



Маргарита Васильевна Акулич
Поисковая оптимизация (Search engine optimization – SEO) сегодня и причины неудач. Факторы ранжирования Google. Спамдексинг
© Маргарита Васильевна Акулич, 2022
ISBN 978-5-0056-2711-7
Создано в интеллектуальной издательской системе Ridero
Предисловие

SEO является процессом и маркетинговой стратегией, о которой сегодня, в цифровую эпоху, невозможно не знать ни одному уважающему себя маркетологу.
В предлагаемой книге рассказано основное, что вам следует знать о SEO сегодня, если оно вам интересно и значимо. Также уделено внимание причинам, из-за которых компании терпят неудачу в области SEO, и еще – факторам ранжирования Google (в 2022-м году). И кроме того, рассказано о спамдексинге.
При подготовке данной книги использовались, главным образом, англоязычные источники.
Март 2022-го года. М. В. Акулич
I Понятие поисковой оптимизации (Search engine optimization – SEO) и ее история
1.1 Понятие поисковой оптимизации (SEO). Начальная история
Понятие поисковой оптимизации (SEO)

SEO является жизненно необходимой маркетинговой стратегией, значимой практически для любого бренда, так как оно представляет собой наиболее эффективный, относительно недорогой и не слишком сложный способ налаживания взаимодействия с клиентами. Оно сегодня особенно актуально в условиях усложнения финансового положения компаний и необходимости экономить с одновременным достижением высокой эффективности и прибыльности.
Под поисковой оптимизацией (SEO) понимают процесс, обеспечивающий улучшение трафика (его количества и качества) на веб-страницу либо веб-сайт из поисковых систем. Она является способом, нацеленным на получение бесплатного (неоплачиваемого) трафика (известного в качестве «органических» или «естественных» результатов), а не на оплачиваемый или прямой трафик. Что касается органического трафика, имеет место его получение от разных разновидностей поиска: от поиска видео, поиска академического, поиска изображений, поиска новостей и отраслевых вертикальных поисковиков (или поисковых систем).
SEO рассматривается и в качестве стратегии интернет-маркетинга, принимающей во внимание следующее [1]:
«как работают поисковые системы, запрограммированные компьютером алгоритмы, которые определяют поведение поисковых систем, что люди ищут, фактические поисковые термины или ключевые слова, введенные в поисковые системы, и какие поисковые системы предпочитает их целевая аудитория».
Выполнение SEO происходит благодаря получению веб-сайтом (или веб-страницей) из поисковой системы большего числа посетителей, когда веб-сайты занимают более высокое место на странице результатов поисковой системы (SERP – Search Engine Results Page или результаты, показываемые поисковой системой в ответ на каждый запрос на первой странице поисковой выдачи). Потенциально возможно преобразование данных посетителей в клиентов и лояльных клиентов, и даже в представителей и амбассадоров брендов.
Начальная история

Если говорить о начальной истории SEO, то начало оптимизации веб-сайтов для поисковых систем поставщиками контента и веб-мастерами приходится на 1990-е г. г. (на их середину). Именно в этом временном периоде первыми поисковыми системами (поисковиками) каталогизировалась ранняя сеть.
От веб-мастеров поначалу требовалась лишь отправка адреса страницы либо URL-адреса различным механизмам, которые отправляли веб-сканер для сканирования данной страницы, извлечения из нее ссылок на другие веб-страницы и возврата (для индексации) найденной на странице информации.
Этот процесс включает в себя использование поискового робота, в функции которого входит загрузка страницы и сохранение ее на собственном сервере поисковика (поисковой системы).
Другой программой, программой-индексатором, извлекается информация о странице, такая как содержащиеся в ней слова, месторасположение этих слов, вес для конкретных слов, а также все ссылки, которые присутствуют на странице. После этого обеспечивается помещение всей извлеченной информации в планировщик – в целях последующего сканирования.
К владельцам веб-сайтов пришло осознание значимой ценности высокого рейтинга и видимости в результатах поисковых систем (поисковиков), создающих возможности как для «белых» деятелей (специалистов) в области SEO, так и для деятелей «черных». Отраслевой аналитик Дэнни Салливан предположил, что фраза «поисковая оптимизация» вошла в обиходное применение в 1997-м г.». [1]. Салливан отметил, что по его мнению Брюс Клей – один из первых популияризаторов данного термина.
Ранние версии алгоритмов поиска
Если говорить о ранних (первых) версиях алгоритмов поиска, то можно отметить их ориентацию на информацию, которая предоставлялась веб-мастерами – на индексные файлы в таких системах, как ALIWEB или же на метатеги ключевых слов. Мета-тегами обеспечивается предоставление руководства по содержимому каждой из страниц. Но при использовании для индексации страниц метаданных обеспечивалась весьма малая надежность – из-за того, что выбор веб-мастером ключевых слов в метатеге потенциально может являться неточным представлением фактического содержания веб-сайта.
При наличии ошибочных данных в метатегах, к примеру, при наличии ложных, неполных или неточных атрибутов, создавалась вероятность того, что страницы при нерелевантных поисковых запросах будут неверным образом охарактеризованы.
Поставщики веб-контента в стремлении занятия более высоких позиций в поисковых системах (поисковиках) также были склонны к манипулированию некоторыми атрибутами в HTML -коде страницы.
К 1997-му году к разработчикам поисковых систем пришло осознание того, что веб-мастерами прилагаются усилия для занятия высоких позиций в поисковой системе. Они даже пришли к выводу о манипулировании некоторыми веб-мастерами своими рейтингами в результатах поиска, наполняя страницы нерелевантными либо избыточными (излишними по количеству) ключевиками (ключевыми словами).
Ранними (первыми) поисковиками, такими как Infoseek и Altavista, осуществлялись корректировки собственных алгоритмов – для того, чтобы веб-мастера не имели шансов на манипулирование ранжированием. Они в немалой мере полагались при этом на такую переменную, как плотность ключевых слов, контролируемую исключительно веб-мастерами.
1.2 Ранние поисковые системы страдали от манипулирования рейтингом и злоупотреблений. Google и инструменты Bing
Ранние поисковые системы страдали от манипулирования рейтингом и злоупотреблений

