



Илья Леонидович Хохлов
Самоучитель. Курс SQL. Базы данных. ORACLE
Введение
Здравствуй, уважаемый читатель!
Вероятно, ты уже немного знаешь, что такое SQL и для чего он нужен. Или, по крайней мере, немного про него слышал. Скорее всего, это сейчас как раз тот навык, который тебе нужно улучшить в связи с должностью, которую ты сейчас занимаешь или которую собираешься получить. Возможно, также, что ты решил поменять что-то в своей жизни и решил попробовать себя в айти, и SQL нужен тебе как раз для этого.
В любом случае, в рамках этой книги я постараюсь максимально передать правильное понимание языка SQL и свой опыт. А начнём с тобой вообще с нуля. С самого начала. Полностью изучив книгу и проделав практические задачи, которые я подготовил для тебя, ты должен получить примерно три года мощной практики работы с базами данных при решении не только типичных, но самых изощрённых задач! Как если бы ты сам через все это прошёл, набил шишки и всему бы, в конечном итоге, научился. Понимаю, что звучит немного неправдоподобно, как книга может загрузить в тебя три года опыта? И я бы на твоём месте, вероятно, имел тень сомнения и это нормально! Но все, что я собрал здесь и в каком виде я собираюсь тебе это преподнести – это мощная программа знаний, навыки передачи которой я совершенствую уже примерно пятнадцать лет! Я научился объяснять SQL! Мои ученики, некоторые из которых только начали свой путь в айти и изначально не имели собственного опыта работы с базами данных, пройдя мой курс обучения, успешно проходили собеседования в айти компаниях по знаниям языка SQL и показывали лучшую компетентность чем даже те, кто в действительности непосредственно до собеседования уже имел опыт работы с базами данных и писал запросы. Все это так, но в действительности, дело было, конечно, в самих учениках! И я в конце говорю им об этом! И тебе говорю! Когда ты действительно готов освоить новый навык или его улучшить, то ты сделаешь это. И не важно через какой источник.
Когда человек готов – учитель найдётся!
(Поговорка)
Совсем коротко про язык SQL: что это такое, и для чего он нужен. Сейчас везде базы данных: сайты, мобильные приложения, различные CRM и ERP системы или другие системы учета, или автоматизации чего-либо, а также популярные программы вроде 1С тоже работают с базами данных. Базы данных во всех сферах нашей жизни. Вообще во всех: вся информация обрабатывается и хранится в базах данных. А SQL – это единственный (!) язык работы с базами данных! Теперь понял, что ты сейчас на пороге изучения единственного ключа, без которого невозможно войти в мир айти? Если ты уже в нем, то, вероятно, дошёл до двери, где без SQL дальше никак.
Вот я и объяснил очень кратко: SQL – это команды, с помощью которых из базы данных извлекается любая информация или кладётся туда. С помощью этих команд базы данных и создаются, и создаются объекты внутри баз данных, например, таблицы. Это было совсем общее объяснение!
Как будет проходить наш курс: вначале я более подробно расскажу, что такое SQL. Объясню, что такое база данных и что такое система управления базами данных (СУБД). Затем мы установим СУБД ORACLE на твой компьютер (или ноутбук), создадим в ней первую базу данных и загрузим в нее таблицы с тестовыми данными. Они будут необходимы для отработки практических навыков. Всего в книге 15 блоков с практическими задачами. Для некоторых задач я указал каким именно способом я предлагаю их решить, для некоторых – нет. Это значит, что жду от тебя, что ты сам выберешь оптимальный способ решения этой задачи. Звездочками отмечены задачи повышенной сложности. Их решение не обязательно. Но если ты смог решить такую задачу каким-нибудь способом, то это, разумеется, превосходно! Постарайся, пожалуйста, сначала решать практические задачи максимально самостоятельно. Так будет больше пользы! Если не будет получаться справиться с какой-либо задачей, то на следующей странице ты найдешь решение. Часто я буду не только показывать тебе ответ для самоконтроля или для понимания, как нужно было решить задачу, но буду и подробно объяснять путь решения. В любом случае, сначала максимально решай каждую задачу сам! Дай своему мозгу проложить дорогу к решению. Лучше еще раз перечитай урок или отложи решение на завтра, но по возможности, старайся решать сам. И так, урок за уроком, мы пройдем курс!
Об авторе

В каждой книге принято немного писать об авторе, чтобы было представление о том, кто её написал, об образовании и опыте автора. Поэтому ниже немного напишу о себе.
