



Тимур Машнин
Основы SEO. Введение в поисковую оптимизацию
Исходный код
Исходный код к примерам можно скачать с сайта GitHub (https://github.com/novts/seo).
Введение. Поисковые системы
Чтобы действительно понять, почему поисковые системы работают так, как они работают, важно знать историю поисковых систем.
В это уже тяжело поверить, но в начале 2000-х сеть выглядела именно так.
Это был список ссылок, которые поддерживались людьми.
И поиск нужной вам информации был сложным процессом, и обычно он заключался в переходе по ссылке со ссылки в надежде, что вы попадете в нужное вам место.
Сама идея Интернета появилась в 1945 году после того, как инженер Буш написал для Time статью «Как мы можем думать».
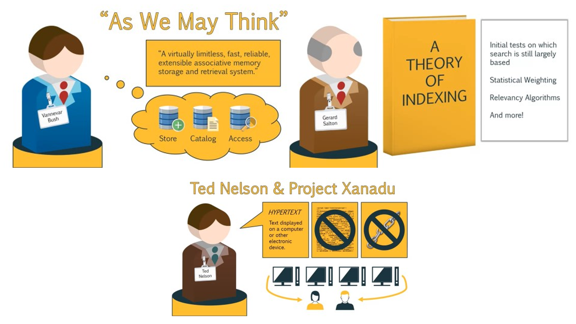
В этой статье Буш подтолкнул ведущих ученых того времени к созданию практически безграничной, быстрой, надежной, и расширяемой системы хранения и поиска.
Буш понял, что технологии развиваются быстрыми темпами, и поэтому человечеству понадобится способ хранить и легко получать доступ к информации, которая накапливается.
Далее в 1960-м, Джерард Сэлтон, который считается отцом современных поисковых технологий, создал идею поисковой системы и разработал информационно-поисковую систему под названием SMART.
Сэлтон является автором книги под названием «Теория индексации», в которой подробно описываются такие понятия, как статистическое взвешивание, алгоритмы релевантности и многое другое.
Примерно в то же время Тед Нельсон создал проект Project Xanadu, целью которого было создание компьютерной сети с простым пользовательским интерфейсом.
И Тед придумал термин «гипертекст» и был против сложного кода разметки.

Вскоре после этого, в 1969 году, родилась служба ARPANET, которая была создана ARPA, Агентством перспективных исследовательских проектов, относящимся к Министерству обороны США.
ARPANET была безопасной и быстрой компьютерной сетью, которая позволяла передавать информацию на большие расстояния.
И эта служба использовала телефонные линии для передачи информации военной разведки.
Можно с уверенностью сказать, что без создания ARPANET Интернет, каким мы его знаем сегодня, не существовал бы.
В 1990-м, появилась первая поисковая система, созданная Аланом Эмтажем.
Эта поисковая система была известна как Арчи, и она могла извлечь файлы из базы данных, сопоставив запрос пользователя с помощью регулярных выражений.
Алан также создал метод индексации, который позволил Арчи индексировать общедоступные документы, изображения, аудио и сервисы в сети.
Арчи не использовал ключевые слова для поиска связанных документов, как это делают современные поисковые системы.
Чтобы эффективно использовать Арчи, нужно было знать имя файла, который вы ищите, так как Арчи не индексировал содержимое файлов, а только заголовки.
К 1992 году Арчи содержал около 2,6 миллиона файлов, а его сервис обрабатывал около 50 000 запросов в день, генерируемых тысячами пользователей по всему миру.
По мере роста популярности Арчи были созданы две похожие поисковые системы, Veronica и Jughead, с целью индексации текстовых файлов.

И наконец, в 1991 году Тим Бернерс-Ли, независимый подрядчик CERN, создал World Wide Web.
Всемирная паутина была создана на основе концепции гипертекста, чтобы облегчить обмен и обновление информации исследователей CERN.
В 1991 году был создан и размещен в сети первый веб-сайт.
В нем содержалось объяснение того, что такое Всемирная паутина, и как можно настроить веб-сервер и пользоваться браузером.
