



Джордан Голдмейер
Разберись в Data Science. Как освоить науку о данных и научиться думать как эксперт
Вы можете понять общую картину
Для лучшего понимания данных и работы с ними вам необходимо быть готовым к изучению сложных концепций. И даже если вы уже знакомы с ними, мы научим вас тому, как донести их до вашей аудитории.
Вам также предстоит принять такой редко обсуждаемый факт, что во многих компаниях работа с данными оказывается неэффективной. Вы разовьете интуицию, понимание и здоровый скептицизм в отношении чисел и терминов, с которыми сталкиваетесь. Эта задача может показаться сложной, но эта книга поможет вам ее решить. И для этого вам не понадобятся ни навыки программирования, ни докторская степень.
С помощью четких объяснений, мысленных упражнений и аналогий вы сможете выстроить ментальную модель для понимания науки о данных, статистики и машинного обучения.
В следующем примере мы сделаем именно это.
Классификация ресторанов
Представьте, что вы идете по улице и видите пустую витрину с вывеской «Новый ресторан: скоро открытие». Вы устали питаться в сетевых ресторанах и постоянно ищете новые местные заведения, поэтому задаетесь вопросом: «Появится ли здесь новый независимый ресторан?»
Давайте поставим этот вопрос более формально: как вы думаете, будет ли новый ресторан сетевым или независимым?
Угадайте. (Серьезно, подумайте об этом, прежде чем двигаться дальше.)
В реальной жизни вы сделали бы довольно хорошее предположение за доли секунды. Находясь в модном районе с множеством местных пабов и закусочных, вы бы предположили, что ресторан будет независимым. А если бы речь шла о межштатной автомагистрали с расположенным рядом торговым центром, вы бы предположили, что ресторан будет сетевым.
Но когда мы задали вопрос, вы заколебались. Вы подумали, что мы предоставили недостаточно информации. И вы были правы. Мы не предоставили вам никаких данных для принятия решения.
Мораль: для принятия обоснованных решений требуются данные.
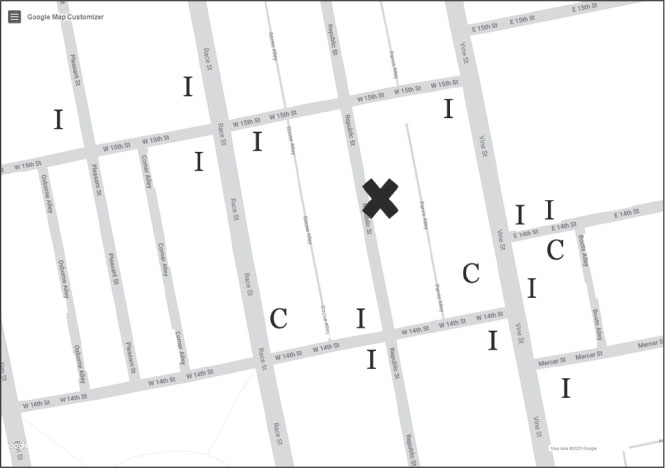
Теперь посмотрите на первое изображение на следующей странице. Новый ресторан отмечен крестиком (X), буквой C обозначены сетевые рестораны (chain), а буквой I – независимые (independent) местные закусочные. Какое предположение вы сделали бы на этот раз?
Большинство людей предполагает, что ресторан будет независимым (I), потому что такова большая часть близлежащих ресторанов. Однако обратите внимание на то, что независимыми являются далеко не все из них. Если бы мы попросили вас оценить уровень достоверности[5] вашего прогноза в диапазоне от 0 до 100, то она, скорее всего, была бы высокой, но не равной 100, поскольку по соседству вполне может появиться еще один сетевой ресторан.
Мораль заключается в следующем: предсказания никогда не могут быть на 100 % достоверными.
Район Овер-Райн, Цинциннати, штат Огайо
Теперь взгляните на следующее изображение. В этом районе есть большой торговый центр, и большинство ресторанов здесь – сетевые. Когда людям предлагается предсказать, каким будет новый ресторан в этом районе – сетевым или независимым, большинство выбирает вариант (С). Но нам нравится, когда кто-то выбирает вариант (I), потому что это подчеркивает несколько важных моментов.