Меня зовут Илья Хохлов. Я эксперт в области информационных технологий и баз данных, предприниматель. Являюсь ведущим разработчиком программного обеспечения в собственной компании «Прайм Софт». Мы автоматизируем бизнес российских и зарубежных компаний.
Я являюсь автором курса «SQL. Базы данных. ORACLE», которому обучаю уже 15 лет.
Имею два высших образования, большой опыт работы в айти компаниях, как российских, так и зарубежных. Начал карьеру айти еще в 2005 году. Я работал программистом на последнем курсе в ВУЗе, в котором и учился, а также параллельно пробовал свои навыки преподавания айти технологий в небольшом проф. колледже, в качестве подработки. С 2006 по 2008 года работал штатным программистом в энергосбытовой сфере в Тверской области. С 2008 года по 2017 года – в двух айти-компаниях: Integrator IT и DiaSoft, и потом пять лет ведущим разработчиком в одном из лидирующих московских банков. С 2018 по 2022 года участвовал в проектах с компаниями Status Pro GmbH, Orga-Soft GmbH и MPS-Solutions в Германии.
Буду рад, если найдешь меня, также и в социальных сетях или подпишешься на мой канал в Телеграме, Youtube или Яндекс.Дзене.
Telegram, где мы решаем SQL задачи https://t.me/sql_oracle_databases
Youtube https://youtube.com/c/PrimeSoft
Яндекс.Дзен https://zen.yandex.ru/iliahohlov
1. Реляционные базы данных
Вначале, давай разберем что такое вообще база данных (сокращенно – БД). База данных – это, попросту говоря, файл, находящийся на компьютере, на сервере (на главном компьютере) или набор взаимосвязанных файлов. Пока, для простоты, будем понимать, что база данных – это некоторый файл.

Что внутри файла базы данных? В основном – таблицы с данными! Но не только. Объектами баз данных могут быть также и представления, пользователи, роли, хранимые программные объекты (триггеры, процедуры, функции), сиквенсы (счетчики) и еще много всего. Обо всем по порядку!
Итак, база данных – это файл, содержащий в себе таблицы с данными и другие объекты, необходимые для работы информационной системы (ИС). Баз данных (файлов) на одном компьютере (сервере) может быть несколько. Всеми файлами (базами данных) управляет система.
Именно с помощью системы производится чтение данных из баз данных (выбираются данные из одной или нескольких таблиц), производится изменение, добавление или удаление данных. Эта система называется Системой Управления Базами Данных (СУБД).
Никакой пользователь не может напрямую работать с файлом базы данных. Только с помощью системы он заходит в нужную базу данных, получает доступ к расположенным в ней таблицам, видит доступные ему объекты базы данных и выбирает сведения из какой–либо таблицы.
Ниже список популярных производителей Систем Управления Базами Данных:

В базах данных вся информация хранится в таблицах. Давай рассмотрим пример некоторой простой таблицы – таблицы Сотрудники:
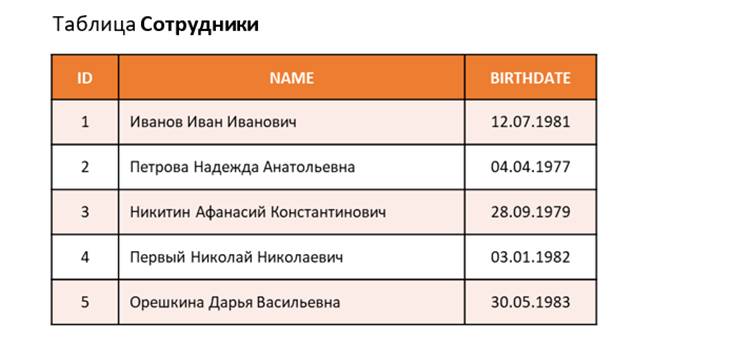
С первого взгляда все понятно, верно? В этой таблице три столбца – ID, NAME и BIRTHDATE.
В столбце ID хранится уникальный идентификатор каждого сотрудника. Он же может являться табельным номером. У каждого сотрудника этот номер свой.
В столбце NAME хранится Фамилия Имя Отчество (ФИО) сотрудников. В компании, которую мы уже начали рассматривать в рамках наших уроков, полные однофамильцы допустимы. И чтобы различать сотрудников в кадровом, бухгалтерском и других учетах, каждому сотруднику и присваивают уникальный идентификатор (табельный номер) – столбец ID.
В столбце BIRTHDATE – дата рождения каждого сотрудника.