В 1993 году был создан первый робот-паук. Этот бот назывался World Wide Web Wanderer и был предназначен для измерения роста сети.

Вскоре бот был обновлен для сбора активных URL-адресов и сохранения их в базе данных WANDEX.
Но робот вскоре стал скорее проблемой, чем решением.
Он сканировал веб-сайты и обращался к страницам сотни раз в день, создавая большую задержку на серверах и иногда вызывая сбои веб-сайтов.
Это создало большое недоверие к роботам среди веб-мастеров и широкой публики.
Поэтому был создан робот ALIWEB.
ALIWEB расшифровывался как Archie-подобная индексация Интернета, и он сканировал метаинформацию страниц.
И ALIWEB разрешил владельцам предоставлять свой сайт для включения в поисковый индекс вместе с описанием веб-страниц.
Недостатком было то, что многие люди не знали, что они должны предоставить свой сайт для индексации.
И все современные поисковые системы создали программы, известные как роботы.
И каждая поисковая система использует своего уникального робота.
Эти роботы сканируют Интернет, пытаясь обнаружить новые веб-страницы и документы.
Один из способов, с помощью которого роботы открывают новые сайты, – это ссылки.
Если другой веб-сайт ссылается на ваш сайт, это упрощает путь для робота.
В первые дни Интернета веб-мастерам приходилось размещать свой сайт в поисковых системах, чтобы его могли обнаружить роботы.
Теперь роботы найдут ваш сайт самостоятельно.
И добавление вашего сайта в бесплатных службах, таким как Инструменты Google, поможет в этом процессе обнаружения.
Как только робот обнаруживает новую страницу или сайт, он анализирует весь контент и данные на странице, чтобы определить, о чем идет речь.
Затем сайт добавляется в базу данных.
Каждая страница находится в каталоге, поэтому поисковые системы могут быстро ссылаться на данные при необходимости и возвращать соответствующие результаты в ответ на поисковый запрос пользователя.
Чтобы ускорить процесс, по всему миру расположены центры обработки данных, которые позволяют быстро получать доступ к большому количеству информации.
И работа SCO заключается в том, чтобы понять, что делает веб-сайт релевантным для поискового запроса.
В прошлом поисковые системы смотрели только контент на вашей странице или какие ключевые слова, использовались наиболее часто.
Сейчас поисковые системы стали намного умнее.
И сегодня существуют сотни факторов, влияющих на релевантность результатов поиска.

В свое время был создан стандарт исключения роботов, который устанавливает стандарты того, как поисковые системы должны индексировать или не индексировать контент.
И используя стандарт исключения роботов, веб-мастера могут указывать поисковым системам, какой контент они хотят сканировать и какой контент они хотят, чтобы поисковые системы оставили в покое.
Вы можете заблокировать просмотр роботом всего сайта или только определенных страниц.
По умолчанию вся публичная информация сканируется и публикуется.
К концу 1993 года были созданы три поисковых системы.
Хотя ни одна из них не показала себя достаточно хорошо, чтобы сохраниться.
Jumpstation собирала заголовки веб-страниц и извлекала их с помощью простого линейного поиска.
WWW Worm индексировала заголовки и URL, но отображала результаты только в том порядке, в котором они были обнаружены.
Третья система Spider Based Software Engineering или RBSE, не имела никакой системы ранжирования.
И по сути, чтобы пользоваться любой из этих поисковых систем, вам нужно было знать точное название того, что вы искали.
Примерно в то же время шесть старшекурсников из Стэнфорда создали поисковую систему, которая оценивала результаты на основе статистического анализа взаимосвязей слов.

С ростом Интернета двое студентов в Стэнфорде Джерри Янг и Дэвид Фило создали то, что мы знаем сегодня как Yahoo.
Эти студенты использовали Интернет, который был всего лишь набором файлов, чтобы найти самую свежую спортивную информацию.
И они быстро поняли, что для эффективного использования Интернета людям нужен каталог, чтобы помочь пользователям перемещаться по информации.
