



Цзыпэй Ту
Big data изменяют Китай
1.4. Как интеллектуальный анализ данных «превращает цифры в золото»
Прорыв, сделанный в отношении возможностей использовать данные, проявляется в интеллектуальном анализе данных.
Под интеллектуальным анализом данных (data mining) подразумевается осуществляющийся с помощью специальных алгоритмов автоматический анализ больших объёмов данных, имеющий целью выявление скрытых в них закономерностей и тенденций, иными словами, получение из данных большого объёма новых знаний, от которых можно отталкиваться, принимая те или иные решения. Основная причина прогресса в интеллектуальном анализе данных, то есть способность человека непрерывно изобретать всё более сложные алгоритмы распознавания образов3 в сущности является прогрессом в программном обеспечении. Самой знаменательной вехой развития интеллектуального анализа данных стала 1-я ежегодная научная конференция по data mining, организованная в 1989 году американской Ассоциацией вычислительной техники (Association for Computing Machinery, ACM), Специальной группой по обнаружению информации и интеллектуальному анализу данных (Special Interest Group on Knowledge Discovery and Data Mining, SIGKDD). Результаты работы конференции были отражены в специальной периодике. После этого развитие интеллектуального анализа данных получило огромное ускорение.
И действительно, в последние десятилетия благодаря технологиям интеллектуального анализа данных в самых разных крупных компаниях отмечалось немало удивительных историй, связанных с «превращением цифр в золото». Приведём несколько примеров. Накапливавшиеся в течение долгого времени записи о финансовых операциях пользователей позволили компании Alibaba проникнуть в финансовую сферу. Теперь сервис может за несколько минут определить кредитные данные пользователя и на этом основании принять решение о выдаче ему кредита. Walmart повысил объём продаж товаров в магазинах за счёт связи «пиво и подгузник». Netflix, используя учёт смены предпочтений своих пользователей, строит предположения о том, что им понравится смотреть, на основании чего осуществляется целенаправленный маркетинг.
Непрерывное обновление, которое в последние годы характеризует применение интеллектуального анализа данных, позволяет надеяться на новые достижения в этой сфере в будущем. Например, к переломному моменту своего развития приближаются продовольственные рынки, с которыми мы вот уже несколько тысяч лет «смотрим друг на друга и не можем насмотреться». На проводившемся в начале 2019 года собрании местных партнёров Alibaba по поставкам свежей пищевой продукции компания Ele. me заявила о намерении «изменить продовольственный рынок», создать совершенно новую открытую платформу для доставки свежих продуктов, переместить продовольственный рынок в онлайн-формат, заставить традиционный продовольственный рынок попрощаться с существовавшей в течение нескольких тысяч лет моделью функционирования, когда «каждый сам за себя» и «продаёт не по спросу, а то, что выросло», кроме того, сделать так, чтобы платформа содействовала превращению продажи овощей в тренд.
Каким же образом осуществить это содействие? Основным инструментом для этого как раз и является интеллектуальный анализ данных. Главная болевая точка традиционного продовольственного рынка – это информационная асимметрия: продавцы, завозят продукцию на продажу и не имеют в своём распоряжении точной информации о рыночном спросе, что приводит к накапливанию товаров или возникновению проблем с качеством. В этой ситуации Ele.me, опираясь на огромные массивы данных, накопленных Alibaba, может предоставить продавцу максимально точный портрет покупателя, что позволит регулировать деятельность по поставкам продукции на продажу. Таким образом поставки продукции на продовольственные рынки больше не будут произвольными – процесс принятия решения передаётся алгоритмам, и уже они решают, какие товары необходимо завезти. Резонанс интересов предпринимателей и самой платформы, достигающийся за счёт подобного рода цифрового маркетинга, может стимулировать возникновение огромной коммерческой стоимости. Описанная модель была опробована и на рынке: после того, как сервис Dingdong Maicai вошел в Ele.me, количество заказов на платформе за 2018 год увеличилось в 20 раз, а ежемесячный оборот торговли превысил 10 миллионов юаней [9].