Столбцы таблицы в терминологии баз данных называются полями. В приведенном выше примере у таблицы Сотрудники три поля.
Строки таблицы называются ее записями. Когда мы будем писать запросы, те строки данных, которые будет возвращать запрос SELECT, тоже будут называться записями. Ты, наверняка, слышал, как общаются между собой разработчики или аналитики, пишущие запросы: «сколько записей вернул твой запрос»? Это и имелось ввиду: сколько строк данных удалось получить запросом (командой выборки данных из базы данных). У таблиц и запросов строки данных имеют еще одно название – кортежи. Этот термин был введен одним из разработчиков языка SQL, но на практике термин кортеж не прижился.
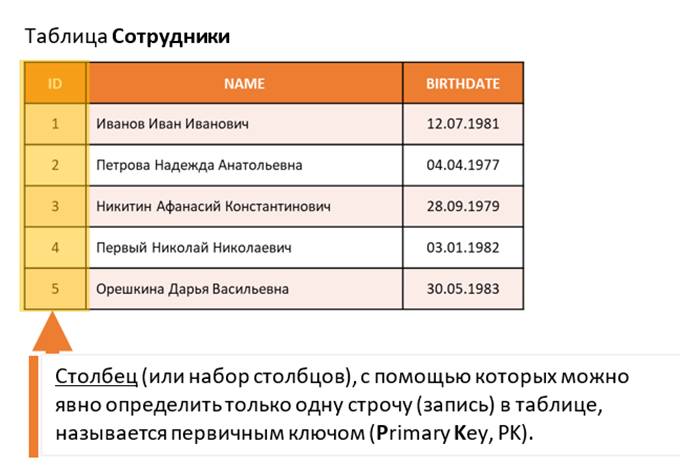
Столбец или набор столбцов, с помощью которых можно явно определить только одну строчку (запись) в таблице, называется первичным ключом (Primary Key, или сокращенно PK). В нашем примере, это специально созданный (для идентификации) столбец ID.
При проектировании системы эквайринга (приеме денежных оплат) через терминалы (которые мы можем встречать в супермаркетах или на улице) или через банк, в таблице приема платежей у каждой операции должен быть свой уникальный идентификатор (он печатается на чеке). Чтобы, в случае не зачисления средств, можно было обратиться в службу поддержки и назвать номер платежа. Хотя, современные информационные системы умеют и без того быстро находить проводившиеся оплаты с помощью номера телефона, в счет которого совершался платеж, или с помощью номера лицевого счета, который итак всегда известен плательщику.
В каждой таблице, где требуется иметь возможность сослаться на конкретную строчку таблицы (например, в таблице платежей – на конкретный платеж, в таблице клиентов – на конкретного клиента), должен быть первичный ключ.
Надеюсь, теперь стало ясно что такое первичный ключ и для чего он нужен. В большинстве случаев – это отдельный (один) столбец. Но также первичным ключом может быть два столбца (два поля)! И более. Тогда сочетание значений в этих столбцах должно быть всегда уникально в пределах целой таблицы. И сочетание значений одной строки не может повторяться для другой строки. Чтобы лучше понять для чего же такое может понадобиться, рассмотрим следующий пример.
Некоторая фирма, имеющая несколько филиалов, в конце каждого месяца собирает аналитику по деятельности компании: среднесписочная численность сотрудников в каждом филиале, общая сумма денежных поступлений и сумма денежных расходов по филиалу.
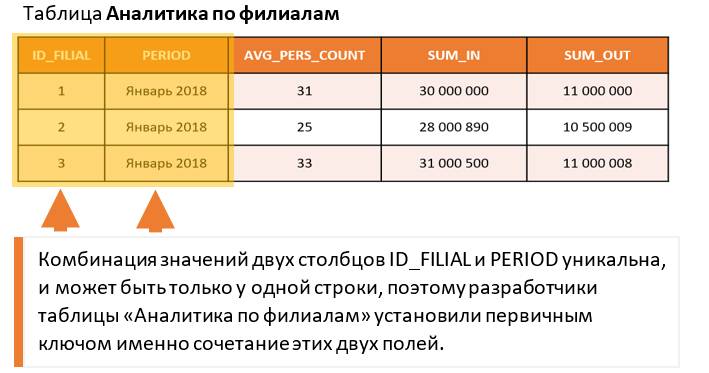
В графе ID_FILIAL указывается идентификатор филиала, по которому файл. сохраняются итоги, а в графе PERIOD указывается месяц и год, за который сохраняются итоги. Далее в столбцах AVG_PERS_COUNT, SUM_IN и SUM_OUT указывается среднее количество сотрудников, сумма поступлений и расходов, соответственно.