Они начали создавать каталог и вручную компилировать веб-сайты, которые они нашли, в коллекцию категорий и подкатегорий.
Пользователи Интернета могли кликать по этому каталогу, чтобы находить новую информацию и сайты.
Этот каталог назывался «Руководство Дэвида и Джерри по всемирной паутине».
И был первым сайтом, который собирал сайты, чтобы пользователям было легче находить информацию, которую они искали.
По мере того, как Руководство Дэвида и Джерри по всемирной паутине набирало популярность, они поняли, что им нужно более броское имя. Так они создали Yahoo!
Но свежего, нового имени было недостаточно. Им нужно было финансирование.
Сегодня такие поисковые системы, как Yahoo и Google, генерируют миллиарды долларов.
Но в то время никто еще не нашел способ монетизации Интернета.
В первые дни, Интернет не использовался для бизнеса или коммерции.
Некоторые даже считали идею о ведении бизнеса в Интернете плохой.
И в начале 90-х дебаты по поводу надвигающейся коммерциализации сети были довольно ожесточенными.
Были венчурные капиталисты, которые хотели использовать рекламу на новом канале, с одной стороны. И другие, которые рассматривали это как некоммерческую утопическую среду, с другой стороны.
И Дейв, и Джерри столкнулись с этой дилеммой финансирования и, в свою очередь, рекламы, которая поможет расширить их платформу, но в то же время потенциально оттолкнет их пользователей.
В итоге они выбрали рекламу, но обнаружили, что база пользователей все равно продолжает расти.
Это создало бум.
Еще больше компаний осознали потенциал зарабатывания денег в Интернете.
В это же время, была запущена поисковая система Excite, и ее алгоритм был ближе к тому, что мы сегодня считаем поисковой системой.
Конкуренция между Yahoo и Excite обострилась.
Каждый стал придумывать больше интересных функций, таких как бесплатная электронная почта, чтобы привлечь пользователей и заставить их оставаться на своем веб-портале.
И в конце концов жадность создала проблему.
Так как было трудно найти соответствующую информацию в Интернете, потому что большинство результатов – это были ссылки на рекламу и нерелевантные или спам-страницы.
Мир нуждался в лучшем способе поиска в сети.

Но вскоре на помощь пришла новая поисковая система от двух студентов Ларри Пейджа и Сергея Брина, которые создавали поисковую систему, которую сегодня мы знаем как Google.
Google начал с идеи, что веб-сайты должны участвовать в конкурсе популярности, и чем популярнее сайт, тем больше людей ссылаются на него, чтобы рекомендовать этот сайт другим.
Следовательно, чем больше ссылок на веб-сайт, тем лучше этот сайт должен быть для пользователей и тем выше он будет в рейтинге их новой поисковой системы.
В своей научной статье в 1998 году они заявили, что, по сути, Google интерпретирует ссылку со страницы на страницу как голосование.
И Google оценивает важность страниц по голосам, которые они получают.
Это стало самой большой частью алгоритма Google, известного как Page Rank.
И в то же время, чтобы ваш веб-сайт имел более высокий рейтинг, чем веб-сайт конкурентов, все, что вам действительно было нужно, – это больше ссылок, чем у вашего конкурента.
Это было довольно легко получить.
Поэтому с годами Google доработал свой алгоритм.
Но в первые дни Интернета, такой простой алгоритм сделал результаты поиска очень удобными для пользователя.
Люди начали собираться в поисковике и чуть не обрушили интернет университета Стэнфорда.
Поэтому вскоре Ларри и Сергея попросили убрать Google из кампуса.
Чтобы продолжить работу и улучшить свою поисковую систему, им нужно было финансирование.
Но никто не хотел вкладывать деньги, потому что люди думали об этом как о еще одной поисковой системе.
Один инвестор, который также был инвестором Excite, попытался убедить Ларри и Сергея работать с Excite вместо того, чтобы продолжать развивать Google.
Ларри и Сергей предложили заплатить им около миллиона долларов, чтобы выкупить их.
Excite отклонил это предложение, что, вероятно, смущает их по сей день.