Приведём ещё одну небольшую историю об интеллектуальном анализе данных. Во время проведения Чемпионата Европы по футболу в июне 2012 года в Китайских ресурсах появилось много сообщений о том, что «пока мужчины смотрят футбол, женщины занимаются онлайн-шоппингом» [10]. Сообщалось, что, согласно данным Taobao по продажам, после открытия чемпионата Европы торговый оборот женского сегмента онлайн-шоппинга очевидным образом вырос, при этом «пиковое время онлайн-продаж сдвинулось на два часа позднее, переместившись на отрезок с 23 до 24 часов». Кроме того, в период между окончанием первого матча в 1:45 ночи и началом второго матча в 2:45 ночи возник ещё один пик онлайн-продаж, и торговый оборот увеличился более чем на 260 % по сравнению с торговым оборотом в тот же отрезок времени в период до начала кубка.
Логику, составившую основу этого явления, несложно понять. Во время футбольного матча мужчины полностью погружались в просмотр, оставляя жён (или подруг) и детей без внимания. Женщины, особенно замужние, могли испытывать подавленность, раздражение и разочарование. Каждый раз, когда вечером начинался матч, у каждой женщины в такой ситуации появлялся большой выбор: например, начать делать домашние дела, болтать с подругами, звонить родителям, заниматься онлайн-шоппингом. Её поведение характеризует неопределённость, и предсказать, что именно она в конечном итоге будет делать, сложно. Однако если мы суммируем данные о продажах нескольких электронных торговых площадок и проанализируем их, то увидим, что групповое поведение женщин демонстрирует закономерности, поддающиеся отслеживанию. С началом кубка стал расти объём товаров, купленных женщинами онлайн, среди них увеличилось, по сравнению с обычным временем, и количество товаров высокой ценовой категории, то есть клиентки наконец позволили себе те вещи, на которые в обычной жизни у них не поднималась рука. До наступления эпохи больших данных утверждение «пока мужчины смотрят футбол, женщины занимаются онлайн-шоппингом» так и осталось бы не более чем догадкой, которую невозможно ничем подтвердить. Теперь же, в эпоху больших данных, получить ей подтверждение невероятно просто, причём мы можем проанализировать даже то, какие особенности отличают купленные товары. Во время следующего чемпионата магазины могли давать уже более предметную рекламу, они смогли не только более точно сфокусировать рекламные объявления исходя из адресата рекламы, выбор продвигаемых в них товаров также стал более адресным. Когда догадка выросла в знание, знание создало прибыль.
Помимо описанного выше применения в коммерции всё более распространённым становится использование интеллектуального анализа данных для решения общественных проблем. В июне 2013 года появились сообщения, что некая девушка из Восточно-китайского педагогического университета получила смс от администрации университета следующего содержания: «Уважаемый студент, мы обнаружили, что в прошлом месяце ваши затраты на питание в столовой были сравнительно небольшими. Возможно, вы испытываете финансовые трудности?» [11] Происхождение этого заботливого сообщения также объясняется интеллектуальным отбором данных: в результате анализа данных о тратах, полученных с университетских карточек на питание, администрация обнаружила, что затраты девушки на каждый приём пищи оказались сниженными, что и вылилось в отправку приведённого выше участливого сообщения. Впоследствии, однако, обнаружилось, что была допущена прекрасная ошибка: в действительности девушка просто хотела похудеть. Можно подумать, что причина возникновения ошибки в том, что данные были недостаточно «большими». Особенность больших данных в том, что помимо «большого объёма» они также являются «многоисточниковыми». Если бы помимо карточек на питание были проанализированы другие вспомогательные источники данных, вывод, вероятно, был бы более точным.
