



Денис Владимирович Соломатин
Основы статистической обработки педагогической информации
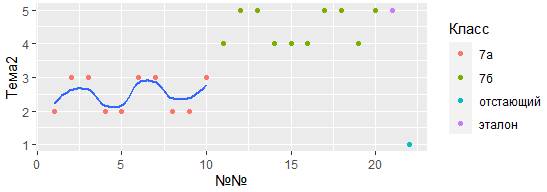
В приведенном примере, гладкая линия охватывает только подмножество исходного набора данных. Локальный аргумент в geom_smooth() переопределяет глобальный аргумент отбора данных в ggplot().
Разберем как работает фильтрация чуть позже, на данный момент достаточно понять, что эта команда выбирает только учеников 7а класса, а опция se = FALSE отключает подсветку доверительного интервала.
Упражнения
1. Какую функцию из категории geom_ вы бы использовали для построения линейного графика? А для круговой, лепестковой диаграммы, гистограммы?
2. Что меняет опция show.legend = FALSE? Что происходит если её убрать? Как думаете, почему она использовалась ранее в примере?
3. Что делает аргумент se для функции geom_smooth ()?
4. Воссоздайте код R, необходимый для создания следующего рисунка и дайте ему соответствующую интерпретацию:
Подробнее остановимся на гистограммах, – так называемых прямоугольных диаграммах. Они кажутся простыми, но интересны тем, что открывают потенциальные закономерности в наблюдаемой статистике. Рассмотрим базовую линейчатую диаграмму, построенную следующим образом с помощью функции geom_bar(). Принимая во внимание, как Роберт Грин Ингерсолл (1833-1899) за оффлайн-школой закрепил хлёсткое определение: «Школа – это место, где шлифуют булыжники и губят алмазы», – медленно, но верно приобщаясь к принципиально иной онлайн-школе попробуем всё же научиться правильному обращению с алмазами. На диаграмме ниже будет показано общее количество обработанных алмазов – бриллиантов, хранящихся в предустановленной с пакетом ggplot2 базе данных, сгруппированных по огранке.
База данных о бриллиантах (diamonds) поставляется в комплекте ggplot2 и содержит информацию о ~54 000 дорогостоящих украшениях, включая цену, размер в каратах, цвет, прозрачность и огранку каждого из них. Несомненно, онлайн-учителю любой по карману. Диаграмма показывает, что бриллиантов с идеальной огранкой имеется гораздо больше, чем с черновой обработкой:
ggplot (data = diamonds) +
geom_bar (mapping = aes (x = cut, colour = diamonds$color))
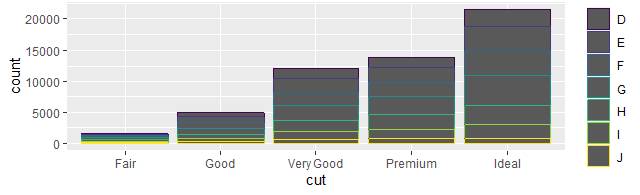
На оси x диаграмма показывает огранку (cut) алмазов. На оси y с учетом цвета отображается их общее количество (count), но в базе данных не хранится поле count. Откуда же берется информация о количестве? Одни алгоритмы графопостроителей, например диаграммы рассеяния, формируют изображение по необработанным значениям исходного набора данных. Другие, например гистограммы, вычисляют новые вспомогательные значения при построении. Гистограммы, как частотные диаграммы, преобразуют ваши данные, осуществляют подсчеты числа записей определенного типа, будто раскладывая их по ящикам. При масштабировании последних диаграмма адаптируется к объему исходных данных, а затем строятся прямоугольники нужного размера. Вычисляется статистическая сводка выборки и после этого рисуется специально отформатированный прямоугольник. Алгоритм, используемый при вычислении новых значений для графиков, определяется параметром stat, сокращенно от «статистическое преобразование». В примере ниже показано, как это работает с geom_bar(). Вы можете узнать, какое статистическое преобразование использует та или иная функция, проверив значение по умолчанию аргумента stat. Например, в документации по функции ?geom_bar сказано, что её значение по умолчанию для аргумента stat это count, то есть geom_bar() использует функцию stat_count(), описанную на той же странице, что и geom_bar(), и если прокрутить вниз, то можно найти раздел «вычисляемые переменные», в котором сказано, что вычисляются две новые вспомогательные переменные: count и prop.