В конце концов, Ларри и Сергей нашли финансирование, и они не возражали против монетизации, но они обеспечивали, чтобы страница с результатами поиска предоставляла релевантные, понятные результаты без всякой кричащей рекламы.
Они решили оставить сайт свободным от рекламы до тех пор, пока не смогут найти способ сделать так, чтобы это не влияло на удобство использования.
Тем временем в Лос-Анджелесе основатель стартапа-инкубатора idealab работал над решением проблемы интернет-рекламы.
Этим человеком был Билл Гросс, и он понимал, что каждый раз, когда пользователь вводит поисковый запрос в поисковую систему, он сообщает этой поисковой системе именно то, что его интересует и какие товары он может потенциально купить.
Эта информация была чрезвычайно ценной для маркетологов и рекламодателей.
И Билл понял, что поисковые системы могут продавать эту информацию и конкретные запросы рекламодателям.
Это позволило бы компаниям гарантировать, что их бренд будет связан с определенными ключевыми словами, покупая ссылку на свой сайт всякий раз, когда кто-либо вводит связанное ключевое слово в поисковую систему.
Например, Nikon может платить большие деньги, чтобы появляться каждый раз, когда кто-то печатал слово «камера».
Многие думали, что эта идея никогда не сработает.
Но Гросс видел это как новую форму желтых страниц, где вы можете открыть телефонную книгу, перейти на страницу и найти платные объявления для всего, что вы искали.
В 1998 году он в конечном итоге запустил сайт на основе спонсорских ссылок для конкретных ключевых слов.
В конце концов, этот сайт привлек внимание Ларри и Сергея, которые подумали, что это может быть отличной дорожной картой для их собственной поисковой системы.
Они решили встретиться с Биллом и обсудить способы объединения.
По какой-то причине эта сделка не была заключена.
Но в 2000 году Google выпустил свою версию Adwords, очень похожего сервиса.
Гросс подал в суд на Google из-за сходства, но обе стороны в итоге урегулировали вопрос в суде.
И Google дал Гроссу большое количество акций Google, чтобы он был счастлив.
Google отделил рекламу от обычных результатов поиска.
Это помогло гарантировать, что результаты обычного поиска будут по-прежнему полезными и актуальными для пользователей.
Это привело к новому бизнесу, который принес Google наибольшую долю рынка и изменил будущее онлайн-рекламы.
Поисковые системы и SEO
Независимо от того, используете ли вы Google, Bing или другую поисковую систему, все поисковые системы имеют одну и ту же цель – предоставлять релевантную информацию для поискового запроса пользователя.

Если поисковые системы не могут своевременно предоставить результаты, которые вы ищете, пользователи обратятся к другим сервисам для будущих поисков.
И помните, что, хотя мы можем использовать поисковые системы бесплатно, поисковые системы занимаются зарабатыванием денег.
Каждый раз, когда выполняется поиск, отображается как список органических результатов, так и список платных результатов.
И чем больше поисков выполняется в поисковой системе, тем больше компаний будут покупать места для рекламы у этой поисковой системы.
И если бы, например, Google показывал только рекламу, а не обычные результаты поиска, пользователи скоро устали бы от таких результатов и пошли бы куда-нибудь еще.
Чтобы пользователи возвращались, им нужно предоставлять хорошее сочетание органических результатов и рекламы.
И один из способов, с помощью которого поисковая система может обеспечить полезные, релевантные результаты для конкретного запроса, – это использование алгоритмов.
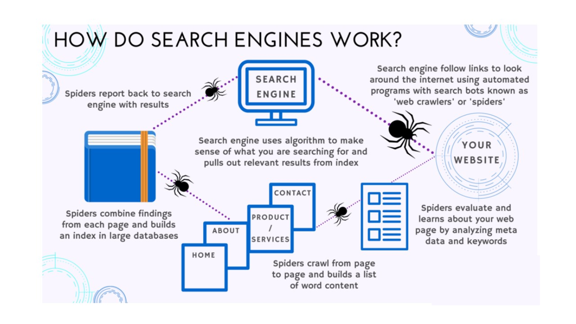
Поисковые системы используют алгоритмы для определения качества веб-сайта, темы веб-сайта и типов запросов, которые веб-сайт должен отображать в результатах поиска.
