



Алексей Колоколов
Азбука визуализации Power BI
Пошаговое руководство для линейчатой диаграммы
Линейчатые диаграммы, также как и столбчатые, используются для отображения рейтинга, количественных сравнений, но чаще в тех случаях, когда данные уже не помещаются на вертикальные столбцы.
Построим линейчатую диаграмму на основе полей Факт продаж и Product subcategory (далее Подкатегория продукта), которое содержит более 10 наименований с большим количеством знаков. Исходный внешний вид диаграммы также не соответствует нашим стандартам (рисунок 3–8). Поэтому, давайте снова пройдемся по пошаговому руководству. Шаги здесь будут такими же, как для столбчатых диаграмм.

Рисунок 3–8. Вид диаграммы по умолчанию (слева) и окончательный вид (справа).
Шаг 1: Включить и настроить метки данных
Раздел Метки данных для линейчатой диаграммы содержит те же опции, что и для столбчатой (рисунок 3–3), поэтому мы не будем повторять их описание.
Обратите внимание, что для самого большого значения метка может быть расположена внутри полосы, а для остальных – снаружи. В этом и заключается суть параметра Положение по умолчанию – Авто (рисунок 3–3). Power BI автоматически поместил метку внутрь, чтобы обеспечить больше места для полосы, и даже инвертировал цвет метки на темном фоне.
Шаг 2. Отключить ось значений (ось X)
В общем случае мы говорим об "оси значений": для столбчатой диаграммы это ось Y, а для столбчатой – ось X. Правило одно и то же: если мы включили метки данных, то ось значений не нужна. Вы можете настроить ее таким же образом, как показано на рисунке 3–5, но вместо оси Y вы будете работать с осью X. Не забудьте отключить название оси.
Давайте рассмотрим исключение из правила. Бывают случаи, когда разница в диапазоне данных минимальна, а столбцы (как вертикальные, так и горизонтальные) выглядят совершенно одинаково (рисунок 3–9 слева). В нашем наборе данных это произойдет, если мы будем сравнивать продажи по полю Manager (далее Менеджер). В таком случае мы можем изменить начало оси значений (X или Y) вручную. Тогда ось мы не отключаем – она покажет нам масштаб, чтобы было понятно, что разница между условным Ивановым и Петровым не трехкратная (рисунок 3–9 справа). Здесь важно понимать возможный диапазон числовых показателей с учетом возможных фильтров и минимальным ограничением по оси не отрезать часть данных.

Рисунок 3–9. Слева – ось X отложена от нуля, трудно заметить разницу. Справа – ось X установлена от 35 тысяч, разница четко видна.
Шаг 3. Настроить метки категорий на оси Y
Технически параметр оси категорий работает как и для столбчатой диаграммы, отличаясь только названием – ось X вместо оси Y. Но есть смысловая разница для параметра Максимальная ширина категории (Max area width) в разделе Значения (Values). Если мы начнем уменьшать ширину всего графика, текст будет обрезаться. Это не критично, если мы потеряем только несколько последних букв. Но, иногда, это может стать значимым барьером для восприятия данных пользователем. На рисунке 3-10 слева это наглядно показано – названия категорий сокращены до непонятных “Tires and…, “Mountain…” и т. д.
По умолчанию ширина области категорий выставлена в 25 % от области всей диаграммы. Мы можем увеличить это значение максимум до 50 % введя нужное значение в поле или перетащив ползунок вправо. Это не гарантирует, что все метки поместятся, но читаемыми они будут точно. Если вы обнаружите, что при этом для визуализации места не хватает – растяните весь график по ширине.
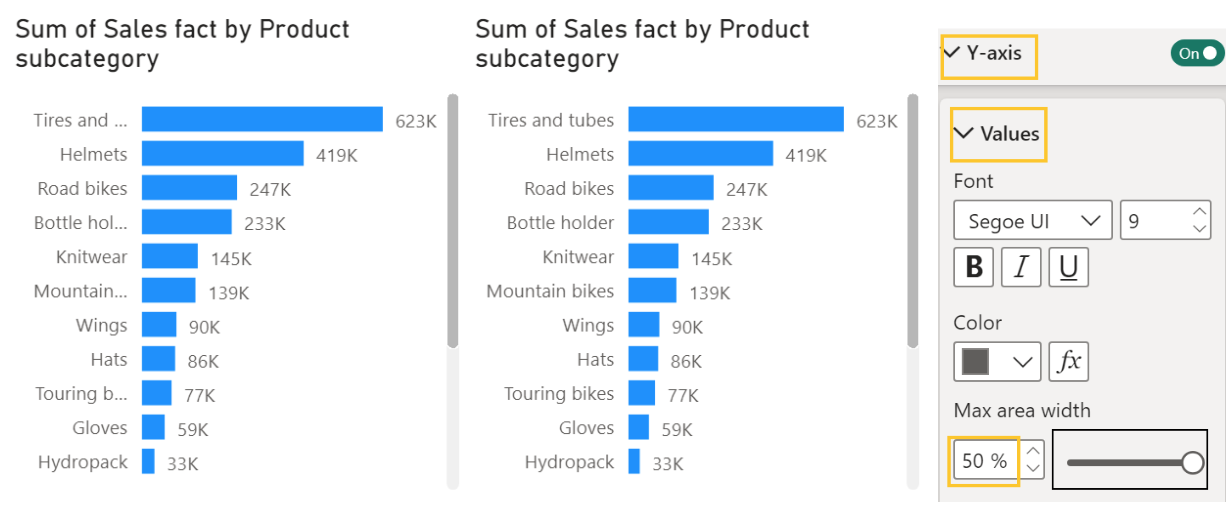
Рисунок 3-10. Максимальная ширина области категорий: обрезанные заголовки слева и увеличенная область справа, заголовки видны полностью.
Шаг 4. (Опционально) Отрегулировать ширину полосы
Если мы начнем уменьшать высоту графика, то в определенный момент справа появится полоса прокрутки. Это также может произойти со столбчатыми диаграммами, если сжимать их по горизонтали. Хорошо, что Power BI не позволяет нам бесконечно «сплющивать» полосы и столбцы и всегда сохраняет ширину оптимальную для чтения. Но как управлять этим параметром?
Перейдем к разделу Полосы (Bars) – Макет (Spacing). Пространство между категориями (Inner interval) – это расстояние между полосами или столбцами. Интервал по умолчанию 20px является оптимальным. Следующий пункт Минимальная ширина категории, определяет, насколько сильно могут «сжаться» полосы (рисунок 3-11). По смыслу это “толщина полосы”. Здесь по умолчанию установлено значение 20px, и это тоже оптимальное значение. Но в зависимости от диапазона данных и размера области диаграммы, нам может понадобиться его изменить.

