



Джейд Картер
Обработка больших данных
Связь между DataNodes
Описание: DataNodes обмениваются информацией о состоянии блоков, например, если необходимо создать новые реплики.
– MapReduce
MapReduce – это мощная модель программирования и фреймворк, разработанный Google для обработки и генерации больших наборов данных в распределенных вычислительных средах. В основе MapReduce лежит простая, но эффективная идея: разбиение задачи на более мелкие, независимые подзадачи, которые могут выполняться параллельно на различных узлах кластера, а затем объединение полученных результатов для получения окончательного ответа. Этот подход позволяет эффективно использовать ресурсы распределённых систем и обрабатывать огромные объёмы данных за относительно короткое время.
MapReduce состоит из двух ключевых этапов: Map и Reduce.
1. Этап Map:
– Функция Map обрабатывает входные данные и преобразует их в набор пар ключ-значение (key-value pairs). Этот процесс можно представить как фильтрацию и сортировку данных. Каждый блок данных из исходного набора данных передаётся в функцию Map, которая производит одну или несколько записей (пар ключ-значение) для дальнейшей обработки.
– Пример: Представьте, что вам нужно посчитать количество каждого слова в большом наборе текстовых документов. Функция Map будет считывать текст, разбивать его на слова и генерировать пары ключ-значение, где ключ – это слово, а значение – единица (1), обозначающая одно появление слова.
2. Этап Shuffle and Sort:
– После завершения этапа Map начинается процесс сортировки и передачи данных (shuffle and sort). На этом этапе все пары ключ-значение, созданные в ходе этапа Map, сортируются и группируются по ключу. Этот процесс важен для подготовки данных к этапу Reduce, так как все записи с одинаковыми ключами будут переданы одной функции Reduce.
– Этот этап может быть довольно ресурсоёмким, так как требует значительных вычислительных мощностей и сетевых ресурсов для передачи данных между узлами.
3. Этап Reduce:
– Функция Reduce получает сгруппированные по ключу данные от этапа Shuffle and Sort и производит агрегацию или другую обработку, создавая итоговый результат для каждой группы ключей. Результат каждого вызова функции Reduce записывается в выходной файл.
– Пример: Возвращаясь к примеру с подсчётом слов, на этапе Reduce функция будет суммировать все значения (единицы), связанные с каждым словом (ключом), и выдавать итоговое количество появлений этого слова в исходном наборе документов.
Одним из основных преимуществ MapReduce является его способность обрабатывать данные в распределённых системах, что позволяет масштабировать вычислительные ресурсы в зависимости от объёмов данных. Это достигается за счёт параллельного выполнения подзадач на множестве узлов кластера, что значительно ускоряет процесс обработки по сравнению с традиционными подходами, которые выполняются последовательно на одном сервере.
Кроме того, MapReduce обеспечивает высокую отказоустойчивость. Если один из узлов кластера выходит из строя в процессе выполнения задания, фреймворк автоматически переназначает задачу на другой доступный узел. Это позволяет минимизировать простои и обеспечивает надежную работу даже в условиях частых аппаратных сбоев.
MapReduce также отличается простотой программирования. Несмотря на то, что задачи, решаемые с его помощью, могут быть очень сложными, модель программирования MapReduce предлагает простой и интуитивно понятный интерфейс для разработчиков. Им необходимо лишь определить функции Map и Reduce, а вся остальная сложная работа по распределению задач, управлению данными и обработке отказов выполняется фреймворком.
Несмотря на свои многочисленные преимущества, MapReduce имеет и некоторые ограничения. Одним из них является его подход, ориентированный на пакетную обработку данных, что делает его менее подходящим для задач, требующих обработки данных в реальном времени или с низкой задержкой. Хотя этот недостаток можно частично компенсировать использованием дополнительных инструментов, таких как Apache Spark для более быстрой обработки данных, MapReduce остаётся менее гибким для задач, требующих мгновенных откликов.
Ещё одно ограничение связано с тем, что MapReduce требует значительных ресурсов для выполнения этапов Shuffle and Sort, особенно при работе с большими объемами данных, что может приводить к узким местам в производительности.