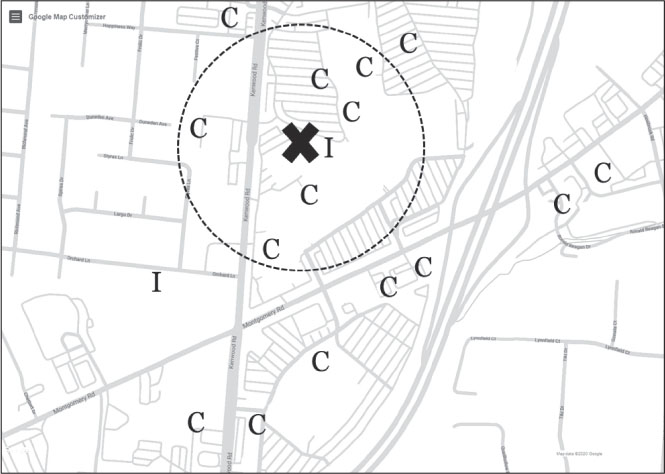
Кенвуд Таун Центр, Цинциннати, штат Огайо
В ходе этого мысленного эксперимента каждый участник создает в своей голове слегка отличающийся алгоритм. Разумеется, все смотрят на маркеры, окружающие интересующую нас точку X, чтобы понять особенности района, но в какой-то момент необходимо решить, что ресторан находится слишком далеко, чтобы повлиять на прогноз. Иногда человек видит единственный ближайший ресторан, в данном случае – независимый (I), и основывает на этом свой прогноз: «Ближайшим соседом ресторана X является независимый ресторан (I), поэтому мой прогноз – (I)».
Однако большинство людей учитывают несколько соседних ресторанов. На втором изображении вокруг нового ресторана нарисована окружность, включающая семь его ближайших соседей. Вероятно, вы выбрали другое число, но мы выбрали 7. Шесть из семи ресторанов сетевые (С), поэтому мы прогнозируем, что новый ресторан тоже будет сетевым.
Что дальше?
Если вы поняли пример с рестораном, значит, вы уже на пути становления главным по данным. Давайте пройдемся по тому, что вы узнали.
– Вы выполнили классификацию, предсказав метку для нового ресторана (сетевой или независимый), обучив алгоритм на наборе данных (содержащем местоположения ресторанов и соответствующие метки).
– В этом состоит суть машинного обучения! Просто для разработки алгоритма вы использовали не компьютер, а собственную голову.
– Данный тип машинного обучения называется контролируемым обучением, потому что вы знали, что существующие рестораны были сетевыми (C) или независимыми (I). Эти метки направляли (то есть контролировали) ход ваших мыслей при размышлении о том, как расположение ресторана связано с его типом (сетевой или независимый).
– Если еще конкретнее, то вы использовали алгоритм контролируемой классификации под названием метод k-ближайших соседей[6]. Если K = 1, посмотрите на ближайший ресторан и получите свой прогноз. Если K = 7, посмотрите на 7 ближайших ресторанов и сделайте предсказание на основе их большинства. Это интуитивно понятный и мощный алгоритм. И в нем нет никакого волшебства.
– Вы также узнали о том, что для принятия обоснованных решений вам нужны данные. Однако помимо них вам необходимо кое-что еще. В конце концов, в этой книге много внимания уделяется критическому мышлению. Мы хотим показать не только то, как работают те или иные вещи, но и то, почему иногда они не срабатывают. Если бы мы попросили вас спрогнозировать, опираясь на приведенные в этом разделе изображения, будет ли новый ресторан ориентирован на детей, вы бы не смогли ответить. Для принятия обоснованных решений подходят далеко не любые данные. Для этого нужно достаточное количество точных и релевантных данных.
– Помните технические термины, которые мы упоминали ранее, говоря об «…анализе бинарной переменной отклика методом контролируемого обучения?..» Поздравляем, вы только что выполнили такой анализ. Переменная отклика – это просто еще одно название метки, и она является бинарной, потому что в нашем примере их было две – (C) и (I).
В этом разделе вы многое узнали, причем даже не осознавая этого.
Для кого написана эта книга?
Как говорится в начале этой книги, данные затрагивают жизни многих сотрудников современных корпораций. Мы придумали нескольких аватаров, представляющих людей, которые могут выиграть от становления главными по данным.
