визуализирующий уровень мастерства игроков, измеряется среднее значение эффективных попаданий по мячу по отношению к общему количеству предпринятых попыток, возникает две статистические предпосылки:
1. Как было в примере с самолётами, вариативность показателей уменьшается при увеличении количества наблюдений.
2. Существует положительная корреляция между результативностью и элементарно предоставляемой возможностью бить по мячу. Дело в том, что команды контролируют свой состав, поэтому очевидно, что на поле выходят только лучшие игроки из лучших.
Предварительно преобразуем сведения об ударах игроков в табличную форму, так они легче воспринимаются:
удары <– as_tibble(Lahman::Batting)
эффективность <– удары %>%
group_by(playerID) %>%
summarise(
результативность = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
возможность = sum(AB, na.rm = TRUE)
)
эффективность %>%
filter(возможность > 100) %>%
ggplot(mapping = aes(x = возможность, y = результативность)) +
geom_point() +
geom_smooth(se = FALSE)
Функция geom_smooth() здесь формирует график методом обобщенных аддитивных моделей с интегрированной оценкой гладкости (method = "gam") рассчитывая значения по формуле formula = y ~ s(x, bs = "cs"), так как имеется более 1 000 наблюдений.
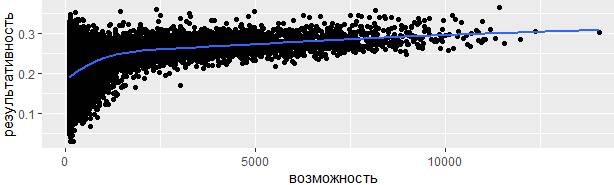
Особый интерес вызывает ранжирование результатов. Если наивно отсортировать показатели эффективности по убыванию результативности, то первыми с самой лучшей результативностью окажутся скорее везучие, а не квалифицированные игроки, за всю карьеру сделавшие лишь 1 удар, но при этом попавшие по мячу:
эффективность %>%
arrange(desc(результативность))
Можно найти хорошее объяснение этого парадокса в пословице «новичкам везёт». Используя простые инструменты, подсчет количества одинаковых значений, их суммирование, можно долго искать любопытные закономерности, но R предоставляет и много других полезных функций для генерации статистических отчетов:
Выше использовалась функция, вычисляющая среднее значение mean(x), но вычисляющая медианное значение функция median(x) тоже бывает полезна. Ведь среднее как 36.6° по больнице, а медиана – это величина, относительно которой 50% значений x находится выше, и 50% находится ниже, что гораздо информативнее. Иногда полезно комбинировать подобные функции с логическим условием. Мы еще не говорили о таких вещах как подмножество значений, этому можно посвятить целый раздел, пока лишь приведем наглядный пример, на тех же неотмененных авиарейсах, сгруппированных по дате вылета.
Отрицательные значения «задержки» рейса символизируют прибытие с опережением графика, оказывается, такое тоже бывает:
неотмененные %>% group_by(year, month, day) %>%
summarise(
средняя_задержка = mean(arr_delay),
средняя_положительная_задержка = mean(arr_delay[arr_delay > 0])
)
Особый интерес вызывают функции вычисления стандартного отклонения sd(x), меры разброса наблюдаемой величины, вычисления интерквартильного размаха IQR(x) и вычисления медианы абсолютного отклонения mad(x), которые являются надежными эквивалентами друг друга и могут быть полезны, если у данных есть выбросы. Любопытно, почему расстояние до одних пунктов назначения варьируются сильнее, чем до других, являя собой не иначе как чудеса телепортации:
неотмененные %>% group_by(dest) %>%
summarise(среднеквадратическое_отклонение_дистанции = sd(distance)) %>%
arrange(desc(среднеквадратическое_отклонение_дистанции))
Функции поиска минимального значение min(x), первого квантиля quantile(x, 0.25), вычисления максимума max(x), неизменные спутники при построении ранжирования. Квантили являются обобщением медианы. Так, например, quantile(x, 0.25) найдет значение x, которое больше чем 25% значений из всех возможных значений анализируемой переменной, и меньше чем остальные 75%.