Рисунок 3-11. Ширина категории: 20px (слева) и увеличенные 30px (справа).
Увеличив толщину столбцов, мы убрали 5 меньших значений за пределы области прокрутки и сделали акцент на верхних категориях. Этот шаг не является обязательным в нашем руководстве, но иногда может быть очень полезным. В Power BI, конечно, можно установить ТОП-10 или другое фиксированное значение с помощью фильтров или преобразований данных, но это действие обрежет часть категорий, а вот такая ручная настройка толщины столбцов позволяет отобразить визуально нужный диапазон и при этом сохранить возможность просмотра всех данных.
Шаг 5. Отредактировать название диаграммы
Этот шаг полностью идентичен настройкам столбцовой диаграмме (рисунок 3–7), как и другие параметры в разделе Общие. Раскройте поле Заголовок и сократите формулировку до "Продажи по подкатегориям", и вы придете к примеру настроенной диаграммы на рисунке 3–6, с которого началось пошаговое руководство.
Проблемы фильтрации данных
Отчет в Power BI отличается от слайдов презентации интерактивностью – данные обновляются, а количество категорий и диапазон значений изменяются в зависимости от применяемых фильтров. В результате этого ваш настроенный в статике красивый график может выглядеть не так хорошо. Давайте обсудим две общие проблемы, с которыми мы сталкиваемся при обновлении и фильтрации данных и их влияние на внешний вид визуализаций. Эти проблемы применимы как к столбчатым, так и к линейчатым диаграммам.
1. Метки данных начинаются с 0
Допустим, в параметре Метки данных в Единицах измерения вы установили отображение в миллионах вместо настройки Авто (рисунок 3–4). Затем, вы применили фильтры по дате и региону, и у вас получились одинаковые метки типа 0.02M для первых трех столбцов с разными значениями. Отсюда совершенно непонятно каковы же реальные значения (рисунок 3-12 слева). В этом случае лучше переключиться на тысячи или оставить параметр Авто – он сам подставит нужные единицы измерения, как показано на рисунке 3-12 справа.
 Рисунок 3-12. Малопонятые (слева) и наглядные (справа) единицы измерения для меток данных.
Рисунок 3-12. Малопонятые (слева) и наглядные (справа) единицы измерения для меток данных.
2. Метки категорий расположены под наклоном
Не всегда можно увеличить ширину диаграммы так, чтобы текст на оси X уместился горизонтально. Очень часто пространство на дашборде под каждую диаграмму ограничено и нам приходится отступать от рекомендуемых для удобного чтения размеров шрифта. Так, в подписях категорий по оси Х, шрифт 12 пт мы будем уменьшать до 9-10 пт, чтобы все уместилось без поворота (рисунок 3-13).
 Рисунок 3-13. Подписи по оси X всегда должны быть строго горизонтальными.
Рисунок 3-13. Подписи по оси X всегда должны быть строго горизонтальными.
Кросс-фильтрация визуальных элементов
Часто на диаграмме необходимо показать внутренние детали категорий, разбив их на подкатегории. В то время как новички иногда пытаются уместить все данные в один столбец, опытные аналитики избегают этого. Power BI имеет мощную систему перекрестной фильтрации. Она применяется ко всем визуальным элементам на дашборде и вы можете рассматривать любые подкатегории и факторы интересующей категории без объединения их в одну диаграмму. С помощью фильтрации из среза или с самой диаграммы вы увидите нужные данные на других визуализациях. Главное, чтобы все интересующие категории были представлены хотя бы в одном срезе или на одной диаграммы.
Представьте, что вы хотите отобразить продажи для различных подкатегорий по странам. Если вы создадите диаграмму со сложенными столбцами, она может стать загроможденной: мы можем сравнить высоту и пропорции двух первых категорий, но в остальных сектора по странам превращаются в тонкие полоски, на которые даже не помещаются метки данных (рисунок 3-14).