Как правило, префиксы geom_ и stat_ взаимозаменяемы. Например, можно запустить предыдущий пример с использованием stat_count() вместо geom_bar(). Это работает, потому что каждая функция категории geom_ имеет параметр stat по умолчанию, а каждая функция категории stat_ имеет двойственный параметр geom по умолчанию. Это означает, что можно используйте функции построения графиков, не беспокоясь о лежащих в их основе статистических преобразованиях данных. Есть три причины, по которым может потребоваться использовать параметр stat в явном виде:
1) Возможно, захотите переопределить используемое по умолчанию статистическое преобразование. В коде ниже, заменено значение аргумента stat в geom_bar() с count (принятого по умолчанию) на identity. Это позволяет сопоставить высоту баров с необработанным значением переменной. Когда говорят о столбцевой диаграмме, можно иметь ввиду такой тип гистограммы, в котором высота столбика уже присутствует в данных, либо предыдущую диаграмму, на которой высота генерируется с помощью подсчет строк.

Историческая справка.
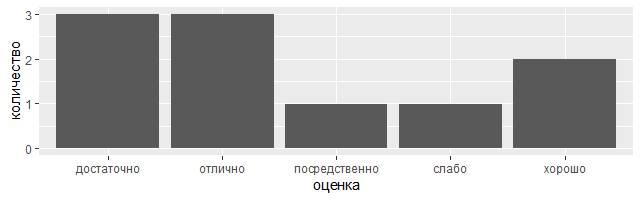
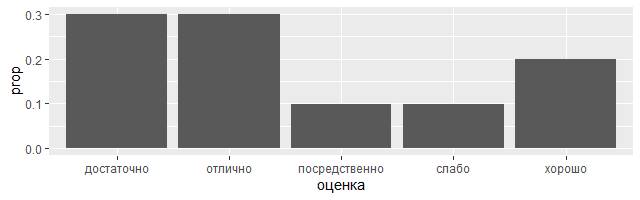
Как известно, из всех систем оценивания знаний в России поныне жива 5-балльная, которая была в 1837 году официально установлена Министерством народного просвещения. Положим, что продемонстрированные воспитанницами на одном из уроков математики в Серпуховской женской гимназии результаты были занесены в следующую демонстрационную таблицу.
library(tidyverse)
demo <– tribble( ~оценка, ~количество,
"слабо", 1,
"посредственно", 1,
"достаточно", 3,
"хорошо", 2,
"отлично", 3 )
ggplot(data = demo) +
geom_bar(mapping = aes(x = оценка, y = количество), stat = "identity")
Не волнуйтесь, что не видели <– tribble раньше. Из контекста понятно назначение этих операторов, но что именно они делают в общем случае, будет подробно рассказано чуть позже.
2) Возможно, потребуется переопределить сопоставление по умолчанию от трансформированных переменных. Например, можете чтобы отобразить линейчатую диаграмму частот, а не количества:
library(tidyverse)
demo <– tribble( ~оценка, "слабо", "посредственно",
"достаточно", "достаточно", "достаточно",
"хорошо", "хорошо",
"отлично", "отлично", "отлично" )
ggplot (data = demo) +
geom_bar (mapping = aes (x = оценка, y = stat (prop), group = 1))
Чтобы найти полный список переменных, вычисляемых в статистике, достаточно заглянуть в раздел справки, озаглавленный как «вычисляемые переменные».