В отношении ранних поисковых систем можно сказать, что у них были проблемы, связанные со злоупотреблениями и манипулированием рейтингом. Для предоставления своим пользователям лучших результатов, поисковым системам требовалась адаптация, – ради отображения несвязанных страниц, набитых многочисленными ключевыми словами не обремененными добросовестностью веб-мастерами, с помощью по максимуму релевантных результатов поиска. Им было необходимо избавление от сильной зависимости от плотности терминов, и требовался переход к более целостному процессу оценки семантических сигналов.
Популярность и успех поисковой системы обеспечиваются ее способностью давать самые релевантные результаты для любого заданного поиска. По этой причине при нерелевантных ли невысоких результатах поиска пользователи могут осуществить поиск иных источников поиска. Из-за этого поисковиками были разработаны более сложные алгоритмы ранжирования с принятием во внимание факторов, которыми веб-мастерам оказалось проблематичнее манипулировать.
Когда компании шли на использование чрезмерно агрессивных способов, у них появлялся шанс блокировки веб-сайтов своих клиентов в результатах поиска. Вот пример [1]:
«В 2005-м году Wall Street Journal сообщил о компании Traffic Power, якобы использовавшей методы высокого риска и не сообщившей об этих рисках своим клиентам.
Журнал Wired сообщил, что та же компания подала в суд на блогера и SEO-специалиста Аарона Уолла за то, что он написал о запрете. Мэтт Каттс из Google позже подтвердил, что Google действительно заблокировал Traffic Power и некоторых ее клиентов».
Некоторые из специалистов из поисковых систем также обратились к индустрии SEO и стали весьма нередкими участниками и спонсорами посвященных SEO конференций, семинаров и веб-чатов. Основные поисковые системы сосредоточились на предоставлении пользователям информации и рекомендаций, помогающих обеспечению оптимизации веб-сайта.
Google и инструменты Bing

Google имеет программу Sitemaps, помогающую веб-мастерам узнавать, есть ли у Google какие-либо проблемы с индексацией их веб-сайтов, а также предоставляющую данные о Googl-трафике на веб-сайт.
Благодаря Bing Webmaster Tools (инструментам Bing для веб-мастеров) веб-мастера могут отправлять карту сайта и веб-каналы, пользователи получают возможность определения «скорости сканирования» и отслеживания статуса индексации веб-страниц.
В 2015-м г. сообщалось, что [1]:
«Google разрабатывает и продвигает мобильный поиск как ключевую функцию будущих продуктов».
В ответ многие бренды стали подходить к своим стратегиям интернет-маркетинга по-иному.
1.3 Основание Google. Учет факторов на странице и вне страницы
Основание Google