Алгоритмы также используются для определения того, где в результатах обычного поиска должен отображаться конкретный веб-сайт для конкретного запроса.
Есть много разных алгоритмов, и они смотрят на сотни факторов, окружающих ваш сайт.
И работа SEO заключается в определении того, какие алгоритмы фокусируются на каких факторах, и как мы можем оптимизировать веб-сайт для соответствия этим критериям.
За годы изучения поисковых систем и проведения тестов, сообщество SEO определило множество различных факторов, которые влияют на сайт и его рейтинг. Некоторые из этих факторов все еще являются предметом дискуссий и спекуляций.
Каждый год Moz, хорошо известный инструмент SEO и сообщество SEO, предоставляет список того, что они считают основными факторами в этом году.
Это всегда интересная информация, которая может дать глубокое понимание того, что меняется в SEO, и на чем лучше всего сосредоточиться.
Основными алгоритмами, на которые ориентируется SEO, являются алгоритмы, созданные и поддерживаемые Google. Это потому, что Google имеет самую высокую долю рынка.
Мы знаем, что существует более 200 различных факторов ранжирования или сигналов, используемых Google для понимания и ранжирования веб-сайта.
Кроме того, этот алгоритм обновляется каждый день.
Эти обновления не всегда могут быть значительными и напрямую влиять на ваш сайт, но важно знать, что алгоритмы Google постоянно меняются, чтобы предоставлять пользователям наилучшие результаты.
За один год делается более 500 обновлений алгоритма.
И поскольку обновлений так много, мы должны полагаться на себя, чтобы заметить эти изменения и то, как они влияют на результаты поиска.
Google объявляет только небольшой процент обновлений, которые они делают.
И вообще, они очень расплывчаты в отношении того, что именно обновляется и когда.
Очень важно сохранять бдительность в отношении изменений результатов поисковой системы, чтобы вы могли заметить, когда произошло обновление, какие изменения произошли, и нужно ли вам вносить изменения в свой веб-сайт.
Один из способов сохранять бдительность в отношении потенциальных сдвигов в алгоритме – это использовать инструмент, созданный Moz.
Этот инструмент называется MozCast и он предоставляет отчет о турбулентности в алгоритме за определенный период времени.
Турбулентность измеряется путем изучения колебаний рейтинга.
Дни с более высокой температурой имеют более высокий процент колебания рейтинга.
Это может указывать на то, что было сделано обновление алгоритма.
Всякий раз, когда вы замечаете большие изменения в вашем рейтинге или трафике, хорошей идеей будет проверить MozCast.
И поскольку алгоритмы постоянно развиваются, очень важно, чтобы вы разработали про-активный подход к SEO.
Это означает, что наилучший подход – это посмотреть, какие обновления были в прошлом, и определить конечную цель Google.
Затем вы можете оптимизировать свой сайт таким образом, чтобы он выдержал испытание временем.
Это означает следование лучшим практикам Google, что в значительной степени гарантирует, что ваш сайт не будет оштрафован или заблокирован обновлением алгоритма.
И одна из причин того, почему алгоритмы обновляются так часто, связана с тем, что веб-мастера манипулируют алгоритмом, чтобы получить высокий рейтинг для не релевантной страницы.
По мере того, как SEO оптимизаторы узнают больше об алгоритме, некоторые из них чрезмерно оптимизируют эти факторы.
Это заставляет поисковые системы корректировать свои алгоритмы для учета этой спам-тактики.
Вот почему не стоит чрезмерно оптимизировать свой сайт. Это может работать некоторое время, но это не жизнеспособно в долгосрочной перспективе.
Чтобы гарантировать, что на ваш сайт не повлияет штраф или корректировка алгоритма, рекомендуется всегда следовать рекомендациям Google.
Google предоставляет веб-мастерам набор лучших практик.