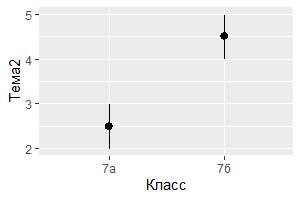
3) Возможно, захотите извлечь больше статистической информации в вашем коде. Например, если использовать функцию stat_summary(), то будет получена дополнительная описательная статистика, которую можно показать на диаграмме. Следующий фрагмент кода выберет из тестовой базы успеваемость обучающихся в 7а или 7б классах по теме 2, найдет наименьшую оценку в каждом классе, наибольшую и медианное значение. После этого найденные статистики будут отображены на диаграмме соответствующими линиями:
ggplot(data = My_table[My_table$Класс == "7а" | My_table$Класс == "7б",]) +
stat_summary(
mapping = aes(x = Класс, y = Тема2),
fun.ymin = min,
fun.ymax = max,
fun.y = median
)
На данном этапе развития проекта, пакет ggplot2 предоставляет пользователям более 20 статистик. Каждое значение параметра stat является функцией, поэтому получить справку по ним можно обычным способом, например, введя ?stat_bin в консоли.
Упражнения
1. Что такое geom по умолчанию, связанный с stat_summary()? Как переписать код из примеров, чтобы использовать функцию начинающуюся с geom_ вместо stat_?
2. Что делает функция geom_col()? Чем она отличается от geom_bar()?
3. Большинство значений параметров geom и stat парные, и почти всегда используется вместе. Ознакомьтесь с документацией и составьте список всех пар, что у них общего?
4. Какие вспомогательные переменные вычисляет функция stat_smooth()? Какие параметры контролируют её поведение?
5. В диаграмме частот из примера установлено значение group = 1. Зачем? Другими словами, что будет нарисовано без указания этого параметра?
Есть еще одна интересная опция, связанная с гистограммами. Можно раскрасить её элементы с помощью любого цвета, указав значения параметров цвета границы (color) и заливки (fill). Обратите внимание, что произойдет, если сопоставите настройки заливки с отдельной переменной: каждый цветной прямоугольник будет представлять комбинированную информацию из двух параметров.
Регулировка положения прямоугольников задается соответствующим аргументом (position). Если его не менять, то построится столбчатая диаграмма, но можете использовать один из трех других вариантов: используемый по умолчанию (identity), развернутый по горизонтали (dodge) или с заполнением прямоугольников до равной высоты (fill). Указание position = "identity" будет размещать каждый объект ровно там, где он попадает в контекст графика. Это не очень полезно в случае детализированных прямоугольников, потому что фрагменты могут перекрываться между собой внутри одного прямоугольного столбика. Чтобы увидеть это перекрытие, можно сделать заливку полупрозрачной, придав уровню прозрачности (alpha) небольшое значение, либо использовав настройку fill = NA. Такое расположение прямоугольников полезно для 2d-примитивов, в виде точек. Указание position = "fill" работает как штабелирование, оно сделает каждый набор прямоугольников одинаковой суммарной высоты. Такой подход значительно облегчает сравнение пропорций внутри групп. И наконец position = "dodge" нарисует перекрывающиеся объекты непосредственно рядом друг с другом, что облегчает сравнение индивидуальных значений.
Заключительный тип регулировки является не очень полезным для гистограмм, но может быть очень полезен для диаграмм рассеяния. Вспомните примеры из первой главы. неужели не заметили, что график отображает только 126 точек, хотя в базе данных об автомобилях записано 234 значения. Как в известном письме на Балабановскую спичечную фабрику: «Я 11 лет считаю спички у вас в коробках – их то 59, то 60, иногда 58. Вы там сумасшедшие что ли все???». Источник обозначенной проблемы в том, что значения x и y округлены. В результате, многие точки появляясь на сетке перекрывают друг друга. Эта проблема известна как «overplotting». Такое расположение делает график трудным для понимания, когда на нём находится много данных. Распределены ли точки данных поровну на всем графике, или есть комбинация координат x и y, которая содержит 109 значений одновременно? Проблемы можно избежать, переключив регулировку положения в режим дрожания (jitter). Настройка position = "jitter" добавляет небольшое количество случайных шумов в каждую точку. Это распространяется на всю поверхность и поэтому не окажется двух точек, которые, вероятно, получат одинаковое количество случайных шумов. Добавление случайности кажется странным способом улучшения изображения, но несмотря на то, что график получится менее точным на малом масштабе, в больших масштабах график становится более иллюстративным. Поскольку это такая полезная опция, в ggplot2 внесена отдельная краткая форма записи выражения geom_point(position = "jitter"), вместо него лучше использовать geom_jitter().