Рисунок 3-14. Столбчатая диаграмма, на которой трудно разглядеть детали.
Мы предлагаем разместить рядом две отдельные диаграммы: продажи по странам и продажи по подкатегориям. Используя возможности кросс-фильтрации, мы можем получить все данные о продажах по каждой стране в каждой подкатегории. Так, щелкнув на столбце продаж в USA, на соседней диаграмме мы увидим выделенные продажи для каждой подкатегории в этой стране (рисунок 3-15).
 Рисунок 3-15. Кросс-фильтрация диаграмм по продажам в USA.
Рисунок 3-15. Кросс-фильтрация диаграмм по продажам в USA.
В обратную сторону перекрестная фильтрация работает таким же образом: если мы выберем столбец Helmets на правой гистограмме, то на левой подсветятся продажи этой товарной категории во всех странах.

Рисунок 3-16. Кросс-фильтрация диаграмм по продажам в подкатегории Helmets.
Перекрестная фильтрация (она же кросс-фильтрация) – это супер возможность интерактивных отчетов Power BI, которой мы настоятельно рекомендуем пользоваться по максимуму.
Однако, есть некоторые нюансы, которые следует учитывать в каждом конкретном случае. Например, если вы зададите метки данных в миллионах, при фильтрации вы можете увидеть нули, потому что, продажи одного менеджера исчисляются десятками тысяч. Поэтому, задавая величину данных, следует учитывать, как они будут отображаться при фильтрации.
Резюме
По своему назначению столбчатая диаграмма подходит для двух видов анализа: динамики и рейтинга. Линейчатые диаграммы используются для отображения количественных сравнений, преимущественно в тех случаях, когда данные плохо укладываются в столбчатую диаграмму.
Чек-лист по настройке столбчатой / линейчатой диаграммы:
1. Включить и настроить метки данных.
2. Отключить ось значений (Y для столбчатой и X для линейчатой).
3. Настроить метки оси категорий (X для столбчатой и Y для линейчатой). Для линейчатой диаграммы обычно требуется увеличить область подписей категорий по сравнению со стандартными 25 %.
4. Отрегулировать ширину столбца или полосы (опционально).
5. Отредактировать название диаграммы.
6. Настроить цвета столбцов/полос и меток данных (опционально).
Отчет в Power BI отличается от слайдов презентации интерактивностью – данные обновляются, а количество категорий и диапазон значений изменяются в зависимости от применяемых фильтров. Поэтому, дважды проверьте, правильно ли отображаются данные и метки категорий при различных вариантах фильтрации.
Скачать pbix файл с настроенными визуалами
Глава 4. Круговая и кольцевая диаграммы
Отличная визуальная метафора для отображения структуры – это пирог. Мы делим его на части и смотрим, кому достался самый большой кусок, или, например, какие игроки поделили между собой половину рынка. Мы ставим акцент не на количественное сравнение (больше или меньше), как это было со столбцами, а на долю от целого (проценты).
Кольцевая диаграмма имеет точно такой же смысл, как и стандартная круговая (пироговая) диаграмма. Она строится точно по таким же параметрам и отличается только наличием пустого пространства внутри (рисунок 4–1). Из-за этого ее еще называют пончиковой или “бубликовой”. В этой главе мы предоставим руководство по настройке круговой диаграммой. Оформить “пончик” вы сможете аналогичным образом.