MapReduce оказал огромное влияние на развитие технологий больших данных, став основой для многих современных фреймворков и систем, включая Apache Hadoop, который сделал MapReduce доступным и популярным инструментом для обработки данных в широком спектре отраслей. Несмотря на появление новых технологий и подходов, MapReduce по-прежнему остаётся важной и востребованной моделью программирования для распределённой обработки данных, особенно для задач, связанных с анализом больших объемов информации.
– YARN (Yet Another Resource Negotiator)
YARN (Yet Another Resource Negotiator) – это система управления ресурсами, которая стала ключевым компонентом второй версии Hadoop (Hadoop 2.x). YARN была разработана для преодоления ограничений первой версии Hadoop, в которой MapReduce одновременно выполнял роли как фреймворка для обработки данных, так и системы управления ресурсами. Введение YARN позволило отделить эти функции, что значительно повысило гибкость и эффективность использования ресурсов в кластерах Hadoop.
YARN состоит из нескольких ключевых компонентов, которые совместно обеспечивают управление ресурсами и координацию выполнения приложений в распределенной среде:
1. ResourceManager (Менеджер ресурсов):
Расположение: Центральный компонент системы YARN, который управляет всеми ресурсами кластера.
Функции: ResourceManager отвечает за распределение ресурсов между различными приложениями. Он получает запросы от приложений на выделение ресурсов, принимает решения о размещении задач на узлах и контролирует состояние кластера. ResourceManager включает в себя два основных модуля: Scheduler и ApplicationManager.
Scheduler: Этот модуль отвечает за планирование ресурсов, распределяя вычислительные мощности (CPU, память) между приложениями в соответствии с их приоритетами и требованиями. Scheduler действует на основе политики выделения ресурсов, не выполняя самих задач, что позволяет избежать конфликтов и перегрузки кластера.
ApplicationManager: Управляет жизненным циклом приложений, начиная от их инициализации до завершения. Этот модуль координирует запуск и мониторинг всех компонентов приложения на узлах кластера.
2. NodeManager (Менеджер узла):
Расположение: Работает на каждом узле кластера.
Функции: NodeManager отвечает за управление ресурсами на конкретном узле. Он отслеживает использование ресурсов (памяти, процессора) на узле и управляет контейнерами (containers) – изолированными средами выполнения, в которых запускаются задачи приложения. NodeManager также регулярно отправляет отчёты о состоянии узла и его ресурсах в ResourceManager.
3. ApplicationMaster (Менеджер приложения):
Расположение: Запускается для каждого приложения, работающего на YARN.
Функции: ApplicationMaster управляет выполнением конкретного приложения. Он запрашивает у ResourceManager необходимые ресурсы, распределяет их между задачами приложения, следит за выполнением задач и обрабатывает возможные сбои. Это обеспечивает гибкость и адаптивность выполнения приложений, так как каждый ApplicationMaster может иметь свои собственные стратегии управления задачами и ресурсами.
YARN значительно улучшает масштабируемость, гибкость и эффективность кластера Hadoop благодаря следующим функциям:
1. Разделение управления ресурсами и обработкой данных:
В отличие от первой версии Hadoop, где MapReduce выполнял функции как фреймворка для обработки данных, так и системы управления ресурсами, YARN выделяет управление ресурсами в отдельный слой. Это позволяет запускать на кластере не только задачи MapReduce, но и другие типы приложений (например, Apache Spark, Apache Flink), что делает Hadoop универсальной платформой для работы с большими данными.
2. Поддержка различных типов рабочих нагрузок:
YARN позволяет одновременно выполнять на одном кластере различные типы приложений, включая интерактивные запросы, поточные вычисления и пакетную обработку данных. Это делает YARN более гибкой системой, способной эффективно использовать ресурсы кластера для различных задач и улучшать общую производительность.
3. Динамическое выделение ресурсов:
Система YARN способна динамически перераспределять ресурсы между приложениями в зависимости от их текущих потребностей. Это означает, что ресурсы, неиспользуемые одним приложением, могут быть перераспределены для других задач, что повышает эффективность использования кластера и уменьшает время простоя ресурсов.
4. Масштабируемость:
YARN спроектирована для работы на масштабируемых кластерах, что позволяет увеличивать количество узлов и приложений без значительных изменений в конфигурации системы. Это достигается благодаря децентрализации управления: ResourceManager и NodeManager распределяют нагрузку, а ApplicationMaster обеспечивает индивидуальное управление приложениями.