Это может помочь обеспечить оптимизацию сайта.
И первая лучшая практика – убедиться, что вы предоставляете высококачественный контент, особенно на домашней странице.
С точки зрения взаимодействия с пользователем, это помогает пользователям сразу понять, о чем ваш веб-сайт и как он может удовлетворить их потребности.
С точки зрения SEO, ваша домашняя страница – это страница, которая пользуется наибольшим авторитетом на вашем сайте, и это одна из главных страниц, которая в итоге окажется в рейтинге.
Важно предоставлять информацию пользователям, но не менее важно, чтобы поисковые системы понимали, о чем ваш сайт, и оценивали его соответствующим образом.
И контент вашей домашней страницы может помочь это сделать.
Получение ссылок с других сайтов является еще одной важной передовой практикой.
Каждая ссылка на ваш сайт приносит вам авторитет, поэтому чем больше у вас качественных ссылок, тем больший авторитет получает ваш сайт.
Это может помочь вашему сайту повысить рейтинг в результатах поиска.
Далее, важно убедиться, что ваш сайт доступен как для пользователей, так и для поисковых систем.
Некоторые веб-сайты закодированы таким образом, что пользователи могут видеть контент, но поисковые системы не могут.
Это может привести к штрафам. Ваш сайт должен быть ценным как с точки зрения пользователя, так и с точки зрения поисковой системы. Но пользовательский опыт на первом месте.
И последнее, но не менее важное: важно иметь четкую иерархию сайта.
Если ваш веб-сайт структурирован таким образом, что это затрудняет поиск внутренних страниц, или трудно понять тему в различных разделах вашего сайта, это приведет к ухудшению рейтинга.
И помните, что эти лучшие практики – только те лучшие практики, которые Google опубликовал.
И они держат детали своих алгоритмов в секрете.
Это делается для того, чтобы предотвратить манипулирование результатами поиска.
Имейте в виду, что информация, которую Google предоставляет нам, на самом деле является лишь верхушкой айсберга. Есть много дополнительных факторов, которые скрываются под поверхностью.
Больше информации об этих факторах может быть получено через конференции, блоги, форумы и группы, в которых участвуют представители поисковых систем.
Но большая часть информации исходит от SEO сообщества, которое постоянно отслеживает изменения.
Поэтому важно читать блоги, новости и быть в курсе изменений.
Анализ патентов Google также дает представление о том, как работают алгоритмы, а также о том, какие изменения мы можем увидеть в течение следующих нескольких лет.
Патенты написаны юридическим языком, и их может быть трудно понять.
Но есть один SEO-специалист, по имени Билл Славски, который отлично разбирается в патентах и представляет свою интерпретацию того, как информация, описанная в патенте, повлияла или может повлиять на SEO.
Его блог называется SEO by the sea, и это может быть очень поучительным и занимательным чтением.
Анализируя алгоритмы поисковых систем, SEO сообщество обнаружило множество различных факторов ранжирования.
Они разделяются на три ключевые области.
Факторы на странице – это факторы на определенной странице вашего сайта.
Внешние факторы, это входящие ссылки и упоминания бренда, а также есть факторы уровня домена или сайта, которые являются сигналами, влияющими на ваш сайт в целом.
Таким образом, существует много факторов ранжирования, которые могут улучшить видимость вашего сайта и выдачу в поиске.
Однако существуют также факторы, которые могут привести к тому, что ваш сайт будет заблокирован или оштрафован, если Google посчитает, что вы практикуете спам-тактику SEO, или если они посчитают, что ваш сайт не представляет никакой ценности для пользователей.
Если вы заметили, что ваш рейтинг и трафик резко упали, важно определить, был ли ваш сайт оштрафован и какое наказание могло быть применено.
Иногда сложно определить, под какие обновления попал ваш сайт, потому что они могли быть сделаны в одно и то же время.
Поэтому, на самом деле вы могли попасть под несколько штрафов.