Мишель – специалист по маркетингу, которая работает бок о бок с аналитиком данных. Она разрабатывает маркетинговые инициативы, а ее коллега собирает данные и измеряет влияние, оказываемое этими инициативами. Мишель считает, что их работа должна быть более инновационной, но не может донести до коллеги свои потребности в данных и их анализе. Общение между ними затруднено. Она поискала в Google некоторые специальные термины (машинное обучение и прогностическая аналитика), но в большинстве найденных ею статей использовались чрезмерно технические определения, неразборчивый компьютерный код, реклама аналитического программного обеспечения или консультационных услуг. В результате поисков она почувствовала еще большую тревогу и растерянность, чем раньше.
Даг имеет докторскую степень в области наук о жизни и работает в отделе исследований и разработок крупной корпорации. Скептик по натуре, он задается вопросом о том, не является ли шумиха вокруг данных очередным хайпом. Однако Даг старается не демонстрировать свой скептицизм на рабочем месте (особенно в присутствии нового директора, который носит футболку с надписью «Данные – это новая нефть»), поскольку не хочет, чтобы его считали дата-луддитом. В то же время он чувствует себя не у дел и решает узнать, из-за чего весь этот шум.
Реджина – топ-менеджер компании и хорошо осведомлена о последних тенденциях в области науки о данных. Она курирует новое подразделение своей компании, занимающееся наукой о данных, и регулярно взаимодействует со старшими дата-сайентистами. Реджина доверяет своим специалистам, но ей хотелось бы иметь более глубокое понимание сути их деятельности, потому что ей часто приходится представлять и отстаивать результаты работы своей команды перед советом директоров компании. Реджине также поручена проверка нового технологического программного обеспечения. Она подозревает, что некоторые заявления поставщиков относительно «искусственного интеллекта» слишком хороши, чтобы быть правдой, и хочет получить дополнительные технические знания, чтобы отделить маркетинговые заявления от реальности.
Нельсон руководит работой трех дата-сайентистов в рамках своей новой должности. Будучи специалистом по компьютерным наукам, он знает, как писать программы и работать с данными, но плохо разбирается в статистике (поскольку прошел в колледже только один курс) и машинном обучении. Учитывая наличие технического образования, он хочет и может разобраться в деталях, но просто не находит на это времени. Руководство также побуждает его команду «больше заниматься машинным обучением», но на данный момент это кажется ей волшебным черным ящиком. Нельсон приступает к поиску материала, который поможет ему завоевать доверие команды и понять, какие проблемы можно решить с помощью машинного обучения, а какие – нет.
Мы надеемся, вы узнали себя в одном или нескольких из этих персонажей. Общим для них и, вероятно, для вас является желание стать лучшим «потребителем» данных и аналитики, с которыми вы сталкиваетесь.
Мы также создали аватар, представляющий людей, которым следует прочитать эту книгу, но которые, скорее всего, не станут этого делать (потому что в каждой истории должен быть злодей).
Джордж – менеджер среднего звена, читает последние деловые статьи об искусственном интеллекте и рассылает понравившиеся вверх и вниз по своей цепочке управления, как доказательство своей технической подкованности. Однако в зале заседаний он предпочитает «прислушиваться к своей интуиции». Джорджу нравится, когда его дата-сайентисты представляют ему цифры с помощью одного или двух слайдов. Когда результаты анализа согласуются с тем, что подсказала его интуиция, прежде чем он заказал исследование, он передает их вверх по цепочке и хвастается перед коллегами «внедрением искусственного интеллекта». Если результаты анализа не согласуются с его интуицией, он задает своим дата-сайентистам ряд туманных вопросов и отправляет их на поиски «доказательств», необходимых для продвижения его проекта.
Не будьте такими, как Джордж. Если вы знаете «Джорджа», порекомендуйте ему эту книгу и скажите, что он похож на «Реджину».
Зачем мы написали эту книгу
Мы считаем, что многие люди, похожие на описанные выше аватары, хотят больше узнать о данных, но не знают, с чего начать. Существует широкий спектр книг, посвященных науке о данных и статистике. На одном конце этого спектра находятся нетехнические книги, превозносящие достоинства и перспективы работы с данными. Какие-то из них лучше, чем другие. Самые лучшие из них напоминают современные бизнес-книги. Однако многие написаны журналистами, которые стремятся драматизировать начало эпохи данных.
В этих книгах описывается то, как те или иные бизнес-проблемы были решены путем их рассмотрения через призму данных. И в них даже встречаются такие понятия, как искусственный интеллект, машинное обучение и тому подобное. Не поймите нас неправильно, эти книги способствуют созданию осведомленности. Однако они не позволяют глубоко вникнуть в соответствующие темы, вместо этого сосредотачиваясь на высокоуровневом описании конкретной проблемы и ее решения.