Год 1998-й. Этот год ознаменовался разработкой Ларри Пейджем и Сергеем Брином, являвшимися аспирантами Стэнфордского университета, поисковой системы «Backrub», опиравшейся для оценки известности веб-страниц на математический алгоритм. Рассчитанное алгоритмом PageRank число – это функция количества и силы входящих ссылок.
PageRank обеспечивает оценивание вероятности того, что случайным образом просматривающий веб-страницы и переходящий по ссылкам с одной страницы на другую веб-пользователь достигнет данной страницы. Это, по сути, означает, что некоторые из ссылок являются более сильными в сравнении с другими, так как имеющая более высокий PageRank страница с большей вероятностью будет достигнута случайным пользователем интернет-сети.
Основанному Пейджем и Брином в 1998-м г. Google удалось привлечь лояльных поклонников среди растущего числа интернет – пользователей, очарованных его простым дизайном.
Учет факторов на странице и вне страницы
Чтобы позволить Google избежать манипуляций. в поисковых системах, принимавших во внимание для своего рейтинга лишь факторы на странице, учитывались факторы вне страницы (такие как PageRank и анализ гиперссылок), а также факторы на странице (такие как метатеги, частота ключевых слов, ссылки, заголовки и структура сайта).
Хотя обмануть PageRank оказалось проблематичнее, веб-мастера уже разработали инструменты и схемы построения ссылок, – в целях влияния на поисковый движок Inktomi, и эти методы также оказались применимыми к игровому PageRank.
Многие сайты оказались ориентированными на обмен, покупку и продажу ссылок, причем нередко в довольно массовом масштабе. Некоторые из этих схем, или ссылочных ферм предусматривали создание тысяч сайтов с одной единственной целью – целью рассылки ссылочного спама.

1.4 Поисковые системы к 2004-му году. и в 2005-м году. Google в период 2007-го 2009-го годов
Поисковые системы к 2004-му году и в 2005-м году
К 2004 году поисковыми системами в свои алгоритмы ранжирования – ради уменьшения влияния манипулирования ссылками – было обеспечено включение широкого спектра нераскрытых факторов.
Год 2005-й явился годом начала персонализации результатов поиска для каждого пользователя. Google создал результаты для вошедших в систему пользователей в зависимости от историй их предыдущих поисков.
Google в период 2007-го – 2009-го годов
Год 2007-й (июнь). Это было время заявления Сола Хансела из The New York, что [1]:
«Google ранжирует сайты, используя более 200 различных сигналов».
Такие ведущие поисковые системы, как Google, Bing и Yahoo не раскрывают алгоритмы, используемые ими для ранжирования страниц. Некоторыми специалистами по поисковой оптимизации были исследованы разные подходы к поисковой оптимизации, и они высказались по поводу своего личного мнения. Для лучшего понимания поисковых систем связанные с поисковыми системами патенты могут предоставить соответствующую информацию.
Год 2007-й был годом объявления Google кампании против платных ссылок, передающих PageRank.
Год 2009-й (пятнадцатое июня). Это было время сообщения Google о принятии мер по смягчению последствий «скульптуры PageRank» путем использования для ссылок атрибута nofollow.
Известный инженер-программист из Google Мэтт Каттс заявил, что [1]:
«бот Google больше не будет одинаково относиться к ссылкам с атрибутом nofollow, чтобы предотвратить использование SEO-провайдерами атрибута nofollow для ваяния PageRank».
В результате этого изменения использование nofollow привело к ваянию PageRank. SEO-инженерами были разработаны альтернативные методы, заменяющие теги nofollow на обфусцированный JavaScript и позволяющие использовать PageRank. Помимо этого, был предложен ряд решений, включающих использование iframes, Flash и JavaScript.
Год 2009-й (декабрь). Это было время объявления Google об использовании для наполнения результатов поиска историй веб-поиска всех своих пользователей.

1.5 Google в 2010-м году. Google в период 2011 – го – 2019-го годов
Google в 2010-м году
Год 2010-й (восьмое июня). Это было время объявления о новой системе веб-индексирования под названием Google Caffeine. Ее разработали, чтобы у пользователей появилась возможность нахождения намного быстрее, чем прежде, сообщений на форумах, результатов новостей и иного контента.
Алгоритм Google Caffeine явился изменением способа, которым Google обеспечил обновление своего индекса, чтобы вещи отображались в Google стремительнее, чем прежде. По словам инженера-программиста Кэрри Граймса, анонсировавшего Caffeine для Google [1]:
«Caffeine обеспечивает на 50% более свежие результаты веб-поиска, чем наш последний индекс…»
Год 2010-й (конец. Это было время представления Google Instant, поиска в реальном времени, что объяснялось стремлением сделать результаты поиска более релевантными и своевременными. Исторически сложилось так, что администраторы веб-сайтов тратили месяцы или даже годы на оптимизацию сайтов для повышения рейтинга в поисковой выдаче. Поскольку росла популярность блогов и соцсетей, ведущими поисковыми системами были внесены в свои алгоритмы изменения, – чтобы свежий контент ранжировался в результатах поиска быстро.
Google в период 2011-го – 2019-го годов