В нашем примере, за январь 2018 года, была внесена информация по трем филиалам. Проходит месяц и теперь вносится информация за февраль 2018.
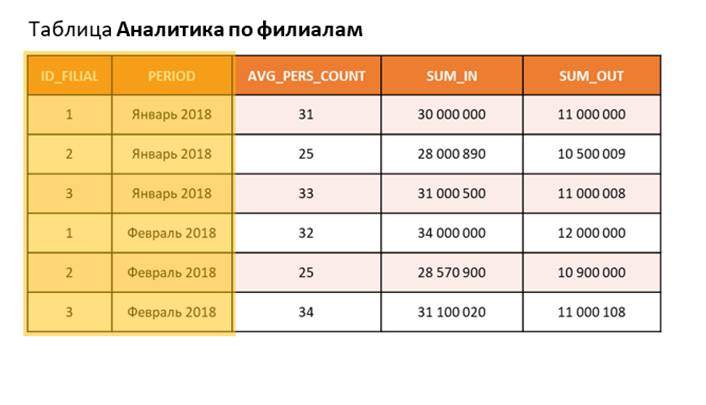
Если смотреть значение только в графе ID_FILIAL, то мы обнаружим, что оно повторяется. Конечно, ведь данные по одному филиалу вносились каждый месяц. Значение идентификатора филиала повторяется, но в сочетании со значением столбца PERIOD – оно уникально! Со значением ID_FILIAL = 1 и PERIOD = Январь 2018 есть только одна строчка. Также как и со значением ID_FILIAL = 3 и PERIOD = Февраль 2018.
Так как при проектировании таблицы, так и задумали, что по каждому филиалу за один месяц информация будет только в одной строке, программисты установили сочетание столбцов ID_FILIAL и PERIOD первичным ключом. Это очень просто можно настроить на любой таблице и в одной из следующих глав мы рассмотрим, как это делается. Первичный ключ, если его устанавливать на таблице, помимо логики, дает еще массу преимуществ: теперь ORACLE (или другая СУБД, если ты работаешь не в ORACLE) будет контролировать, чтобы никто не смог добавить строку в таблицу с повторяющейся комбинацией ID_FILIAL и PERIOD. Кроме того, первичный ключ – это еще и самый быстрый способ получения из таблицы информации: если кто–то захочет получить сведения из таблицы по ID_FILIAL = 1 и за Апрель 2019 (например), то вне зависимости столько бы много строчек в таблице не было, СУБД сразу даст результат. Сразу – это значит за мгновение, даже если в таблице будут миллионы строк. Об оптимизации запросов, ключах и индексах у нас будет отдельная тема и мы подробно рассмотрим, как писать запросы так, чтобы они всегда быстро работали!
Теперь рассмотрим еще один термин, который нам нужно понять – внешний ключ (Foreign Key, или сокращенно FK).
В компании, базу данных которой мы рассматриваем, помимо таблицы «Сотрудники», есть еще таблица «Автомобили сотрудников».
В таблице «Автомобили сотрудников» есть 4 столбца: столбец ID – сквозной идентификатор каждого учетного автомобиля, столбец ID_PERS – идентификатор сотрудника, владельца автомобиля, столбец NOMER – государственный регистрационный номер автомобиля и столбец MARKA – марка автомобиля.
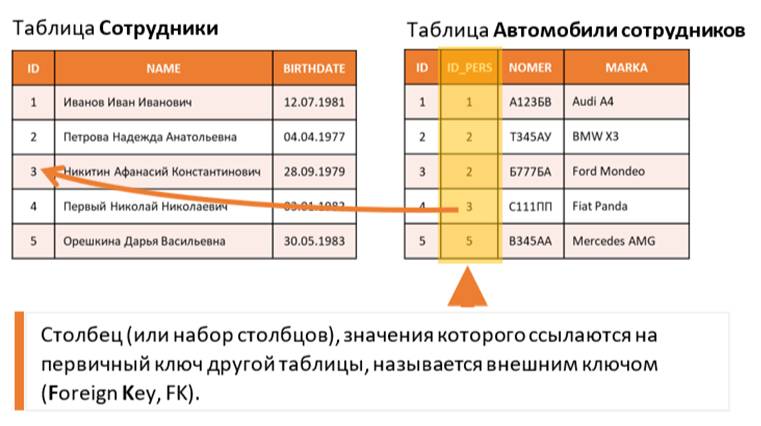
В таблице «Автомобили сотрудников» столбец ID будет являться собственным первичным ключом. А в столбце ID_PERS указаны только такие значения, которые есть в таблице «Сотрудники» в графе ID. Столбец (или набор столбцов), значения которого ссылаются на первичный ключ другой таблицы, называется внешним ключом (или foreign key, сокращенно FK). Чтобы было еще понятнее, Foreign key лучше перевести не как «внешний ключ», а как «чужой ключ», то есть ключ не своей таблицы, а другой. Стало понятнее?