На другом конце спектра находятся узкотехнические книги – 500-страничные тома в твердом переплете, пугающие как своим объемом, так и содержанием.
На противоположных сторонах этого спектра сосредоточены горы книг, что усугубляет разрыв в общении, – большинство людей читают либо только бизнес-книги, либо только технические книги, а не то и другое.
К счастью, между этими двумя крайностями есть много отличных книг. Нашими любимыми являются следующие:
– «Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking», Фостер Провост и Том Фосетт (Издательство: O’Reilly Media, 2013 год);
– «Много цифр. Анализ больших данных при помощи Excel», Джон Форман (Издательство: Альпина Паблишер, 2016 год).
Мы хотим добавить к этому списку еще одну книгу, которую вы сможете прочитать, не имея под рукой ни компьютера, ни блокнота. Если вам понравится наша книга, мы настоятельно рекомендуем прочитать одну или обе из указанных выше книг, чтобы углубить свое понимание. Вы не пожалеете.
Кроме того, мы очень любим эту тему. Если с помощью своей книги нам удастся побудить вас узнать больше о данных и аналитике, мы будем считать, что достигли успеха.
Что вы узнаете
Эта книга поможет вам построить ментальную модель для понимания науки о данных, статистики и машинного обучения. Ментальная модель – это «упрощенное представление наиболее важных элементов некоторой предметной области, достаточное для решения проблем»[7]. Думайте о ней как о хранилище в вашем мозгу, в которое вы можете поместить информацию.
Некоторые книги и статьи начинаются со списка определений: «Машинное обучение – это…», «Глубокое обучение – это…» и так далее. Чтение технических определений в отсутствие ментальной модели, в которую эту информацию можно было бы вписать, похоже на скупку одежды, которую вам негде хранить. Рано или поздно вся она окажется на свалке.
Однако с помощью ментальной модели вы научитесь понимать, думать и говорить на языке данных. Вы станете главным по данным.
В частности, прочитав эту книгу, вы сможете:
– Думать статистически и понимать, какую роль вариации играют в вашей жизни и процессе принятия решений.
– Разбираться в данных – разумно говорить и задавать правильные вопросы о статистике и результатах, с которыми сталкиваетесь на рабочем месте.
– Осознавать истинное положение вещей в сфере машинного обучения, текстовой аналитики, глубокого обучения и искусственного интеллекта.
– Избегать распространенных ловушек при работе с данными и их интерпретации.
Как организована эта книга
Главный по данным – это тот, кто способен критически осмыслять данные вне зависимости от своей официальной роли. Это может быть аналитик, сидящий за компьютером, или топ-менеджер, наблюдающий за работой других. В этой книге вам как главному по данным предстоит сыграть разные роли.
Хотя «сюжет» книги выстроен в хронологическом порядке, каждая глава – это отдельный урок, который может быть изучен сам по себе. Однако мы рекомендуем прочитать книгу от начала до конца, чтобы выстроить свою ментальную модель и перейти от основ к более глубокому пониманию.
Книга состоит из четырех частей.
Часть I. Думайте как главный по данным. В этой части вы научитесь мыслить критически и задавать правильные вопросы о проектах по работе с данными, реализуемых в вашей организации; вы узнаете, что такое данные, а также освоите специальную терминологию и научитесь смотреть на мир через призму статистики.
Часть II. Говорите как главный по данным. Главные по данным – активные участники важных обсуждений. Эта часть научит вас «спорить» с данными и задавать правильные вопросы для понимания статистики, с которой вы сталкиваетесь. В ней вы познакомитесь с основными понятиями статистики и теории вероятностей, необходимыми для понимания и оспаривания предоставляемых вам результатов.
Часть III. Освойте набор инструментов дата-сайентиста. Главные по данным должны понимать фундаментальные концепции, лежащие в основе работы статистических моделей и моделей машинного обучения. В этой части вы получите интуитивное представление о неконтролируемом обучении, регрессии, классификации, текстовой аналитике и глубоком обучении.
Часть IV. Гарантируйте успех. Главные по данным знают о распространенных ошибках, допускаемых при работе с данными. В этой части вы узнаете о технических ловушках, которые приводят к провалу проектов, а также о людях и типах личностей, участвующих в соответствующих проектах. Наконец, мы дадим вам несколько рекомендаций о том, как добиться успеха в качестве главного по данным.