Чтобы узнать больше о регулировке положения, загляните в раздел справки, посвященный каждой из перечисленных настроек.
Упражнения
1. Какие параметры функции geom_jitter() регулируют количество дрожаний?
2. Примените geom_jitter() и geom_count(), сравните полученные результаты.
3. Какая настройка положения используется в функции geom_boxplot() по умолчанию? Создайте на её основе визуализацию своего набора данных.
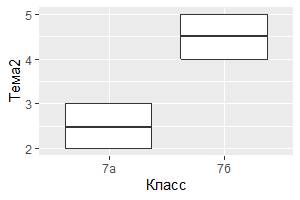
Заключительной частью настоящей главы рассмотрим настройку систем координат для построения графиков. Система координат, пожалуй, имеет самый сложный функционал в ggplot2. Естественно, по умолчанию используется прямоугольная декартова система координат, в которой значения x и y позволяют однозначно определить местоположение каждой точки. Но есть и другие системы координат, которые иногда полезны. Функция coord_flip() меняет местами оси x и y. Это пригодится, если хотите нарисовать горизонтальные боковые диаграммы,а также полезно для длинных графиков, которые трудно подгонять без перекрытия по оси x.
# левый график
ggplot(data = My_table[My_table$Класс == "7а" | My_table$Класс == "7б",],
mapping = aes(x = Класс, y = Тема2)) +
geom_boxplot()
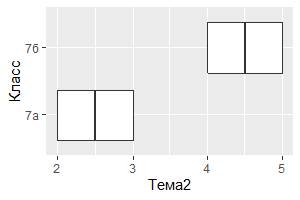
# правый график
ggplot(data = My_table[My_table$Класс == "7а" | My_table$Класс == "7б",],
mapping = aes(x = Класс, y = Тема2)) +
geom_boxplot() +
coord_flip()
Функция coord_quickmap() устанавливает соотношение сторон правильным для карт. Это очень важно, если строите планы карт местности с помощью ggplot2. Например:
1) Установите пакет карт, если не использовали его ранее.
install.packages("maps")
2) Подключите соответствующую библиотеку.
library(maps)
3) Заполните переменную картографическими данными.
ru <– map_data("world")
4) Теперь можно получить изображение карты в корректном масштабе
ggplot(ru, aes(long, lat, group = group)) +
geom_polygon(alpha=1/5, fill = "green", color = "black") +
coord_quickmap()
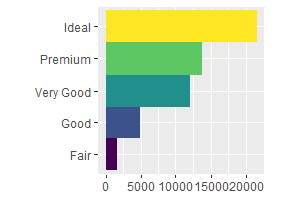
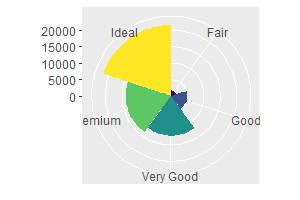
Функция coord_polar() переключает графопостроитель в режим полярных координат. Полярный координаты позволяют визуализировать интересную связь между линейчатой и круговой диаграммами. Напоследок вернёмся к тому, с чего начинали, – алмазам и их популярности в зависимости от качества. В следующем примере переменная bar заполняется вызовом процедуры формирования блоков данных для изображения. Далее, диаграмма транспонируется, тем самым приводя к линейчатому виду, и изображается в полярной системе координат отдельно:
bar <– ggplot(data = diamonds) +
geom_bar(
mapping = aes(x = cut, fill = cut),
show.legend = FALSE,
width = 1
) +
theme(aspect.ratio = 1) +
labs(x = NULL, y = NULL)
bar + coord_flip()
bar + coord_polar()
Упражнения
1. Преобразуйте линейчатую диаграмму с накоплением в круговую диаграмму с помощью coord_polar().
2. Где и как используется функция labs()? Ознакомьтесь с документацией.
3. В чем разница между coord_quickmap() и coord_map()?
4. Почему важно применение coord_fixed()? Что делает функция geom_abline()?
5. Выполните аналогично разобранной визуализацию успеваемости учеников своего класса.