Несмотря на расцвет интеллектуального анализа данных, в определённой степени он уже не является передовым и горячим направлением в рамках больших данных, на лидирующих позициях его сменило машинное обучение. Интенсивно развивающееся в настоящий момент машинное обучение также опирается на компьютерные алгоритмы, но его алгоритмы, по сравнению с алгоритмами, использующимися в data mining, вовсе не являются фиксированными, они содержат саморегулирующиеся параметры, то есть в процессе машинного обучения по мере увеличения количества выполненных вычислений и анализов данных параметры алгоритмов непрерывно саморегулируются, вследствие чего результат анализа данных и прогнозирования становится более точным. Кроме того, предлагая компьютеру большой объём данных, мы даём ему возможность, подобно человеку, путём обучения постепенно самосовершенствоваться, поэтому данная технология и получила название «машинное обучение».
Наравне с интеллектуальным анализом данных и машинным обучением очень зрелыми являются также технологии анализа и применения данных, сформировавшие при этом единую систему. Хранилища данных, интерактивная аналитическая обработка (OLAP), визуализация данных, анализ машинной памяти – всё это важные составные элементы данной системы, и в процессе развития технологий сбора и обработки данных они все сыграли важную роль4.
Оглядываясь на более чем полувековую историю информационного общества, отметим, что материальный базис феномена больших данных был заложен только благодаря непрекращающемуся уменьшению размеров транзисторов и снижению их себестоимости, в результате чего у людей появилась возможность создать колоссальное, подобное огромному литому сосуду, хранилище для огромного массива данных. Технология же интеллектуального анализа данных, расцвет которой начался в 1989 году, сопоставима с технологией перегонки сырой нефти в готовый продукт: она является ключом к тому, чтобы большие данные произвели «большую ценность», без этой технологии, насколько огромен бы ни был массив данных, мы могли бы только «глядеть на нефть и бессильно вздыхать». Появившиеся в 2004 году социальные медиа, в свою очередь, сделали каждого из нас потенциальным создателем данных, который вносит свою лепту в наполнение отлитого вследствие действия закона Мура «сосуд», что и является главным фактором формирования «большого объёма». Схематично совокупность описанных факторов показана на рисунке 1.7.
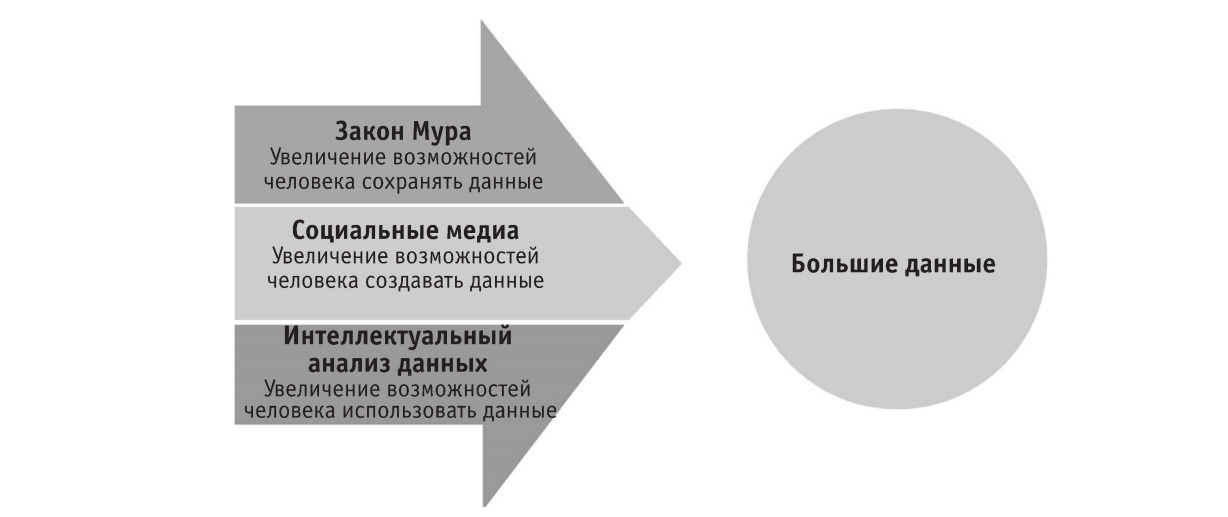
Рисунок 1.7. Три основных формирующих элемента больших данных
Проанализировав статичное понятие «большие данные» и формирующие их динамичные элементы, мы можем более ясно представить особенности этого явления, а также раскрыть его и дать ему определение исходя из разных точек зрения, как это показано на рисунке 1.8.