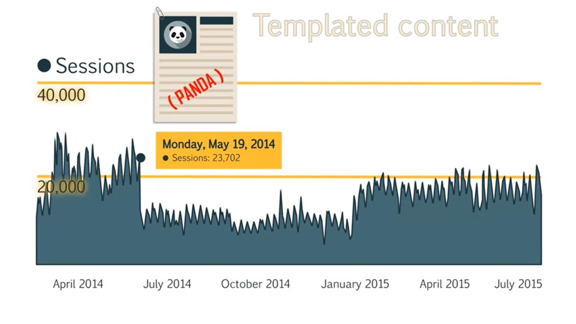
Это пример сайта, который был оштрафован обновлением Panda.
Это был большой сайт, состоящий из сотен страниц с шаблонным контентом.
И содержание этих страниц было очень похожим.
В результате обновления Panda, это привело к большой потере трафика.
Чтобы вернуть трафик, пришлось улучшить навигацию и избавится от дублированного контента на всем сайте и создать оригинальный уникальный контент для ключевых страниц по всему сайту.
Это значительно улучшило трафик, хотя и не вернуло полностью на прежние позиции.
Штрафы нелегко преодолеть и это может привести к огромной потере трафика и доходов.
Если вы считаете, что вас оштрафовали, важно проанализировать ситуацию и ваш сайт, чтобы определить вероятность получения штрафа.
Во-первых, чтобы определить, был ли применен штраф, проверьте аналитику, чтобы увидеть, как изменился трафик.
Вы также можете просмотреть историю своих рейтингов, чтобы увидеть, как работают ваши ключевые слова.
Затем вы должны посмотреть на Google Search Console, который является бесплатным инструментом для веб-мастеров.
Иногда Google отправляет вам туда сообщение и сообщает, был ли наложен штраф.
Затем просмотрите блоги Google, чтобы узнать, объявили ли они какие-либо обновления.
И знайте, что они не всегда объявляют об обновлениях, поэтому не надейтесь на то, что Google предупредит вас или сообщит вам об этом.
Также хорошая идея, проверить MozCast, чтобы посмотреть, есть ли какие-либо странные колебания температуры.
Еще одна хорошая идея – это проверить социальные сети, не жалуются ли другие владельцы сайтов, которые могли столкнуться с той же проблемой.
И штрафы обычно классифицируются на ручное или алгоритмическое наказание.
Некоторые штрафы могут быть как алгоритмическими, так и ручными, в то время как другие, такие как Panda, всегда являются алгоритмическими штрафами.
Алгоритмическими штрафами сайт штрафуется, когда происходит обновление алгоритма.
Это означает, что вам нужно будет определить, какое обновление алгоритма произошло, почему вы были оштрафованы, а затем исправить проблему, связанную с этим штрафом, до того, как произойдет следующее обновление.
Если вы успешно исправите проблемы, тогда ваш сайт будет восстановлен частично или полностью, когда следующее обновление алгоритма повторно оценит ваш сайт.
При ручных штрафах, команда веб-спама Google может обнаружить, что ваш сайт практикует какую-то форму спам-SEO, и оштрафовать ваш сайт.
Когда это происходит, вы обычно получаете уведомление в консоли Google, и вам необходимо подать запрос на пересмотр.
И вы можете подать запрос на пересмотр, только если был применен ручной штраф.
Перед тем, как подать запрос на пересмотр, вы должны исправить проблему, из-за которой ваш сайт был наказан.
Иногда вам может потребоваться отправить запрос на повторное рассмотрение несколько раз, потому что вы не обнаружили или не исправили все проблемы, которые привели к штрафу.
Алгоритмы Google продолжают развиваться, пытаясь отсеять веб-сайты, которые предлагают небольшую или нулевую ценность для пользователя.
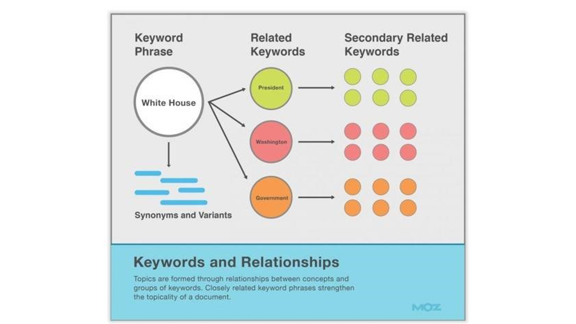
и один из способов, с помощью которого они могут определить полезность документа, – это тематическая ассоциация и семантические отношения между ключевыми словами.