Выше было показано как создавать диаграммы рассеяния, гистограммы и прямоугольные-диаграммы. После закрепления на практике сформировался навык, легко применимый к освоению диаграмм ggplot2 любого типа. Чтобы закрепить изученное, добавим настройки положения, статистическую обработку, настройки системы координат и разбиение данных к исходному шаблону кода:
ggplot(data = <данные>) +
<geom_основная функция графопостроителя>(
mapping = aes(<сопоставления с координатными осями и эстетикой>),
stat = <сбор дополнительной статистики>,
position = <позиция фрагментов диаграммы>
) +
<настройка координатной системы> +
<функция группирования данных>
Новый шаблон принимает семь параметров (заключенные в угловые скобки), которые применяются для описания желаемой визуализации данных. На практике редко приходится заполнять их все, чтобы построить график, так как в ggplot2 используются оптимальные значения по умолчанию для всего кроме данных, сопоставлений с осями и выбора функции geom.
Семь параметров в шаблоне составляют грамматику графопостроителя, формальную систему визуализации изображений. Грамматика основана на понимании того, что можно однозначно описать любой участок кода как комбинацию набора данных, функции графопостроителя, набора соответствий, статистической обработки, настройки положения фрагментов чертежа, системы координат и схемы группирования подмножеств исходных данных.
Чтобы понять, как это работает, вспомните, как строился простейший график с самого начала: фиксировался набор данных, затем выполнялась статистическая обработка для извлечения вспомогательной информации. Далее, выбирался способ представления каждого исходного значения и новых данных. При этом настраивались эстетические свойства геометрических примитивов, чтобы сопоставление значений каждой переменной с положением, цветом или формой объекта несло определенную смысловую нагрузку. Затем выбирали систему координат, чтобы в ней наглядно разместить полученное изображение, это само по себе тоже несет определенную эстетику, сопоставляя значения переменных с x и y. В результате получался график, но опционально ещё настраивалось местоположение объектов внутри системы координат (корректировка положения) и разбиение графика на подграфики (фасетирование). Также можно было улучшить изображение, добавив один или несколько дополнительных слоёв, на каждом из которых использовался свой набор данных, функция графопостроителя, набор сопоставлений, собиралась дополнительная статистика и регулировалось положение.
При помощи описанного метода строятся графики практически любой сложности. Другими словами, выкристаллизовавшийся в главе шаблон кода охватывает сотни тысяч уникальных графиков.
Перейдем ко второй части, анонсированной в названии раздела. Да, визуализация является важным инструментом понимания, но считается большой удачей получить исходные данные сразу в пригодном для визуализации формате. Часто приходится создавать новые переменные или сводные таблицы, переименовывать переменные или изменять порядок следования наблюдений, чтобы сделать данные немного проще для повышения наглядности их визуализации. Рассмотрим, как сделать все это и многое другое, как преобразовывать данные с помощью пакет dplyr на примере обширного набора данных о рейсах, вылетающих из Нью-Йорка.
 Историческая справка. На прилагаемом фото запечатлён трансарктический самолёт АНТ-25 в ангаре аэропорта Флойд Беннет, февраль 1939 года, ознаменовавший успешное участие СССР в Нью-Йоркской выставке 1939-1940 годов. Нью-Йорк, Бруклин.
Историческая справка. На прилагаемом фото запечатлён трансарктический самолёт АНТ-25 в ангаре аэропорта Флойд Беннет, февраль 1939 года, ознаменовавший успешное участие СССР в Нью-Йоркской выставке 1939-1940 годов. Нью-Йорк, Бруклин.
Сосредоточимся на том, как использовать пакет dplyr, – один из базовых инструментов tidyverse. Проиллюстрируем ключевые идеи, используя данные из базы nycflights13, и пакета ggplot2, чтобы визуализировать эти данные.
library(nycflights13)
library(tidyverse)
Обратите внимание на сообщение о возможных конфликтах, которое выводится при загрузке tidyverse, так как dplyr перезаписывает некоторые функции R. Если хотите использовать эти функции после загрузки dplyr, то нужно будет вводить их полные имена через два двоеточия, например, stats::filter().