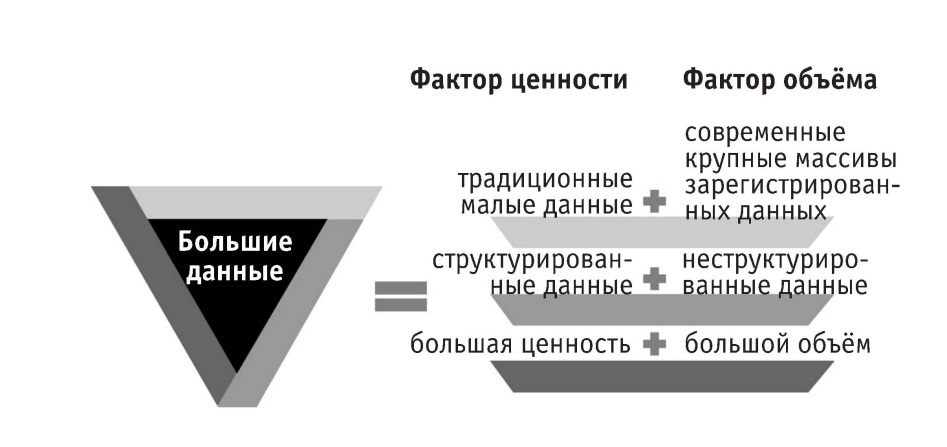
Рисунок 1.8. Понятие «большие данные» и характеризующие его факторы
Как мы уже говорили выше, в настоящее время 75 % производимых человеком данных – это данные неструктурированные, и именно в форме неструктурированных данных воплощаются крупные массивы зарегистрированных данных. Если мы хотим обнаружить ценность крупных массивов зарегистрированных данных и неструктурированных данных, главный способ обработки их в настоящее время – это всё же преобразование их в строго структурированные, то есть традиционные малые данные. Поэтому, по мнению автора, ценность больших данных главным образом заключается в малых данных и структурированных данных, а их объёмность – прежде всего в существующих в настоящее время крупных массивах зарегистрированных данных и в неструктурированных данных.
Подъём больших данных заставил учёных всего мира строить предположения и гипотезы о том, какое влияние эта «новая волна», вызванная развитием информационных технологий, принесёт человеческому обществу и в каком направлении она поведёт Китай и мир в целом. В следующих главах мы попробуем ответить на эти вопросы применительно к нескольким областям.
ГЛАВА 2. ЦИФРОВОЕ УПРАВЛЕНИЕ: ИСПОЛЬЗОВАНИЕ БОЛЬШИХ ДАННЫХ ДЛЯ ПОВЫШЕНИЯ УРОВНЯ ГОСУДАРСТВЕННОГО И МУНИЦИПАЛЬНОГО АДМИНИСТРИРОВАНИЯ И ГОСУДАРСТВЕННЫХ УСЛУГ
Необходимо построить полноценный механизм, с помощью которого большие данные будут содействовать наукоёмкости процессов принятия решений и социального управления и внедрению инноваций в модели государственного и муниципального администрирования и социального управления, чтобы тем самым достичь научной обоснованности принимаемых органами управления решений, точности социального управления и высокой эффективности государственных услуг.
Высказывание Председателя Си Цзиньпина во время второй коллективной учебной сессии Политбюро ЦК КПК
До 2016 года жителям Чжэцзяна для оформления регистрации купли-продажи вторичного жилья требовалось принести отдельные пакеты документов в три инстанции: министерство земельных и природных ресурсов, министерство жилищного и городского строительства и налоговую службу, – после чего самого оформления следовало ждать ещё какое-то время. Теперь же достаточно обратиться в одно окно с одним пакетом документов, и в течение часа процедура будет полностью выполнена. Оформление свидетельства о праве собственности на недвижимое имущество изначально требовало пятнадцати шагов, для совершения многих из которых нужно было стоять в очередях. На сегодняшний день, благодаря реализации принципа «один номер очереди – получение услуги в одном окне» [14], прежние пятнадцать шагов сведены к трём. Проведённая в Чжэцзяне реформа по «минимизации количества обязательных посещений госучреждений до одного» сделала жизнь обычных людей по-настоящему удобной и приятной.
Сущность реформы по «минимизации количества обязательных посещений госучреждений до одного» состояла не просто в том, чтобы физически свести в одно окна многочисленных государственных и муниципальных учреждений, а в однократной, направленной внутрь «революции» самих этих учреждений. Этот процесс был обеспечен в первую очередь реструктуризацией учреждений и реорганизацией административных процессов, а его ключевыми звеньями стали преодоление обособленности данных и совершенствование механизмов управления данными.
Тем не менее реформа по «минимизации количества обязательных посещений госучреждений до одного» – это всего лишь отправная, но никак не конечная точка в реформировании системы государственных услуг. Существует ещё огромное число направлений для развития той помощи, которую большие данные могут дать в сфере модернизации системы государственного управления и возможностей управления и удовлетворения с каждым днём возрастающей потребности людей в лучшей жизни.
2.1. От «ухода от причудливых справок» до «ухода от справок»
Ещё не так давно СМИ пестрели сообщениями о «причудливых справках», «замкнутом круге справок» и «дублирующих справках». Например, некоторым гражданам при оформлении наследства на недвижимость требовалось предоставить свидетельство о смерти умершего родственника, а некоторым пожилым людям для получения пенсии приходилось документально подтверждать, что они ещё живы. Премьер Государственного совета КНР Ли Кэцян выступил с критикой этого явления на собрании членов Постоянного комитета Госсовета в мае 2015 года. Если в реальности вся подобная информация о жителях страны имеется в распоряжении государства, почему для того, чтобы люди могли получить какую-либо услугу в государственных и муниципальных учреждениях, им нужно самим ходить по всем инстанциям и собирать соответствующие удостоверяющие документы?
Феномен «причудливых справок» объясняется отсутствием совместного межведомственного и межмуниципального доступа к данным, имевшимся в распоряжении части учреждений страны. Раз данные не могли «бегать по делам», делать это приходилось людям и организациям, а сама ситуация, ко всему прочему, оставляла лазейки для фальсификации справок и документов. Наступление эпохи Интернета и больших данных дало решающий ключ для решения этой проблемы.
В 2019 году городском округе Цзиньхуа провинции Чжэцзян, первом среди городских округов страны, развернули работу по созданию «города без справок»: было объявлено, что муниципальные ведомства и общественные учреждения на всей территории округа не должны требовать от граждан и организаций никаких справок или свидетельств, выпущенных каким-либо третьим полномочным органом. Это решение местного правительства образно представлено на рисунке 2.1. Отрадные результаты были получены всего за несколько месяцев ведения работы по созданию в Цзинхуа «города без справок». Была полностью упразднена необходимость предоставлять 18 типов справок и свидетельств, касающихся операций по фонду жилищных сбережений, в частности справка о доходах сотрудника, выписка о жилищном положении, документы, подтверждающие прямое родство того, кто претендует на получение накопительного фонда, и участника фонда, и требующееся в соответствии с политикой льгот на получение ипотечного кредита высококвалифицированными специалистами свидетельство с места работы, подтверждающее соответствующую квалификацию. Таким образом на территории всего округа было реализовано «не требующее справок» получение услуг по фонду жилищных сбережений. Прежде граждане, имеющие иную регистрацию, оформляя в Цзиньхуа разрешение на проживание, должны были сначала получить в министерстве социального обеспечения выписку, удостоверяющую уплату социального страхования за период более полугода, затем с этой выпиской, удостоверением личности и контрактом на аренду жилья прийти в полицейский участок, чтобы подать заявление на оформление разрешения. А сейчас, благодаря совместному доступу к данным, работник учреждения может напрямую запросить информацию о социальном страховании, и от заявителя не требуется никаких дополнительных справок [15].