Из рисунка выше видно, что Audi A4 принадлежит сотруднику с идентификатором 1, то есть Иванову Ивану. Два автомобиля BMW X3 и Ford Mondeo у сотрудника Петрова Надежда Анатольевна. Fiat Panda принадлежит Афанасию Константиновичу и т.д. Сотрудник Первый Николай Николаевич не имеет ни одного автомобиля, так как в таблице «Автомобили сотрудников» нет ни одной записи (ни одной строки), где бы в столбце ID_PERS было значение 4.
Разработчики создали в таблице «Автомобили сотрудников» столбец ID_PERS и сознательно настроили так, чтобы он был внешним ключом, то есть значения в нем могли бы быть только такими, которые есть в таблице «Сотрудники» в столбце ID. Теперь СУБД будет сама контролировать, запись с каким значением для графы ID_PERS добавляется в таблицу «Автомобили сотрудников». Чтобы нельзя было добавить строчку в таблицу, указав идентификатор владельца такого, которого нет. Это и есть главное назначение внешнего ключа.
В таблице «Автомобили сотрудников» значение графы ID_PERS ссылается на идентификатор конкретного сотрудника. По этому идентификатору всегда можно получить все сведения о сотруднике: Фамилию Имя Отчество, в каком отделе он работает, на какой должности и т.д. В базе данных еще есть много таблиц, и почти каждая из них имеет столбец, который ссылается на другую таблицу. Например, в таблице Сотрудников, помимо прочих, может быть еще и столбец, указывающий на идентификатор филиала, в котором работает сотрудник. По идентификатору филиала в таблице Филиалов можно найти конкретную строчку с названием филиала и другой сопутствующей информацией: адресом, телефоном и т.д.
В примере, который мы разобрали выше с Сотрудниками и Автомобилями сотрудников, у каждого сотрудника может быть несколько автомобилей. Может быть! А может и не одного. Но если база данных построена так, что согласно связи, одной строчке в одной таблице потенциально может относиться несколько строчек другой таблицы, то такая связь называется один–ко–многим. Еще бывают связи один–к–одному и многие–ко–многим. Немного подробнее поговорим об этом попозже.
Итак, раз в базе данных почти все таблицы как–то относятся к другим таблицам – «Автомобили сотрудников» к «Сотрудникам», «Филиалы» к «Сотрудникам» и т.д. – такую базу данных называют реляционной (от англ. relations – отношения).
Сейчас практически все базы данных имеют реляционную модель. То есть модель данных, построенную на отношениях.
2. Группы команд языка SQL
Вопрос на собеседовании „Какие команды DML Вы знаете?“ не поставит нас в тупик, а удивит: насколько простое в этой компании собеседование!
Все команды языка SQL разделяются на 4 группы:
DML (Data Manipulation Language) – язык манипуляции данными. Набор из четырех основных команд, для работы непосредственно с информацией, хранящейся в таблицах. С помощью этих команд можно: выбирать из таблицы (чтение), вставлять новые строчки с информацией в таблицу (например, добавлять новые товары в таблицу товаров, добавлять нового сотрудника в таблицу сотрудников), редактировать что–то в строчках данных и удалять строки из таблицы. Помимо этих четырех команд работы с данными, есть еще одна команда – MERGE. Это операция также добавляет строчки в таблицу, но, если записи с такими же ключевыми значениями уже в целевой таблице есть, то MERGE их обновит;
DDL (Data Definition Language) – язык определения данных. Перед тем как строчки с данными добавлять в таблицу, надо сначала создать саму таблицу в базе данных. Вот для этого и нужны команды DDL: создание таблиц и других объектов базы данных, их редактирование и удаление;
TCL (Transaction Control Language) – язык управления транзакциями;
DCL (Data Control Language) – язык контроля доступа к данным.