Чтобы изучить основные способы работы с данными из dplyr, будем пользоваться базой данных nycflights13::flights, она содержит информацию по всем 336 776 рейсам, вылетевшим из Нью-Йорка. Данные поступают из Бюро статистики транспорта США, и вы можете с ними ознакомиться в любое время, просто введя в консоли:
flights
Заметим, что эта база данных при выводе в консоль отличается от вывода из других баз данных, которые применяли ранее. Показаны лишь первые несколько строк и столбцы, которые поместились на экране. Чтобы просмотреть весь набор данных, необходимо запустить:
view(flights)
Откроется таблица средствами просмотра RStudio, в слегка упрощенном виде, чтобы легче было применять инструментарий tidyverse. На данный момент не нужно беспокоиться о нюансах, позже вернемся к табличному представлению данных в соответствующей главе. Ряд из нескольких буквенных сокращения под названиями столбцов описывает тип каждой переменной: int означает целые числа; dbl означает действительные числа; chr означает символьные строки; dttm означает дату-время (дата + время). Существуют и другие распространенные типы переменных, они не используются в данном наборе, но будут рассмотрены отдельно: lgl означает логические значения, которые содержат только TRUE или FALSE; fctr означает факторы, которые R использует для представления категориальных переменных с фиксированными возможными значениями; date означает данные.
Следующие пять ключевых функций dplyr позволяют решить подавляющее большинство задач обработки данных: filter() отфильтрует наблюдения по заданным условиям; arrange() меняет порядок строк; select() выберет переменные по их именам; mutate() создаёт новые переменных со свойствами существующих переменных; summary() сворачивает множество значений до одного. Перечисленные функции можно использовать совместно с group_by(), которая изменяет область действия каждой функции со всего набора данных на определенные группы. Собственно перечисленные шесть функции и предоставляют собой команды языка обработки данных.
Все функции работают по общей схеме:
1) Первый аргумент – фрагмент данных.
2) Последующие аргументы описывают, что нужно делать с выбранными данными, используя имена переменных без кавычек, либо в одиночных апострофах кавычках «'», если имена содержат пробел « ».
3) Результатом является новый фрагмент данных.
Перечисленные свойства делают легко реализуемой последовательность из нескольких простых шагов к достижению желаемого результата. Разберем на примерах, как это работает. filter() позволяет выбирать подмножество наблюдений на основе определенных условий. Первый аргумент содержит имя базы данных. Второй и последующие аргументы являются выражениями, фильтрующими данные. Например, выберем все рейсы на 5 мая следующей командой:
filter(flights, month == 5, day == 5)
Когда запускаете эту строку кода, dplyr выполняет операцию фильтрации и возвращает новый блок данных. Функции dplyr никогда меняют входные данные, поэтому, если понадобится сохранить результат, то придется использовать оператор присваивания:
may5 <– filter(flights, month == 5, day == 5)
R либо распечатывает результаты, либо сохраняет их в переменную. Когда нужно сделать и то, и другое, команда заключается в круглые скобки:
(may5 <– filter(flights, month == 5, day == 5))
Чтобы эффективно использовать фильтрацию, нужно знать, как выбрать наблюдения, используя операторы сравнения. R предоставляет стандартный набор операторов: > (больше), >= (больше или равно), < (меньше), <= (меньше или равно), != (не равны), == (равны). Начинающие пользователи R зачастую ставят = вместо == при проверке равенства. Если допустить такое, то возникнет предупреждение об ошибке. Есть еще одна распространенная проблема, с которой сталкиваются при использовании ==, это числа с плавающей запятой. Поистине альтернативная арифметика:
sqrt (4) ^ 2 == 4
# > [1] TRUE
sqrt (5) ^ 2 == 5
# > [1] FALSE
1 / 50 * 50 == 1
# > [1] TRUE
1 / 49 * 49 == 1
# > [1] FALSE
Дело в том, что в R используется арифметика конечной точности, так как затруднительно хранить бесконечное количество цифр, либо реализовывать алгебраический подход. Поэтому каждое число в R является приближением, а вместо оператора == нередко используется функция near(), позволяющая сравнивать приближенные величины:
near(sqrt(5) ^ 2, 5)
# > [1] TRUE
Несколько аргументов функции filter() перечисленные через запятую равносильны объединению условий союзом «и», при этом, каждое выражение должно оказаться истинным, чтобы из входных данных соответствующая запись была сохранена в выходные данные. Для остальных логических связок можно использовать булевы операторы: & это «и», | это «или», ! это отрицание «не», xor(x, y) это исключающее или с аргументами x, y.