Источник: https://www.0ptim1ze.com/4-ways-you-work-for-google/
Год 2011-й (февраль). Это было время объявления Google об обновлении Panda, наказывающего сайты, содержащие контент, продублированный с других сайтов и источников. Исторически сложилось так, что за счет такой практики сайты копировали контент друг у друга и добивались выигрыша в рейтинге поисковых систем. Однако Google обеспечил внедрение новой системы, наказывающей веб-сайты, контент которых не отличается таким важнейшим свойством, как уникальность.
Год 2012-й был годом попытки обновления Google Penguin, чтобы можно было наказывать веб-сайты, использовавшие манипулятивные методы с целью повышения своего рейтинга в поисковой системе. Хотя Google Penguin был представлен в качестве алгоритма, нацеленного на сражение с веб-спамом, на самом деле он сосредоточен на спамерских ссылках, он оценивает качество сайтов, с которых ссылки поступают.
Год 2013-й стал годом появления обновления Google Hummingbird, представляющего собой изменение алгоритма, нацеленное на улучшение семантического понимания веб-страниц и обработки естественного языка Google.
Если говорить о системе обработки языка Hummingbird с точки зрения терминологии, она подпадает под признанный термин «разговорный поиск», когда системой уделяется больше внимания каждому слову в запросе – ради лучшего сопоставления запросов страниц со смыслом, а не с рядом слов.
Что касается изменений, внесенных в поисковую оптимизацию, то для писателей и издателей контента Hummingbird призван решать проблемы путем избавления от спама и нерелевантного контента, позволяя Google производить контент высокого качества и полагаться на него как на контент «надежных» авторов.

Год 2019-й (октябрь). Это было время объявления Google о начале применения в Соединенных Штатах Америки для поисковых запросов на английском языке модели BERT.
Представления двунаправленного кодировщика от Transformers (BERT) являлись еще одной попыткой Google обеспечить улучшение обработки естественного языка, но на этот раз – ради улучшения понимания поисковых запросов своих пользователей.
Модель BERT с позиции поисковой оптимизации предназначалась для облегчения соединения пользователей с релевантным контентом и для повышения уровня качества поступающего на веб-сайты, занимающие высокие позиции на странице результатов поисковой системы, трафика.
II Используемые поисковыми системами методы. SEO как маркетинговая стратегия. Международные рынки. Юридические прецеденты
2.1 Получение индексации. Запрещение сканирования

Получение индексации
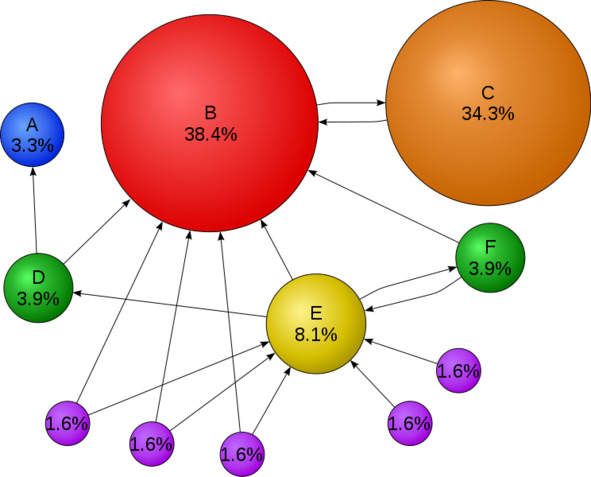
«На этой диаграмме, где каждый кружок представляет собой веб-сайт, программы, иногда называемые поисковыми роботами, проверяют, какие сайты ссылаются на какие другие сайты, со стрелками, представляющими эти ссылки. Веб-сайты, получающие больше входящих ссылок или более сильные ссылки, считаются более важными и являются тем, что ищет пользователь. В этом примере, поскольку веб-сайт B является получателем многочисленных входящих ссылок, занимает более высокое место в веб-поиске. И ссылки „проникают“, так что сайт C, даже если он имеет только одну входящую ссылку, имеет входящую ссылку с очень популярного сайта (B), а сайт E – нет. Примечание: проценты округлены». Источник: https://en.wikipedia.org/wiki/Search_engine_optimization
Поисковыми системами используются сложные математические алгоритмы – в целях интерпретации того, какие веб-сайты ищутся пользователями.
Такими ведущими поисковыми системами, какими в настоящее время являются Google, Bing и Yahoo!, для поиска страниц в результатах алгоритмического поиска используются краулеры (поисковые роботы, или веб-краулеры).
Страницы, на которые ведут ссылки с других проиндексированных поисковыми системами страниц, не нужно представлять, поскольку их находят автоматически. Yahoo! _ Directory и DMOZ, – это крупные каталоги, закрывшиеся в 2014-м и в 2017-м годах соответственно, требующие редакторской проверки человеком и ручной подачи.
Google предлагает (в дополнение к своей консоли отправки URL) Google Search Console, для нее можно бесплатно создать и отправить XML Sitemap, чтобы гарантировать, что все страницы будут найдены, особенно страницы, которые нереально обнаружить, автоматически переходя по ссылкам.
Прежде Yahoo! предоставлял платные услуги по отправке, гарантировавшие сканирование за стоимость клика; однако в 2009-м г. эта практика прекратилась.
При просмотре веб-сайта поисковые машины могут учитывать множество различных факторов. Поисковыми системами индексируется не каждая страница. Удаленность страниц от корневого каталога сайта также может являться фактором, влияющим на то, будут ли страницы проиндексированы.
Год 2016-й (ноябрь). Это было время объявления Google о серьезных изменениях в способе поиска веб-сайтов и начала действия его индекса mobile-first, это означает, что мобильная версия данного веб-сайта становится отправной точкой для того, что Google включает в свой индекс.
Год 2019-й (май). Это было время обновления Google движка рендеринга своего сканера до последней версии Chromium (74 на момент объявления).
Google было указано, что он будет обеспечивать регулярное обновление движка рендеринга Chromium до последней версии.
Год 2019-й (декабрь). Это было время начала обновления Google строки User-Agent своего краулера – ради отражения последней версии Chrome, используемой его службой рендеринга. Здесь наблюдалась задержка, вызванная необходимостью дать вебмастерам время на обновление кода, реагирующего на определенные строки User-Agent ботов. Google провел оценку и был уверен, что влияние окажется несущественным.

Год 2016-й (ноябрь). Это было время объявления Google о серьезных изменениях в способе поиска веб-сайтов и начала действия его индекса mobile-first, это означает, что мобильная версия данного веб-сайта становится отправной точкой для того, что Google включает в свой индекс. Сегодня, как мы знаем, большинство людей осуществляет поиск в Google с помощью мобильных устройств.
Год 2019-й (май). Это было время обновления Google движка рендеринга своего краулера до последней версии Chromium (74 на момент объявления). Google было указано, что он станет обеспечивать регулярное обновление движка рендеринга Chromium до последней версии.
Год 2019-й (декабрь). Это было время начала обновления Google строки User-Agent своего краулера – ради отражения последней версии Chrome, используемой его службой рендеринга. Здесь наблюдалась задержка, вызванная необходимостью дать вебмастерам время на обновление кода, реагирующего на определенные строки User-Agent ботов. Google провел оценку и был уверен, что влияние окажется несущественным.
Запрещение сканирования

В целях избежания нежелательного индексирования какого-то контента, веб-мастер может запретить поисковым роботам сканировать определенные файлы или каталоги – через стандартный файл robots. txt в корневом каталоге домена. Помимо этого, страницу можно явным образом исключить из базы данных поисковика (поисковой системы). Это делается с помощью специального метатега для роботов (как правило, – <meta name=«robots» content=«noindex»>).
Когда поисковая система посещает веб-сайт, файл robots. txt, – это первый, расположенный в корневом каталоге просканированный файл. Затем файл robots. txt подвергается анализу и роботу указывается, какие страницы сканировать не следует. Поскольку сканер поисковой системы способен хранить кэшированную копию данного файла, он может иногда сканировать те страницы, которые веб-мастер подвергать сканированию не желает.
Обычно запрещенные для сканирования страницы – это страницы, связанные с входом в систему, такие как корзины покупок и такой пользовательский контент, как результаты внутреннего поиска.
Год 2007-й (март). Это было время предупреждения Google вебмастеров, что им следует запретить индексацию результатов внутреннего поиска, так как эти страницы считаются поисковым спамом.
Год 2020-й был годом закрытия Google стандарта и открытия своего кода. И в настоящее время Google рассматривает его не в качестве директивы, а в качестве подсказки. Для надлежащего гарантирования того, что индексации страниц не произойдет, необходимо включение метатега робота на уровне страницы.