Прежде чем мы начнем
Мы не раз отмечали, что объем данных растет гораздо быстрее, чем наша способность формулировать порождаемые этим проблемы и возможности. Мы показали, что прошлое как всего общества, так и авторов этой книги наполнено неудачами, связанными с данными. И только поняв это прошлое, мы можем понять будущее. Для начала мы познакомили вас с несколькими важными концепциями в примере с классификацией ресторанов.
Для более глубокого понимания данных вам необходимо прорваться сквозь шум, критически осмыслить связанные с данными проблемы и научиться эффективно взаимодействовать с соответствующими специалистами. Мы уверены, что, вооружившись этими знаниями, вы добьетесь успеха.
Готовы? Ваш путь становления главным по данным начинается на следующей странице.
Часть I
Думайте как главный по данным
Многие компании спешат попробовать «что-нибудь новенькое», не останавливаясь для того, чтобы задать правильные бизнес-вопросы, изучить базовую терминологию или научиться смотреть на мир сквозь призму статистики.
У главных по данным не будет такой проблемы. Часть I, «Думайте как главный по данным», подготовит вас к предстоящему пути и поможет сформировать правильный настрой для размышлений о данных и их понимания. Эта часть состоит из следующих глав:
Глава 1. В чем суть проблемы?
Глава 2. Что такое данные?
Глава 3. Готовьтесь мыслить статистически.
Глава 1
В чем суть проблемы?
«Хорошо сформулированная проблема – это наполовину решенная проблема»
– Чарльз Кеттеринг, изобретатель и инженер
Первый шаг на пути становления главным по данным заключается в том, чтобы помочь своей организации выбрать для решения те проблемы, которые действительно важны.
Это может показаться очевидным, однако многие из вас наверняка были свидетелями того, как компании говорили, насколько замечательные у них данные, а затем преувеличивали их влияние, неправильно интерпретировали результаты или инвестировали в технологии работы с данными, которые не создавали ценности для бизнеса. Часто кажется, что компании запускают проекты по работе с данными просто потому, что им нравится, как это звучит, не вполне понимая важность самих проектов.
Такой подход оборачивается напрасной тратой времени и денег и может породить негативное отношение к будущим проектам. Действительно, стремясь найти скрытую ценность в имеющихся данных, многие компании часто терпят неудачу на самом первом этапе процесса, связанном с определением стоящей перед бизнесом проблемы[8]. Итак, в этой главе нам предстоит вернуться к началу.
В следующих разделах мы рассмотрим полезные вопросы, которые следует задать главному по данным, чтобы убедиться в важности его работы. Затем мы рассмотрим примеры того, как игнорирование этих вопросов оборачивается провалом проекта. Наконец, мы обсудим некоторые скрытые издержки, связанные с недостатком четкости в исходном определении проблемы.
Вопросы, которые должен задать главный по данным
Мы по опыту знаем, что вернуться к основным принципам и задать фундаментальные вопросы гораздо сложнее, чем кажется на первый взгляд. Каждая компания имеет уникальную культуру, и командная динамика не всегда позволяет открыто задавать вопросы – особенно те, которые могут заставить других почувствовать свою несостоятельность. Многие главные по данным не могут даже начать задавать важные вопросы, способствующие реализации проектов. Вот почему иметь культуру, которая поощряет постановку таких вопросов, так же важно, как и сами вопросы.
Не существует универсальной формулы, подходящей для всех компаний и главных по данным. Если вы руководитель, мы призываем вас создать открытую среду, позволяющую задавать такие вопросы. (Начните с привлечения к обсуждению технических экспертов.) И задавайте вопросы сами. Это позволит вам продемонстрировать такую ключевую черту лидерства, как смирение, а также побудит других включиться в процесс. Если вы не руководитель, мы все равно рекомендуем вам задавать эти вопросы, не боясь нарушить статус-кво. Наш совет – просто делать все от себя зависящее. Исходя из опыта, мы считаем, что задавание правильных вопросов всегда позволяет получить гораздо больше, чем отказ от этого.
Мы хотим научить вас вовремя замечать предупреждающие знаки и сообщать о возникающих проблемах. Вот пять вопросов, которые вам следует задать, прежде чем приступать к работе с данными:
1. Почему эта проблема важна?
2. Кого затрагивает эта проблема?
3. Что, если у нас нет нужных данных?
4. Когда проект будет завершен?
5. Что, если нам не понравятся результаты?
Давайте подробно разберем каждый из них.