Найдем время отправления первого и последнего рейса каждый день:
неотмененные %>% group_by (year, month, day) %>%
summarise( первый_рейс = min (dep_time),
последний_рейс = max (dep_time) )
Измерение позиции указателя на элементах списка осуществляется функциями first(x) для выбора первого элемента переменной x, nth(x, n) для выбора n-ного, last(x) для выбора последнего. Они работают аналогично адресации массивов в нотации x[1], x[n] и x[length(x)], но возвращают значение аргумента default, если запрошенная позиция не существует. Например, не увенчается успехом попытка получить значение такого элемента, как неотмененные$dep_time[length(неотмененные$dep_time)+1], вернув NA, неопределенное значение переменной, но при этом на выходе даст «Бинго!» вызов nth(неотмененные$dep_time,length(неотмененные$dep_time)+1, default = "Бинго!").
Следующая функция range() дополняет фильтрацию. Приведём пример, в котором сначала все записи группируются по датам и ранжируются, а потом фильтрация оставляет в строках значения, имеющие наибольший и наименьший из рангов в группе. Для сравнения, вызов функции range(неотмененные$dep_time) вернёт список, состоящий из наибольшего и наименьшего значений переменной dep_time:
неотмененные %>% group_by (year, month, day) %>%
mutate(ранжирование = min_rank(desc(dep_time))) %>%
filter(ранжирование %in% range(ранжирование) )
Ранее в вычислениях уже использовалась функция n(), которая вызывается без аргументов, и возвращает размер текущей группы. Чтобы посчитать количество непустых значений в группе х, используется конструкция sum(!is.na(x)), а чтобы подсчитать число различных (уникальных) значений вызывается n_distinct(x). Например, вычислим, какие направления имеют наибольшее количество перевозчиков:
неотмененные %>% group_by(dest) %>%
summarise(перевозчики= n_distinct(carrier)) %>%
arrange(desc(перевозчики))
Подсчеты значений настолько востребованы, что в пакете dplyr выделена отдельная функция count() для этого. Подсчитаем число повторений каждого направления, хранящихся в переменной dest таблицы неотмененных авиарейсов:
неотмененные %>% count(dest)
При необходимости указывается параметр веса каждого слагаемого (wt). Например, это можно использовать для подсчета общей суммы количества миль, которые пролетел самолет с фиксированным бортовым номером, взятым из поля talinum в базе неотмененных рейсов:
неотмененные %>% count(tailnum, wt = distance)
Подсчет числа значений удовлетворяющих логическому выражению, sum(x > 777), или их среднее количество, mean(y == 0), предполагает, что в связке с числовыми функциями TRUE преобразуется в 1, а FALSE в 0. Это делает функции sum() и mean() очень востребованными: sum(x) возвращает количество значений TRUE для аргумента x, а mean(x) возвращает их долю. Вычислим, сколько неотмененных рейсов было до 6 утра по данным за каждые сутки, это обычно указывает на задержку с предыдущего дня:
неотмененные %>% group_by(year, month, day) %>%
summarise(утренние_рейсы = sum(dep_time < 600))
Какова доля неотмененных рейсов, задержавшихся более часа:
неотмененные %>% group_by(year, month, day) %>%
summarise(часовая_задержка = mean(arr_delay >= 61))
При группировании по нескольким переменным, каждая новая сводка выносится на новый уровень группировки. Это облегчает восприятие и постепенно упрощает данные:
группы_по_дням <– group_by(flights, year, month, day)
(сводка_по_дням <– summarise(группы_по_дням, полётов = n()))
(сводка_по_месяцам <– summarise(сводка_по_дням, полётов = sum(полётов)))
(сводка_за_год <– summarise(сводка_по_месяцам, полётов = sum(полётов)))
Будьте осторожны при постепенном сворачивании выборки, это приемлемо для итоговых сумм и счетчиков, но нужно не забывать про такие характеристики, как медиана и отклонение, анализ результатов свёртки принципиально невозможен в ранговой статистике. Другими словами, сумма внутригрупповых сумм является общей суммой, но медиана внутригрупповых медиан не будет равна общей медиане, о последнем свойстве порой сознательно забывают при выведении нужных результатов из различных голосований. Если потребуется отменить группировку, и вернуться к операции с негруппированными данными, то используется функция ungroup():
группы_по_дням %>%
ungroup() %>% # разгруппируем данные обратно
summarise(полётов = n()) # подсчитаем все полёты
Упражнения
1. Примените мозговой штурм чтобы изобрести как минимум 7 различных способов анализа типовых причин серийной задержки рейсов, учитывая следующие сценарии:
а) в 50% случаев вылет осуществляется на 15 минут раньше запланированного, и в 50% рейс задерживается на 15 минут.