Следующий код находит все рейсы, которые вылетели в феврале или марте:
filter(flights, month == 2 | month == 3)
Если попытаться ввести команду буквально
filter(flights, month == (2|3))
то вместо желаемого будут найдены все месяцы равные результату булевой операции 2|3, значение которой обращается в TRUE. В числовом контексте TRUE становится равным единице 1, поэтому будут найдены все январские вылеты, что вовсе не соответствует задуманному.
Полезным клавиатурным сокращением для решения обозначенной проблемы является x %in% y. Это позволит выбрать каждую строку, где x является одним из значений в y. Можно было бы использовать следующую альтернативу для кода выше:
filter(flights, month %in% c(2, 3))
Иногда можно упростить сложное выражение вспомнив законы де Моргана из курса математической логики: !(x & y) == !х | !y, и !(x | y) == !x & !y. Например, если нужно найти рейсы, которые не задерживались (по прилету или отправлению) более чем на час, можно воспользоваться любым из следующих фильтров:
filter(flights,!(arr_delay > 60 | dep_delay > 60))
filter(flights, arr_delay <= 60, dep_delay <= 60)
Кроме & и |, в R есть && и ||, но не используйте их сейчас, позже узнаете, при каких условиях уместно их применение.
Всякий раз, когда используется сложное составное выражение в filter(), предпочтительнее разбить выражение на несколько вспомогательных, это значительно упрощает последующую проверку работы. Вскоре узнаем, как быстро создать новые переменные. Одна важная особенность R, которая может затруднить фильтрацию, это пропущенные значения, или недоступные (NA), которые представляют собой неизвестное значение, поэтому пропущенные значения являются изгоями, практически любая операция с участием NA приведет к NA.
NA > 1
#> [1] NA
2 == NA
#> [1] NA
NA + 3
#> [1] NA
NA / 4
#> [1] NA
Самым алогичным результатом может показаться следующий:
NA == NA
#> [1] NA
Но его легко понять в конкретном контексте: совпадает ли содержимое двух ящиков, внутри которых неизвестно что? Мы не знаем! Если хотите определить, отсутствует ли значение конкретной переменной, можно воспользоваться функцией is.na(), в качестве аргумента задав интересующее имя. Функция filter() отбирает только те строки, для проверяемые условия обращаются в TRUE, при этом исключаются как значения FALSE, так и NA. Если хотите сохранить пропущенные значения, то запрашивайте их в явном виде:
filter (flights, is.na(month) | month > 1)
Упражнения
1. Найти все рейсы, которые: имели задержку прибытия на два и более часа; прилетели в Хьюстон; управлялись компанией Delta; улетели летом; прибыл с опозданием более чем на два часа; задержались они как минимум на час, но наверстали более 30 минут в полете; отбыли между полуночью и 6 утра (включительно).
2. Функция between() из пакета dplyr тоже полезна для фильтрации. А что она делает? Можно ли использовать её для упрощения кода, необходимого для получения ответов в предыдущем задании?
3. Сколько рейсов имеет отсутствующее значение dep_time? Какие еще переменные у них отсутствуют? Что могут представлять собой эти записи в базе данных?
4. Почему значение NA^0 определено, NA / TRUE не определено, а FALSE & NA определено? Можете ли сформулировать общее правило, охватывающее и случай NA * 0?
Функция arrange () работает аналогично функции filter(), за исключением того, что вместо выбора строк, сортирует их. На вход принимаются данные и набор имен столбцов (или более сложных выражений), чтобы задать отношение порядка по возрастанию. Если укажете более одного имени столбца, то каждый последующий столбец будет сортировать значения строк с равными значениями из предыдущих столбцов:
arrange(flights, year, month, day)
Используя desc() можно переданный в аргументе столбец упорядочить по убыванию значений:
arrange(flights, desc(dep_delay))
Пропущенные значения (NA) всегда оказываются в конце сортировки.