Рисунок 4–1. Круговая диаграмма (слева) и кольцевая диаграмма (справа).
Построить круговую диаграмму очень просто: помещаем категории (Страны) в поле Условные обозначения (Legend), а количественный показатель (Продажи факт) – в поле Значения (Values). Оформление по умолчанию выглядит не так уж плохо (рисунок 4–2):
* Сегменты отсортированы в порядке убывания количественного показателя, что верно, ведь важно в первую очередь видеть, в какой стране самая большая доля продаж.
* Включены метки данных.
* Цвета сегментов достаточно контрастные, не сливаются между собой (но это еще зависит от цветовой темы вашего отчета).
 Рисунок 4–2. Круговая диаграмма по умолчанию и поля для нее
Рисунок 4–2. Круговая диаграмма по умолчанию и поля для нее
Рассмотрим, что нужно сделать, чтобы привести диаграмму к идеальному виду. Это руководство будет коротким, поскольку в круговых диаграммах нет понятия осей X и Y. Нам нужно будет выполнить только следующие шаги:
1. Настроить подписи категорий рядом с метками данных.
2. Удалить легенду, которая будет дублировать информацию в подписях данных.
3. Настроить внутренний радиус (для кольцевой диаграммы).
4. Отредактировать название диаграммы.
В конце мы разберем пару дополнительных опций и типовых ошибок.
Пошаговое руководство для круговой и кольцевой диаграммы
Шаг 1. Настроить метки данных
В отличие от столбчатых диаграмм, на круговой метки данных появились сразу, и включать их не нужно. Но на рисунке 4–2 вы видите, что они показывают и абсолютные, и процентные значения. Мы понимаем, что бывает важно видеть и то, и другое, но с точки зрения визуализации следует расставить приоритеты. В противном случае, при попытке показать “все и сразу” не будет видно ничего.
Не удивляйтесь, если вы не увидите пункт Метки данных в опциях визуального форматирования. Здесь он называется Метки подробностей (Detail labels).
На рисунке 4–3 показаны варианты Содержания метки (Label contents) в выпадающем меню:
* Категория – отображает только название категории.
* Значение данных – отображает только числовой показатель (в нашем случае факт продаж).
* Процент от общего – отображает долю сегмента
в общем объеме. Обычно это – самый важный аспект круговой диаграммы.
Далее следуют различные комбинации этих элементов.
Пользователя отчета в первую очередь интересует структура. Поэтому, мы советуем выбрать вариант Категория + Процент от общего. Категорию важно показывать рядом с числовым значением, а не уносить в легенду, чтобы облегчить восприятие данных. В случае с легендой пользователь вынужден соотносить маленькие цветные точки в легенде с цветами сегментов диаграммы и всегда держать в голове название категории, когда он видит числовое значение. Это неудобно.

Рисунок 4–3. Варианты меток подробностей (меток данных).
Перейдем к подписям значений (рисунок 4–4) и настроим их по тому же алгоритму, что и в столбчатой диаграмме:
* Выставляем размер шрифта 12 пт. Если при этом названия категорий или метки данных помещаются не полностью (обрезаются), то уменьшить шрифт 9-11 пт.
* Единицы измерения оставляем Авто или Нет, так как данные представлены в процентах. Если для других задач вы будете выбирать отображение значений данных, то на них будут действовать такие же правила по настройке единиц измерения, как для столбчатых диаграмм.
* В Десятичных разрядах для процентов указываем 0 или 1. 2 и более знаков после запятой для процентов не будет нести большого смысла.

Рисунок 4–4. Значения меток подробностей.
Шаг 2. Отключить легенду
Названия категорий теперь размещаются рядом с сегментами, а легенда их дублирует. Соответственно, в ней нет необходимости и нам следует отключить этот элемент (также, как в столбчатых диаграммах при настроенных метках данных мы поступили с осью Y). Обратим ваше внимание, что легенда в настройках круговой диаграмме называется Условные обозначения.
Шаг 3. Настроить внутренний радиус
При работе с кольцевой диаграммой первые два шага идентичны. Дополнительно добавляется настройка внутреннего радиуса, который влияет на размер пустого пространства в центре диаграммы. Развернем раздел Срезы и пункт Интервал в нем (рисунок 4–5).
По умолчанию радиус внутреннего круга составляет 60 %. Не советуем его увеличивать. На рисунке 4–5 слева показан вариант с радиусом 80 %. На нем сама визуализация стала слишком тонкой, а доминирующее пустое пространство переключает на себя внимание и читателю сложно сфокусироваться на данных. Мы рекомендуем оставить радиус по умолчанию или уменьшить его до 50 % (рисунок 4–5 справа). Так диаграмма будет выглядеть сбалансированно.

Рисунок 4–5. Кольцевая диаграмма с радиусом 80 % (слева) и 50 % (справа).
Шаг 4.Отредактировать название диаграммы
Этот шаг характерен для любого типа диаграмм (мы обсуждали его в главе 1 в разделе "Анатомия диаграмм/ Заголовок диаграммы"). Для настройки заголовка перейдите на вкладку Общие, выберите Заголовок и введите лаконичное название в параметре Текст. Например, вместо "Сумма факта продаж по странам" вы можете указать "Факт продаж по странам".
Типовые ошибки
Круговая диаграмма довольно проста в построении, и иногда хочется добавить в нее какую то фичу, изюминку. Но обычно такие эксперименты терпят неудачу. На классических визуализациях старайтесь следовать подходу “одна мысль – одна диаграмма”. Как работать с комплексными данными мы расскажем во второй части книги “Продвинутая визуализация”.
Ошибка 1. Поворот
Поворот (Rotation) – это последний параметр на панели настройки визуализации, который есть как у круговых, так и у кольцевых диаграмм.
По умолчанию диаграмма сортируется по убыванию – от большего числового показателя к наименьшему, а первый сектор начинается с 0° (как циферблат часов начинается с 12). Это – традиционный способ представления структурных данных.
Вы, конечно, можете проявить творческий подход и изменить начальную точку отсчета, например, на 90°, как показано слева на рисунке 4–6. В этом случае на первом месте окажется Germany, затем France и, наконец, USA с наибольшей долей. Однако, это вызовет вопросы о принципе сортировки, особенно у сегментов с незначительной разницей (Germany и France). Точно также может произойти, если вы решите отсортировать сегменты не по числовому значению, а, например, в алфавитном порядке категорий. Это значительно усложнит восприятие данных. Поэтому, в круговых диаграммах всегда оставляйте угол поворота по умолчанию 0° и сортировку по числовому показателю.

Рисунок 4–6. Ротация на 90° вызывает вопросы к сортировке данных (слева) и угол поворота по умолчанию 0° (справа).
Ошибка 2. Детали (иерархический вид)
В начале главы, когда мы создавали круговую диаграмму, мы разместили данные в полях Условные обозначения и Значения (рисунок 4–2). Однако, необходимо рассмотреть еще одно поле – Подробнее (Details). Оно позволяет создавать иерархическое представление. На рисунке 4–7 мы видим структуру продаж по категориям: каждая категория обозначена своим цветом. Внутри категории разделены на более мелкие сегменты – подкатегории.

Рисунок 4–7. Неупорядоченное представление иерархических данных.
Мы понимаем, что обычная круговая диаграмма может показаться слишком простой, и кому-то захочется добавить в нее больше информации. Но, как мы видим, при добавлении деталей диаграмма становится перегруженной – слишком узкие сегменты, много подписей данных и часть из них сокращается или не отображаться совсем. К тому же, сегменты подкатегорий внутри категорий можно отсортировать только в алфавитном порядке, что не позволяет анализировать информацию должным образом.
Такое представление может быть эффективным только в том случае, если каждая категория содержит 2–3 категории, не больше. Мы могли бы создать такой учебный пример, но на практике с подобным сценарием мы не сталкивались. Второй уровень иерархии всегда содержит более 10 элементов, и они не помещаются на круговой или кольцевой диаграмме. Для этих целей существуют другие типы диаграмм, которые мы рассмотрим в следующих главах.
Резюме
Круговая и кольцевая диаграммы имеют одинаковый смысл – визуализируют структуру для небольшого числа категорий (обычно не больше 6). Диаграммы строятся по одинаковым параметрам и отличаются только тем, что кольцевая имеет пустое пространство внутри. У них нет осей Х и Y и для их настройки достаточно сделать 4 простых шага.
Чек-лист для круговой / кольцевой диаграммы
1. Настроить метки данных: категория и процент от общего.
2. Удалить легенду, которая дублирует информацию в метках данных.
3. Настроить внутренний радиус (для кольцевой диаграммы).
4. Отредактировать название диаграммы.
Помимо этих настроек есть еще 2 параметра с которыми нужно быть осторожными:
* Поворот. Всегда оставляйте угол поворота по умолчанию 0° (другими словами на 12 часов).
* Детали. Мы не рекомендуем добавлять подкатегории внутри секторов диаграммы. С ними она становится перегруженной, а подкатегории – неупорядоченными.