К группе команд DML относятся команды: SELECT – выбрать/прочитать информацию из таблицы/таблиц, INSERT – вставить новые строчки с данными, UPDATE – изменить, хранящиеся в таблице данные, команда DELETE – удалить строчки с данными, и команда MERGE – вставить/обновить данные в таблице.
К группе команд DDL относятся команды: CREATE – создание новых объектов в базе данных; ALTER – изменение уже существующих объектов, например, расширение таблицы, то есть добавление в нее столбца, для хранения новых сведений; DROP – удаление объекта из базы данных, например, таблицы целиком. Существует еще несколько команд, которые мы рассмотрим позже.
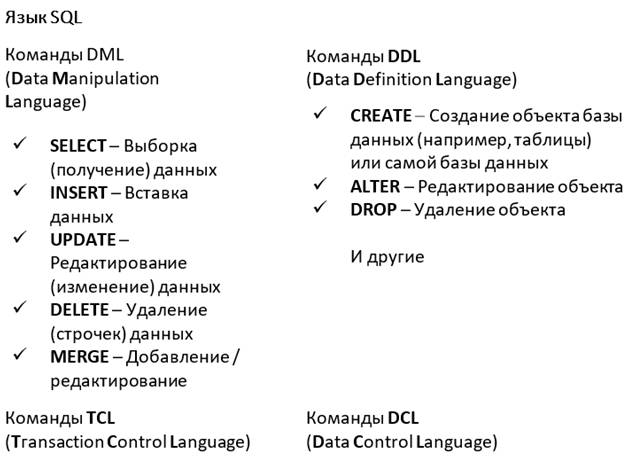
В группе команд TCL управления транзакциями всего две команды: COMMIT и ROLLBACK. Первая подтверждает проведенные изменения, а вторая откатывает. Понятие транзакций и более подробную работу с ними мы рассмотрим в отдельной главе.
К командам контроля доступа к данным DCL относятся команды: GRANT – предоставление привилегий на определенные действия к определенным объектам для определенных пользователей, ролей или для всех; REVOKE – снятие привилегий на определенные действия к определенным объектам с определенный пользователей, ролей или всех. Например, с помощью этих команд, можно дать некоторому пользователю базы данных права на вставку данных в таблицу, которую мы создали. Или, с помощью них, мы можем предоставить права, например, на чтение информации с нашей таблицы, к примеру, сразу всем. То есть к этой группе команд относятся команды, с помощью которых можно давать права на объект базы данных или наоборот, запрещать кому–то делать что–то с таблицей или другим объектом базы данных.
Контрольные вопросы №1
В этой главе мы достаточно изучили теории, хорошо разобрались с группами команд языка SQL и теперь необходимо закрепить полученные знания, чтобы четко понимать к какой группе команд относится та или иная команда. Для этого предлагаю ответить на следующие практические вопросы:
1. Какие команды DML ты запомнил?
2. Нам необходимо добавить новое лекарство в нашу базу данных в таблицу–справочник лекарственных средств. Какую команду SQL мы должны использовать? (Ответ должен быть, например, команда UPDATE или DELETE, или другая).
3. В таблице заказов необходимо отредактировать количество проданного товара для одной из покупок, сделанных минуту назад. Клиент решил купить больше товара! Необходимо изменить значение в некоторой строке. Какая команда SQL будет выполнена?
4. Для выполнения изменения законодательства нашей компании обязательно нужно будет в базе данных хранить дополнительные сведения о товарах. Для этого потребуется добавить два новых столбца в таблицу товаров. Какая команда SQL будет выполнена?
5. Необходимо удалить ошибочно заведенного клиента, то есть удалить строку из таблицы клиентов. Какая это команда SQL?
6. Необходимо для одного из клиентов в столбце «Дата закрытия» удалить дату, так как руководство приняло решение возобновить работу с клиентом. Какая команда SQL?
7. Для расширения бизнеса потребуется одна новая таблица для хранения операций по скидочным картам. Какая команда SQL должна быть выполнена чтобы создать новую таблицу в базе данных?
8. Нужно получить остаток по счету некоторого клиента. Какая команда SQL будет выполнена?
9. Необходимо вывести список последних десяти операций по счету клиента. Какая команда SQL?
10. В базе данных создали новую таблицу. Необходимо предоставить возможность выбирать данные из этой таблицы всем пользователям. Какую команду SQL необходимо выполнить, чтобы предоставить права на выполнение команды SELECT из этой новой таблицы?
Ответы на контрольные вопросы на следующей странице.