б) рейс всегда опаздывает на 10 минут.
в) 50% рейсов вылетает на 30 минут раньше, и 50% на 30 минут опаздывает.
г) в 99% случаев рейс выполняется точно по графику, а в оставшемся 1% происходит опоздание на 2 часа.
Что более важно для пассажира, задержка прибытия или задержка вылета, а для работы аэропортов?
2. Придумайте альтернативный способ решения той же задачи, что и в примерах неотмененные %>% count (dest), неотмененные %>% count(tailnum, wt = distance), но без использования функции count().
3. Следующее определение отмененных рейсов не оптимально:
отмененные <– flights %>%
filter( is.na(dep_delay) | is.na(arr_delay) )
Почему? Какая колонка важнее в этом случае: задержка времени вылета (dep_delay) или задержка времени прилёта (arr_delay)?
4. Посмотрите на ежедневное количество отмененных рейсов. Есть ли здесь закономерность? Связана ли доля отмененных рейсов со средней задержкой?
5. Какой перевозчик (carrier) имеет худшую статистику по задержкам рейсов? Можно ли обнаружить зависимость плохих статистических показателей аэропортов от качества работы перевозчиков? Если да, то как, если нет, то почему?
6. За что отвечает аргумент выбора способа сортировки sort в функции count()? Когда уместно его использование?
Группирование данных бывает полезным в сочетании с функцией подведения итогов summarise(), но есть удобные шаблоны и для операций преобразования mutate() с фильтрацией filter(). Вспомним про укороченный_вариант_таблицы <– select(flights, year:day, ends_with("delay"), distance, air_time), хранящий лишь сведения об опозданиях, и выделим по 5 злостных нарушителей регламента полётов на каждый день:
укороченный_вариант_таблицы %>% group_by(year, month, day) %>%
filter(rank(desc(arr_delay)) <= 5)
Сгруппируем рейсы по направлениям и оставим лишь такие группы, объем которых превышает некоторое пороговое значение:
( популярные_направления <– flights %>% group_by(dest) %>%
filter(n() > 17282) )
Преобразуем их для дальнейшего вычисления метрических характеристик внутри каждой из полученных групп:
популярные_направления %>% filter(arr_delay > 0) %>%
mutate(относительная_задержка = arr_delay / sum(arr_delay)) %>%
select(year:day, dest, arr_delay, относительная_задержка)
Как видим, группирующая фильтрация приводит к изменениям, за которыми следует обычная фильтрация. Желательно избегать подобного, за исключением поверхностного анализа данных, в противном случае бывает трудно проверить корректность выполненных манипуляций. Функции, которые наиболее естественно работают со сгруппированными данными, например mutate() и filter(), называются оконными функциями, в отличие от резюмирующих функций типа summary(). Узнать больше об оконных функциях можно вызвав соответствующий раздел справки, введя консольную команду vignette("window-functions").
Упражнения
1. Вернитесь к примерам использования функций mutate() и filter() со списками. Как меняется результат каждой операции при создании промежуточных групп данных?
2. Какой самолет (бортовой номер) имеет рекордно худшее время вылета?
3. В какое время суток нужно лететь, чтобы максимальное избежать задержек?
4. Для каждого пункта назначения вычислите суммарное время задержек. Для каждого рейса вычислите долю его задержек в общей сумме.
5. Задержки обычно коррелируют по времени: после того как вызвавшая первоначальную задержку проблема была решена, более поздние рейсы задерживаются, чтобы разрешить ранним покинуть аэропорт. При помощи функции lag() исследуйте, как задержка каждого рейса связана с задержкой непосредственно предшествующего.
6. Просмотрите каждый пункт назначения. Можно ли найти рейсы, долетевшие подозрительно быстро? То есть те полеты, которые потенциально представляют собой ошибку ввода данных. Вычислите долю воздушного времени полета относительно самого скоростного рейса до выбранного пункта назначения. Какие рейсы были дольше всего задержаны в воздухе?
7. Найдите все пункты назначения, в которые одновременно следовало как минимум два перевозчика. Используйте эту информацию для ранжирования перевозчиков.
8. У каждого самолета найдите количество рейсов до первой задержки более 1 часа.