Упражнения
1. Как использовать функцию arrange() для переноса всех пропущенных значений в начало списка? (Подсказка: применимо is.na()).
2. Сортировка рейсов позволяет найти самые задерживаемые рейсы. Найдите рейсы, которые вылетали пунктуальнее всех.
3. Отсортируйте рейсы так, чтобы найти самые скоростные перелёты.
4. Какие рейсы летали дальше всех? Какой маршрут был самым коротким?
Нередко формируемые наборы данных содержат сотни или даже тысячи записей. В таком случае проблематично даже просто найти интересующую переменную. Функция select() позволяет быстро сузить поле зрения исследователя, сконцентрировав его на нужных именах переменных. Конечно, select() не очень полезна для базы авиаперелётов, так как здесь лишь 19 переменных, но продемонстрируем общую идею:
# поимённый выбор столбцов «месяц», «день»
select(flights, month, day)
# выбор всех столбцов между «месяц» и «день» включительно
select(flights, month:day)
# выбор всех столбцов, кроме тех, что лежат между «месяц» и «день» включительно
select(flights, -(month:day))
Существуют вспомогательные функции, которые уместно вызывать внутри select(): функция starts_with("абв") выбирает имена столбцов начинающихся с «абв»; функция ends_with("эюя") выбирает имена столбцов заканчивающиеся на «эюя»; функция contains("клм") выбирает имена содержаие подстроку «клм»; функция matches("(.)\\1") выбирает переменные, имена которых соответствуют заданному регулярному выражению, конкретно в данном случае магическим образом выбираются переменные, содержащие повторяющиеся символы, подробнее о регулярных выражениях в строках расскажем в соответствующей главе; вызов num_range("m", 2:4) соответствует набору m2, m3, m4. Всегда можно заглянуть в ?select для получения более подробной информации.
А еще, select() можно использовать для переименования переменных, но это редко когда бывает полезным, так как отбрасывает не упомянутые явно переменные. Вместо этого для переименования используется функция rename(), который является вариантом select(), но сохраняет все переменные, которые не указаны явно:
rename(flights, год = year)
Другой вариант использования select(), совместно со вспомогательной функцией everything(), бывает необходим если есть несколько переменных, которые нужно переместить в начало базы данных. Например, месяц (month) и день (day) вылета будут показаны первыми при выводе данных из таблицы, содержащей информацию обо всех авиаперелётах (flights) по команде:
select (flights, month, day, everything ())
Аналогично запланированную дату и время полёта (time_hour), и время, проведенное в воздухе, выраженное в минутах (air_time) можно перекинуть в начало.
Упражнения
1. Примените мозговой штурм, чтобы найти как можно больше способов выборки значений переменных содержащих информацию о времени из базы данных flights.
2. Что произойдет, если имя одной переменной использовать несколько раз при вызове функции select()?
3. Что делает функция one_of()? Насколько полезно её применение в сочетании с вектором c("month", "day")?
4. Является ли результатом выполнения следующего кода неожиданным? Что вспомогательные функции выбора переменных в нём возвращают по умолчанию? Как изменить их значение по умолчанию?
select(flights, -contains("TIME"))
Помимо выборки существующих столбцов, полей таблицы базы данных, переменных, бывает необходимым добавление новых столбцов, которые хранят значения, являющиеся функциями от существующих. Это выполняется путём обращения к функции mutate(), которая всегда добавляет новые столбцы в конце имеющегося набор данных. Поэтому создадим более узкий набор данных, чтобы видеть новые переменные. Помните, что в RStudio самый простой способ увидеть все столбцы таблицы это вызов функции view(). Создадим укороченный_вариант_таблицы, содержащий все поля между «год» (year) и «день» (day) включительно, плюс поля, содержащие информацию о задержках (заканчивающиеся на delay), покрытом расстоянии (distance) и времени полёта (air_time) в минутах:


