- Рейтинг Литрес:3.8
Полная версия:
Валентин Юльевич Арьков Бизнес-аналитика. Сводные таблицы. Часть 1. Учебное пособие
- + Увеличить шрифт
- - Уменьшить шрифт

Бизнес-аналитика. Сводные таблицы. Часть 1
Учебное пособие
Валентин Юльевич Арьков
© Валентин Юльевич Арьков, 2020
ISBN 978-5-4498-1987-1
Создано в интеллектуальной издательской системе Ridero
Введение
Сводные таблицы (Pivot Tables) – это средство оперативного анализа данных с помощью статистических методов сводки и группировки. Обобщенные итоговые показатели подсчитываются автоматически в виде сумм, средних значений и т. п. Современные электронные таблицы позволяют создавать сводные таблицы в диалоговом режиме [1—3].
Сводные таблицы предоставляют конечному пользователю диалоговый интерфейс к многомерным OLAP-кубам – основному инструменту бизнес-аналитики. В качестве исходных данных можно использовать обычную таблицу Excel. Кроме того, сводные таблицы могут получать исходные данные для анализа, обращаясь к серверу базы данных с помощью SQL-запросов.
Задание. Прочитайте в Википедии статью «Сводная таблица» на русском и английском языках и выясните, как связаны сводные таблицы и OLAP.
Исходные данные, подготовленные для анализа, должны располагаться в одной «плоской» таблице по столбцам. При этом в первой строке должны находиться заголовки столбцов. Пример: первая колонка – дата, вторая колонка – время, третья колонка – сумма в чеке. Чтобы описание таблицы стало более реальным, нужно будет сделать зарисовку. А потом вставить её в отчёт. Как вставлять фотографии в отчёт, мы обсуждали в первой работе [4]. И использовали в последующих работах [5, 6]. Если нужно, всегда можно этот материал освежить в памяти. Далее в нашей работе мы будем все зарисовки вставлять в отчёт – даже если не сказано «и вставьте её в отчёт». Не забывайте это делать. Это наши действия по умолчанию.
Задание. Сделайте зарисовку описанного примера таблицы с исходными данными для анализа и вставьте в отчёт.
1. Цель и задачи работы
Целью работы является общее знакомство с технологиями анализа данных с помощью сводных таблиц. Мы познакомимся с этим инструментом в рамках программного пакета типа электронных таблиц. Однако все рассмотренные методы и технологии реализованы и в специализированных программных пакетах статистического анализа и бизнес-аналитики.
Для достижения поставленной цели мы решим следующие задачи.
1. Вначале мы сгенерируем исходные данные для анализа с помощью имитационного моделирования. Как и в предыдущих работах, мы используем генератор случайных чисел. Но в этот раз мы сгенерируем не только числа, но и даты, а также названия товаров и магазинов.
2. Затем мы построим сводные таблицы с помощью стандартных средств Excel. Здесь мы используем только диалог и визуальное конструирование. То есть обойдёмся без программирования и даже без вызова функций электронных таблиц.
7. После этого мы познакомимся с иерархией, которую можно сворачивать и разворачивать. Примеры: «Город – Магазин» или «Категория – Товар». В каждом городе может быть несколько магазинов, а нас интересуют данные по каждому городу в целом. В следующий момент мы захотим увидеть более подробную картину и развернём таблицу до сведений по каждому магазину в отдельности. Так пользователь управляет степенью детализации своего отчёта.
3. Далее мы поработаем с шаблонами (макетами) сводных таблиц. Это готовые рекомендации, которые могут немного ускорить работу по созданию сводных таблиц.
4. Следующим шагом станет построение сводных графиков. По сути, это сводная таблица плюс график, построенный по данным этой таблицы.
5. Мы также рассмотрим выборку из сводной таблицы по различным параметрам. Для этого мы используем такие инструменты, как фильтры, срезы и шкалу времени (Timeline).
6. Кроме искусственно смоделированных случайных чисел, мы поработаем с реальными данными и посмотрим, что с ними можно сделать с помощью сводных таблиц.
Задание. Прочитайте в Википедии статью «Business Intelligence» на русском и английском языках и выясните, что является источником данных для систем бизнес-аналитики.
2. Отчёт
Отчёт по лабораторной работе оформляется в виде одной рабочей книги пакета Excel. То есть одним файлом *.XLSX. Технологию оформления отчёта мы подробно рассматривали в рамках первой лабораторной работы – см. первое учебное пособие данной серии [4].
Файл следует сохранить под коротким информативным названием, и название файла должно позволять однозначно определить, что находится в файле и кто его создал. Также надо учесть, что длинные названия не всегда хорошо отображаются на экране в разных программах и разных системах.
Задание: Создайте новую рабочую книгу Excel и сохраните в файле с коротким информативным названием.
Каждый раздел отчёта размещаем на новом листе. Отчёт начинаем с титульного листа. На титульном листе нужно разместить следующую информацию: название министерства, университета, кафедры, вид документа, тему работы, номер варианта, номер группы, фамилии и инициалы студентов и преподавателя, название города, год.
Информацию нужно расположить так, чтобы всё умещалось на одном экране. Тогда не потребуется перемещаться за границы экрана или изменять масштаб. И читатель ничего не упустит. Ведь никто кроме автора не догадывается, сколько данных осталось за границами экрана.
Задание. Заполните титульный лист всей необходимой информацией.
Второй лист отчёта – оглавление документа. Все подробности создания оглавления – в первой работе [4]. Когда в отчёте больше 5—6 страниц, оглавление поможет легко ориентироваться в материале – и автору, и читателям. А в нашем отчёте может быть достаточно много страниц.
Задание. Создайте оглавление документа на втором листе отчёта.
3. Варианты заданий
Каждый студент работает по своему варианту задания. Номер варианта – последняя цифра номера зачётки. Если это цифра ноль – нужно взять вариант 10. Нулевой вариант мы будем использовать для демонстрации технологии выполнения работы.
Задание. Выберите свой вариант задания и укажите номер варианта на обложке отчёта.
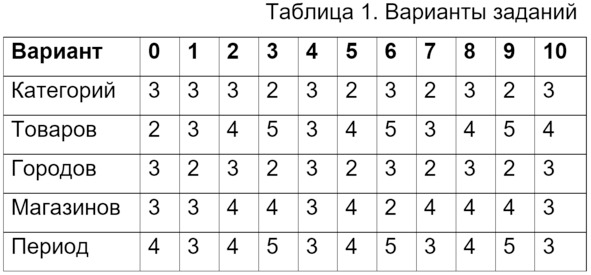
В таблице 1 приводятся параметры заданий. Эти числа означают следующее.
Мы будем генерировать данные с нужным количеством товаров в каждой категории. Вариант задания указывает, сколько разных категорий товаров нужно сформировать. Например, в нулевом варианте мы сформируем 3 категории разных товаров по 2 товара в каждой категории. Всего получим 3*2=6 товаров.
Для упрощения работы мы будем работать только с товарами, которые продаются на вес. Это могут быть, например, овощи, фрукты, крупы и т. п. Количество товара будем измерять в килограммах.
Аналогично с городами и магазинами. В нулевом варианте мы сформируем списки из трёх городов по три магазина в каждом городе. Итого получим в общей сложности 3*3=9 магазинов.
Период – это продолжительность записи смоделированных данных – в годах. Начало моделирования – 1 января 2015 года. Окончание периода – 31 декабря. Соответственно, в нулевом варианте мы смоделируем данные за четыре года. То есть за период с 01.01.2015 по 31.12.2018. Мы будем моделировать только дату и не будем учитывать время.
В нашей «базе данных» будет 10000 строк (записей). Это будет 10000 покупок отдельных товаров разными покупателями. Мы выбираем не слишком большое и не слишком маленькое количество данных, чтобы познакомиться с работой системы. Это количество данных уже невозможно оперативно обрабатывать с приемлемой скоростью. С другой стороны, слишком большие объёмы данных не сможет обработать сам пакет Excel. Такой эксперимент мы проделаем чуть позже, чтобы увидеть явное замедление работы программы.
Кроме того, для упрощения будем считать, что в каждой покупке участвовал только один-единственный товар. Все эти «упрощения» нужны для того, чтобы познакомиться с ключевыми, главными шагами анализа. Более сложный, продвинутый вариант работы мы предлагаем магистрантам.
Задание. На новой странице отчёта опишите параметры своего задания.
4. Надстройка «Анализ данных»
При выполнении работы для имитационного моделирования используется генератор случайных чисел, который нам предлагает статистическая надстройка «Анализ данных». Чтобы активировать надстройку, необходимо вызвать в верхнем меню
File – Options.
В диалоговом окне Excel Options выбираем вкладку Add-ins. Затем в выпадающем списке Manage выбираем Excel Add-ins и нажимаем кнопку Go (рис. 4.1).
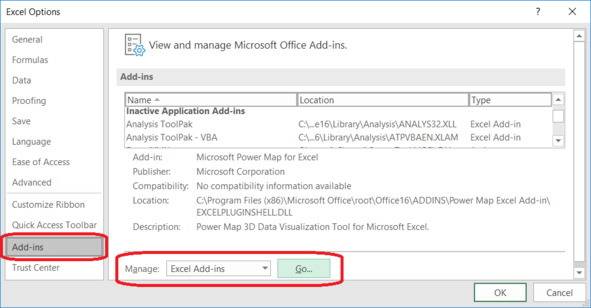
Рис. 4.1. Управление надстройками
В диалоговом окне Add-ins выбираем «Пакет анализа»: Analysis ToolPak (см. рис. 4.2). Нажимаем OK.
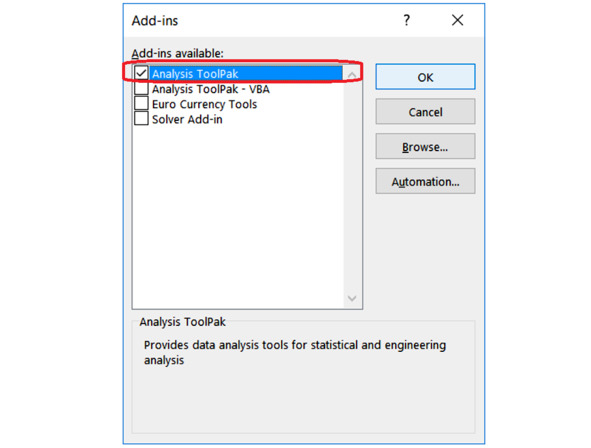
Рис. 4.2. Включение надстройки
Убедимся, что надстройка активирована. В верхнем меню выбираем Data и в разделе Analysis находим кнопку Data Analysis (рис. 4.3). Это и есть кнопка вызова нашей статистической надстройки.
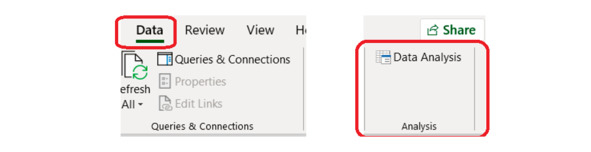
Рис. 4.3. Надстройка в меню
Задание. Включите надстройку «Анализ данных» и убедитесь, что в разделе Analysis появилась кнопка вызова надстройки.
5. Имитационное моделирование
Мы смоделируем исходные данные для анализа с помощью генератора случайных чисел.
Исходными данными будет «учётная» база данных транзакций, то есть сделок. В нашей работе мы сформируем таблицу транзакций, в которой будут фиксироваться основные сведения о каждой покупке в каждом магазине нашей торговой сети. По каждой сделке будем учитывать дату, категорию и наименование товара, город и название магазина, цену, вес и общую стоимость товара.
Задание. Сделайте зарисовку таблицы транзакций в соответствии с описанием – оформите шапку таблицы и заполните произвольными данными пару строк.
Перечисленные сведения можно найти на любом кассовом чеке. Они хранятся в реляционной базе данных в виде нескольких таблиц, связанных по ключевым полям. В нашей работе мы создадим «игрушечную» базу данных с помощью электронной таблицы. Здесь тоже будут справочники и связи между таблицами.
Задание. Возьмите любой кассовый чек и сделайте зарисовку логической модели данных (структуры базы данных).
5.1. Даты
Приступим к созданию таблицы транзакций. Первая строка содержит заголовки столбцов. Первый столбец – Дата. Данные будут расположены по столбцам.
Напомним, что дата выглядит для пользователя как три целых числа: год, месяц и день. Но в электронной таблице дата хранится просто как порядковый номер дня. Причём день номер 1 – это вовсе не начало нашей эры. Поэтому нам предстоит выяснить порядковые номера дней, а затем сгенерировать случайные числа в нужном диапазоне.
Выясним, какая дата будет первым днём по версии создателей электронной таблицы. Введём число 1 в ячейку таблицы. Щёлкнем правой кнопкой по этой ячейке и вызовем контекстное меню. Установим формат вывода – дата (рис. 5.1):
Format Cells – Number – Category – Date – Locale – Russian.
Type – 14-мар-2012.
При этом в разделе Sample можно увидеть соответствующую дату «Дня Первого»:
1-янв-1900.
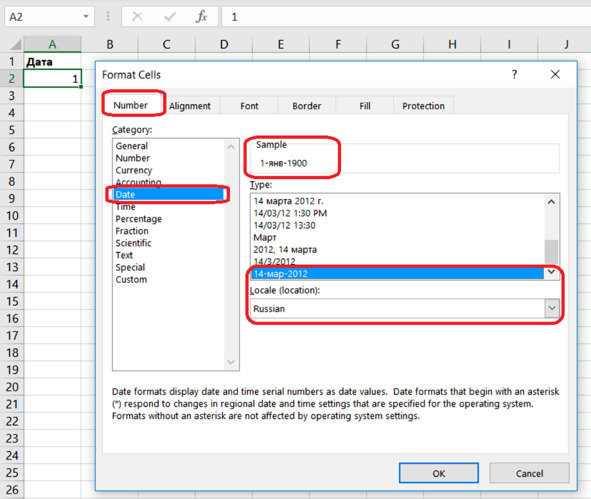
Рис. 5.1. «День Первый»
Нажимаем ОК и видим отображение даты в выбранном формате. При этом в строке формул выводится дата в американском стиле: месяц/день/год (рис. 5.2).
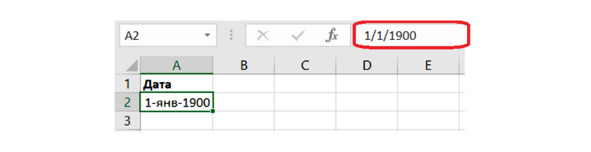
Рис. 5.2. Формат даты
Задание. Проверьте, какая дата соответствует числу 1.
Нам предстоит сгенерировать колонку целых чисел и превратить их в случайные даты в выбранном диапазоне. Вначале напомним, что в нулевом варианте мы работаем с данными за период с 01.01.2015 по 31.12.2018. Введём две указанные даты таким образом:
2015-1-1
2018-12-31
Excel распознал, что это даты и переключил формат отображения (рис. 5.3). При необходимости установите формат даты, принятый в нашей стране.
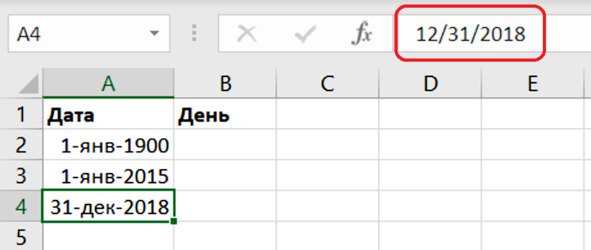
Рис. 5.3. Ввод даты
Выделим ячейки с датами в первом столбце и скопируем в буфер обмена:
Ctrl + C.
Выбираем ячейку B2 и вставляем данные из буфера/ Для этого нажимаем правую кнопку мыши и выбираем в контекстном меню:
Paste Options – Values.
В этом случае вставляются только значения (рис. 5.4).
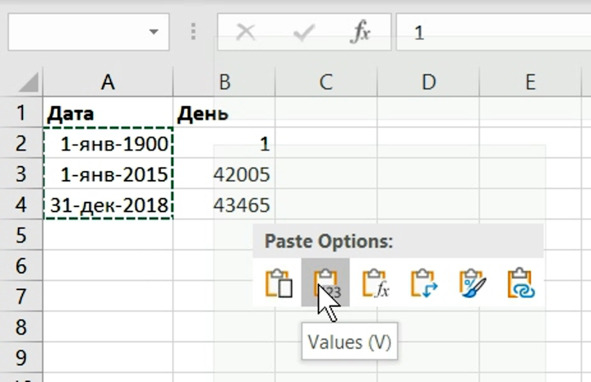
Рис. 5.4. Вставка значений
Задание. Определите номера дней для начала и конца своего периода времени.
Можно поступить по-другому и использовать ссылки на ячейки. Введём во второй колонке ссылки на соседние ячейки, чтобы продемонстрировать номер соответствующего дня. Например, ячейка B2 ссылается на ячейку A2 (рис. 5.5). Копируем формулу в остальные ячейки второй колонки.
Выделяем второй столбец. Устанавливаем общий формат вывода на экран:
Format Cells – Number – Category – General.
После настройки формата вывода выясняем, что начало нашего периода – это день номер 42005, а окончание – 43465.
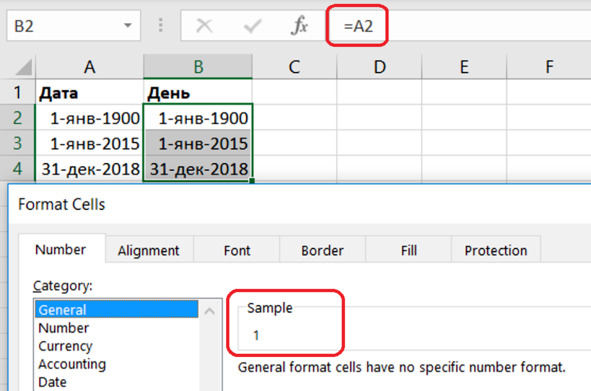
Рис. 5.5. Номер дня
Задание. Используйте ссылки на ячейки и выясните номера дней, соответствующие началу и концу моделирования.
Вызываем генератор случайных чисел с помощью надстройки:
Data – Analysis – Data Analysis – Random Number Generation.
Появляется диалоговое окно настройки генератора Random Number Generation (рис. 5.6).
Указываем число переменных, то есть количество столбцов случайных чисел. Нам пока что понадобится один столбец. Поэтому вводим число 1:
Number of Variables = 1.
Далее указываем заданное количество случайных чисел:
Number of Random Numbers = 10000.
Выбираем из выпадающего списка равномерное распределение:
Distribution – Uniform.
Указываем пределы изменения случайной величины – это номера первого и последнего дня нашего диапазона дат:
Parameters – Between 42005 and 43465.
Затем устанавливаем начальное состояние генератора случайных чисел. Этот параметр разработчики программы назвали Random Seed (Случайное рассеивание). Вводим любые четыре цифры:
Random Seed – 1234.
Напомним, что при следующих вызовах генератора нужно установить другие значения параметра. Тогда каждый раз мы будем получать новую псевдослучайную последовательность чисел.
Выбираем начало диапазона для вывода случайных чисел:
Output options – Output Range.
Нажимаем ОК и получаем столбец чисел.
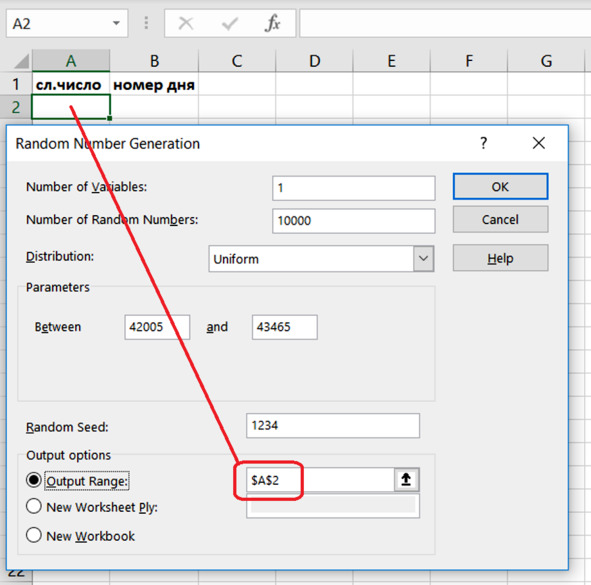
Рис. 5.6. Генератор случайных чисел
Задание. Сгенерируйте столбец случайных чисел в соответствии со своим вариантом задания.
Мы получили столбец случайных чисел. И эти числа дробные. Нам нужно их округлить, чтобы получить просто номера дней. Для этого используем функцию округления:
ROUND (number, num_digits).
Первый аргумент number – это ссылка на ячейку с числом, которое предстоит округлить.
Второй аргумент num_digits – это количество знаков после запятой. В нашей случае это ноль. Нам интересуют целые числа.
Вводим формулу в первую ячейку второго столбца и нажимаем Enter.
Заполняем весь столбец – двойным щелчком по маркеру автозаполнения (рис. 5.7). Столбец заполняется целыми числами.
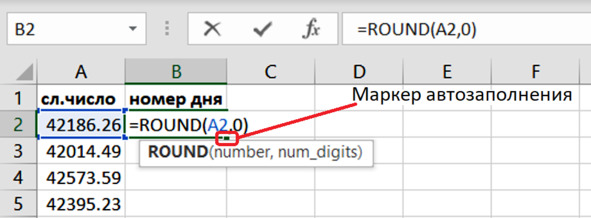
Рис. 5.7. Округление чисел
Задание. Округлите случайные числа до целых значений.
Пришло время создать даты.
Выделяем столбец ячеек с целыми случайными числами. То есть с порядковыми номерами дней. Для этого щёлкаем по первой ячейке столбца, где имеется число. В нашем случае это ячейка С2. Нажимаем «секретную» комбинацию клавиш:
Ctrl + Shift + Down.
Некоторые пользователи пытаются нажать эти три клавиши одновременно. И это не всегда получается.
Гораздо проще поступить так. Нажимаем Ctrl и продолжаем держать эту клавишу нажатой. Нажимаем Shift и продолжаем держать эти две клавиши нажатыми. Щёлкаем по клавише Down (Стрелка вниз) и отпускаем всё, что было нажато. Мы выделили все ячейки столбца, которые были заполнены.
Эта комбинация работает только с непрерывным диапазоном ячеек. Если некоторые ячейки в таблице не заполнены, то выделение остановится на первой же пустой ячейке.
Итак, мы выделили диапазон ячеек. Копируем выделенный фрагмент в буфер. Затем вставляем в новый столбец из буфера КАК ЗНАЧЕНИЯ (см. пример выше). Получаем третий столбец – номера дней, из которых мы создадим даты (рис. 5.8).
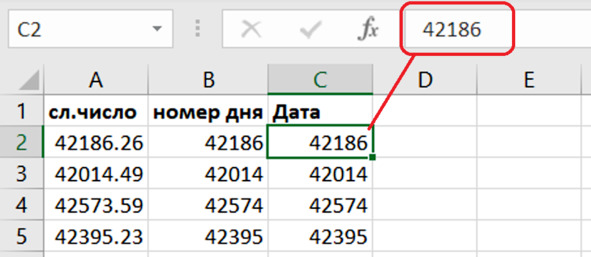
Рис. 5.8. Вставка значений
Задание. Скопируйте округлённые значения и вставьте их в третий столбец.
Зачем нужны были эти «хитрые» манипуляции со вставкой значений? На самом деле мы просто хотим оставить нужные столбцы и удалить вспомогательные. А нужный столбец может зависеть от вспомогательного. Например, округлённые значения во втором столбце ссылаются на случайные числа в первом столбце. Если удалить первый столбец, то все вычисления пострадают.
Вот теперь мы возьмём и удалим первый столбец. Выделяем ВЕСЬ первый столбец. Для этого щёлкаем по заголовку столбца А правой кнопкой мыши (рис. 5.9). В контекстном меню выбираем пункт Delete.
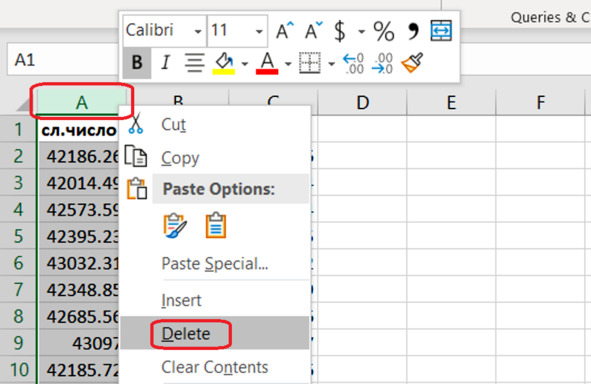
Рис. 5.9. Удаление столбца
Столбец А действительно исчезает. Теперь можно увидеть последствия. Каждая ячейка в столбце с округлением через функцию ROUND сообщает, что ссылка не работает. Слово REFERENCE здесь означает «ссылка на другую ячейку». Итак, после удаления столбца наша формула ссылается на несуществующую ячейку. А вот столбец, куда мы вставили значения вместо формул, ни от кого не зависит. Удаляем «неправильный» столбец с формулами и неработающими ссылками.
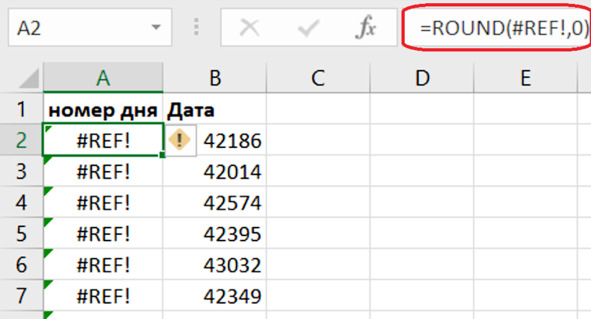
Рис. 5.10. Неработающая ссылка
Задание. Удалите столбец случайных чисел. Обратите внимание на сообщения об ошибках. Удалите столбец с формулами.
У нас остался столбец дат. Пока что в виде порядковых номеров дней. Пора вывести на экран человеческие даты. Выделяем столбец (секретная комбинация клавиш описана выше) и зададим формат даты (рис. 5.11):
Format Cells – Number – Category – Date.
Привычный формат вывода даты на русском языке устанавливается в разделе:
Locale (location) – Russian
Type – 14-мар-2012.
Нажимаем ОК.
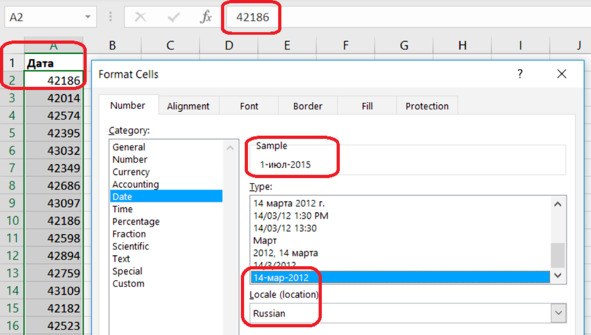
Рис. 5.11. Формат даты
Теперь даты стали видны невооружённым глазом. Наведём красоту и расставим даты в порядке возрастания. Выделяем диапазон дат и выбираем в верхнем меню:
Data – Sort & Filter – A-Z (Sort Oldest to Newest).
Это сортировка от A до Z. Или от А до Я. В порядке возрастания. От меньшего к большему.
Получаем даты по возрастанию, причём некоторые повторяются (рис. 5.12). Это значит, что наши магазины за один день посетили несколько клиентов, а не один. На самом деле, в реальной базе данных появляются сотни или даже тысячи записей каждый день. Но мы рассматриваем простой «игрушечный» пример, чтобы увидеть, как организована обработка данных.
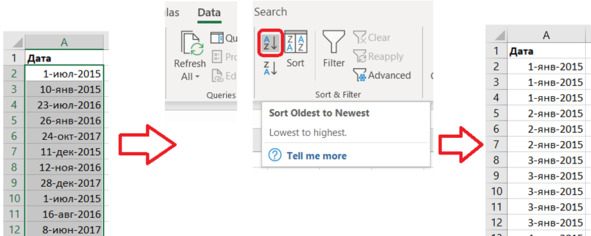
Рис. 5.12. Сортировка по возрастанию
Задание. Отсортируйте даты по возрастанию.
5.2. Справочники
В базах данных многие сведения можно считать постоянными, неизменными – в течение некоторого времени. Это сведения о магазинах и о товарах. «Условно постоянные» сведения можно вынести в отдельную таблицу-справочник. А потом на неё только ссылаться. Так и получается связь между таблицами в базах данных.
Задание. Сделайте зарисовку справочника магазинов с полями «Город», «Название магазина», «Адрес магазина», «ФИО директора магазина», «Телефон магазина». Заполните три строки таблицы.
Базы данных, в которых данные хранят в таблицах, связанных между собой, называют РЕЛЯЦИОННЫМИ.
Это слово иностранного происхождения. Английское слово, написанное русскими буквами. Так обычно поступают программисты, ведь им «некогда» думать и искать подходящий перевод. Берут слово RELATIONAL и пишут РЕЛЯЦИОННЫЕ.
Задание. Прочитайте в Википедии статью «Реляционная модель данных» и выясните, на что в базе данных указывает слово RELATION, то есть что здесь означает слово «отношение», – ответ совсем неочевидный.
Создадим справочник магазинов в соответствии с нулевым вариантом. У нас будет три города, а в каждом городе по три магазина. Справочник разместим на новом листе рабочей книги Excel. Вкладку озаглавим «Маг». Названия на вкладках сделаем покороче. А вот заголовок на странице сделаем поподробнее и попонятнее: «Справочник магазинов».
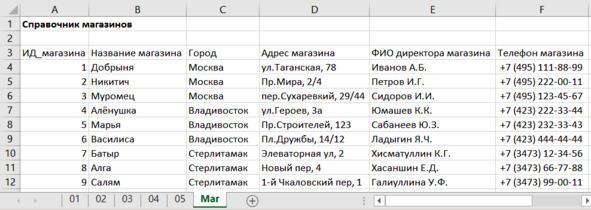
Рис. 5.13. Магазины
Задание. Создайте справочник магазинов в соответствии с вариантом задания и заполните его.
Первое поле таблицы мы назвали ИД_магазина. Это идентификатор. Целое число, по которому мы будем различать магазины между собой. Слово ИДЕНТИФИКАТОР тоже очень иностранное. Означает оно «признак, по которому можно что-то или кого-то идентифицировать». В нашем случае это число, по которому можно определить, о каком магазине идёт речь. Все наши числа-идентификаторы в справочнике должны быть разными, иначе начнётся путаница.
Слово ИДЕНТИФИКАТОР часто сокращают до двух букв: ИД или ID. Однако это не просто сокращение. Здесь скрывается игра слов – любимое занятие программистов. Дело в том, что в английском языке сокращение ID имеет особый смысл. ID может означать Identity Document. То есть документ, удостоверяющий личность. По которому можно установить личность человека. То есть идентифицировать человека. Например, за границей могут попросить «предъявить ID».
Задание. Прочитайте в английской версии Википедии статью Identity document. Выясните, что можно использовать в качестве ID.
Наконец-то мы заполнили справочник и разобрались, что такое ИД. Но пока что перед нами только ячейки на листе. Сделаем из этого отдельный объект – «Таблицу Excel», к которой можно будет обращаться по названию. Выделяем всю таблицу на листе, включая заголовки столбцов. Выбираем в верхнем меню вставку таблицы (рис. 5.14):