SEO становится все более и более сложным, и SEO больше не определенный контрольный список, которому можно следовать и удостовериться, что вы отметили каждый флажок.
SEO требует более целостного подхода и способности исследовать многие факторы, которые создают уникальные ситуации для каждого сайта.
В первые дни SEO, поисковые системы просматривали содержимое вашей страницы, чтобы узнать, содержит ли оно заданное ключевое слово.
Если это не так, ваш сайт или страница не признавались релевантными для поисковых запросов.
Страницы, содержащие ключевое слово, затем сортировались по рангу в соответствии с релевантностью и авторитетом этой страницы.
В прошлом Google определял релевантность страницы для ключевого слова, просматривая так называемую плотность ключевых слов на странице.
Сколько раз это ключевое слово появляется по отношению к тексту на странице.
И написание контента стало искусством правильного баланса между использованием ключевых слов и контентом.
Если плотность ключевого слова была слишком высокой, страницу можно было считать спамом.
И если плотность была слишком низкой, страница не рассматривалась как релевантная.
Сегодня, требуется не только использовать правильное ключевое слово, но и заботиться об общей концепции страницы.
Используя такие методы, как ассоциация тем и семантический анализ, мы можем писать контент, который лучше привлекает пользователей и позволяет поисковым системам знать, какая тема у страницы и какие ключевые слова относятся к этой странице.
Теперь Google больше изучает контекстуальное значение веб-страницы и контента, размещаемого на сайте, чтобы определить релевантность для темы или набора тем, по которым ваш сайт должен иметь рейтинг.
Это означает, что страница должна содержать ключевые слова, относящиеся к вашему целевому ключевому слову, а не использовать одно ключевое слово и повторять его по всему контенту несколько раз.
Использование слов, связанных с целевым ключевым словом, поможет сделать страницу более релевантной целевому ключевому слову или теме, которую слово пытается представить.
Если страница хочет считаться полезной для читателей, она должна содержать слова и фразы, поддерживающие общую тему.
Это не только улучшит релевантность страницы для темы, но также естественным образом включит то, что называется длинными хвостовыми ключевыми словами.
Ключевые слова с длинным хвостом – это более длинные ключевые слова или фразы, которые создают узко направленные поисковые запросы.
Семантический анализ Google смотрит на то, как связаны слова и какие могут быть отношения между двумя словами.
Амит Сингхал, инженер из Google, рассказал интересную историю о том, как Google учится тому, какие слова являются синонимами
При обсуждении создания этой части алгоритма, как сказал Амит, они обнаружили очень изящную вещь.
Люди меняют слова в своих запросах. Например, кто-то запросит фотографии собак.
А кто-то запросит фотографии щенков.
Это говорит Google о том, что, возможно, слова собаки и щенки взаимозаменяемы.
Google проанализировал миллиарды документов и проанализировал слова, которые были близки друг к другу.
Например, хот-дог будет найден в поисках, которые также содержат хлеб с горчицей, а не в поисках о собаках.
По мере развития алгоритма Google, все меньше внимания уделялось точному термину в порядке используемых слов.
Сейчас вы можете видеть результаты, которые включают в себя слова, в общем относящиеся к запросу.

Помимо всего прочего, наличие бренда не только важно для маркетинговой стратегии, но и может помочь поддержать и активизировать усилия по SEO.
Бренд становится все более важным для алгоритма релевантности Google.
С точки зрения пользователя, считается, что пользователи лучше удовлетворены поисковыми запросами, когда они видят узнаваемые ими бренды, отображаемые в результатах поиска.

Вот пример того, как бренды могут иметь более высокий рейтинг в результатах поиска.
В этом примере мы ищем швейцарский шоколад.