Рисунок 2.1. Создание «города без справок» (Го Дэсинь/Жэньминь Тупянь)
Реформа по созданию «города без справок» представляет собой полезную попытку сделать государственные услуги более ориентированными на людей, однако местные ведомства не имели полномочий выдавать свидетельства и справки, которые должны оформляться ведомствами других районов. Так, во многих профессиях для осуществления практической деятельности требуется наличие «справки об отсутствии судимости», однако органы общественной безопасности какой-либо местности, оформляя подобную справку, могут удостоверить лишь то, что записи о судимости отсутствуют на подведомственной им территории, соответственно, приезжие служащие вынуждены за такой справкой ехать в место своей регистрации. Сколько же людям пришлось совершить напрасных поездок из-за того, что данные не умеют «бегать» между муниципалитетами?
«Оседлав» разросшийся до масштабов общегосударственной стратегии восточный ветер интеграционного развития региона дельты Янцзы, идёт ускоренное продвижение совместного межмуниципального и межведомственного использования данных правительственных учреждений всех провинций (районных и городских округов) региона. 24 января 2018 года на первой сессии комитета 13-го съезда Народного политического консультативного совета Шанхая лидеры Шанхайского городского комитета партии, обсуждая стимулирование интегративного развития региона дельты Янцзы с позиций подхода, осуществления и ближайших действий, обратили внимание на то, что в регионе необходимо усилить дорожную и информационную сети, а также продвигать реализацию совместного использования данных и предоставления открытого доступа к ним [16]. 11 июня того же года на совместной пресс-конференции с участием «Цзефан жибао», «Вэньхуэй бао» и других СМИ лидеры Шанхайского горкома предложили план по созданию «единой базы данных», подразумевающий совместное строительство регионального центра хранения и обработки данных и унификацию форматов данных, их спецификации, каталогов и интерфейсов, чтобы тем самым сделать источники данных более эффективными в использовании. С одной стороны, такой план направлен на скорейшее содействие созданию исходной базы данных, чтобы в соответствии с единым стандартом ввести в неё государственные, отраслевые и социальные данные разных муниципалитетов. С другой стороны, на осуществление деятельности с опорой на единую платформу для совместного использования данных, их межведомственное и межрайонное использование [17].
В эпоху больших данных конечная цель и идеальное состояние, на которые направлены реформы организационной структуры муниципального управления и реорганизация административных процессов, состоит в создании единого правительства. Упразднение «причудливых справок», «замкнутых кругов справок» и «дублирующих справок» является первым шагом на пути к единому правительству, в котором административные цели и методы ведомств разных районов не только не противоречат друг другу, но и способны друг друга усиливать. Отдав приоритет нуждам граждан, разные ведомства с помощью разработки единой структуры и процедуры, единого финансового контроля, единой технической поддержки и культуры взаимного доверия и ответственности сформируют одно «соединённое без швов» правительство.
К моменту, когда это будет реализовано, простым людям не нужно будет разбираться в разграничении обязанностей между ведомствами, которое даже служащие самих ведомств не всегда могут чётко обозначить; людям также не нужно будет выяснять, как открываются двери в то или иное учреждение, кто его руководитель, к кому лучше обратиться по тому или иному вопросу. И даже зал обслуживания людям не нужно будет посещать. Чтобы без суеты и напряжения получить ту или иную услугу, достаточно будет выполнить несколько действий в телефоне либо пройтись до местной общины. Как и писали учёные Сян Цзин и Ян Гуаньяо, «электронные государственные услуги только тогда смогут принести гражданам максимальную пользу и стать по-настоящему ценными, если смогут экономить время и силы, которые граждане вынуждены тратить при взаимодействии с госучреждениями при подаче заявлений на оказание каких бы то ни было услуг, если будет осуществлено видение граждан о спокойной жизни, состоящее в том, чтобы “не тревожиться ни о мелочах, ни о важных делах”».