Введение YARN произвело революцию в экосистеме Hadoop, превратив её из платформы, ориентированной исключительно на MapReduce, в универсальную среду для выполнения различных типов приложений. YARN открыло возможности для интеграции множества фреймворков и инструментов, таких как Apache Spark, Apache Storm, Apache Flink, и другие. Это сделало Hadoop более гибкой и адаптивной платформой, способной удовлетворять разнообразные потребности современных организаций в области обработки и анализа больших данных.
YARN также обеспечило более эффективное использование ресурсов в кластерах, что позволило компаниям снизить затраты на инфраструктуру и увеличить производительность своих систем. В результате YARN стал неотъемлемым компонентом для всех, кто работает с большими данными, обеспечивая надёжную, масштабируемую и гибкую основу для работы с различными типами данных и вычислений.
Ниже приведена схема, которая показывает, как компоненты YARN взаимодействуют между собой для распределения ресурсов и выполнения задач.
ResourceManager включает в себя два основных модуля: Scheduler и ApplicationManager.
NodeManagers управляют ресурсами на каждом узле, и каждый из них содержит несколько контейнеров (Containers), где выполняются задачи.
ApplicationMasters представляют разные приложения, которые взаимодействуют как с ResourceManager, так и с NodeManagers. (Рис. 2)

– Hive
Hive – это инструмент, разработанный для анализа больших объемов данных, который предоставляет удобный интерфейс, похожий на SQL, для взаимодействия с данными в экосистеме Hadoop. Основная задача Hive – упрощение работы с Hadoop, позволяя пользователям выполнять запросы, обработку и агрегацию данных с помощью языка, близкого к SQL, что делает его доступным для людей, не имеющих глубоких знаний в программировании на Java или MapReduce.
Hive использует язык запросов HiveQL (или HQL), который является расширением SQL и поддерживает большинство стандартных SQL-команд. Это позволяет пользователям писать запросы, управлять данными и создавать отчеты без необходимости напрямую взаимодействовать с Hadoop MapReduce, что может быть сложным и трудоемким процессом. Внутренне Hive преобразует запросы HiveQL в задачи MapReduce, которые затем выполняются на кластере Hadoop. Это превращает сложные вычислительные задачи в последовательность более управляемых шагов, что упрощает работу с большими данными.
Одной из ключевых особенностей Hive является поддержка различных форматов хранения данных, таких как текстовые файлы, паркет (Parquet), Avro и ORC (Optimized Row Columnar). Это позволяет пользователям выбирать наиболее подходящий формат в зависимости от конкретных требований к производительности и эффективности хранения. Hive также включает средства для работы с метаданными, что упрощает управление схемами данных и поддерживает работу с большими и сложными наборами данных.
Hive предлагает возможности для расширения и настройки, что позволяет интегрировать его с различными инструментами и платформами, такими как Apache HBase, Apache Tez и Apache Spark. Эти возможности делают Hive гибким инструментом для обработки и анализа данных, поддерживающим как традиционные задачи бизнес-анализа, так и более сложные вычислительные задачи в области больших данных.
Ниже приведена блок-схема, показывающая работу HiveQL. (Рис. 3)

В этой схеме представлено:
Пользовательский Интерфейс (HiveQL): Пользователь вводит запросы.
Hive: Обрабатывает запросы через парсер, оптимизатор и планировщик.
Hadoop: Выполняет запросы, используя HDFS для хранения данных и MapReduce/Tez/Spark для обработки.
Выходные Данные: Результаты запроса возвращаются пользователю.
– Pig
Pig – это платформа для анализа больших данных, разработанная для упрощения обработки и анализа больших объемов данных, хранящихся в распределенных системах, таких как Apache Hadoop. Pig позволяет пользователям выполнять сложные операции обработки данных, такие как фильтрация, агрегация и преобразование данных, с помощью языка программирования высокого уровня, известного как Pig Latin. Это делает работу с большими данными более доступной для аналитиков и разработчиков, которые не обязательно являются экспертами в низкоуровневом программировании или администрировании систем.
Pig Latin, язык программирования, используемый в Pig, представляет собой декларативный язык, который позволяет пользователям описывать операции обработки данных, не беспокоясь о том, как именно эти операции будут выполнены. Это значительно упрощает создание сложных рабочих процессов, так как пользователи могут сосредоточиться на том, что нужно сделать с данными, а не на том, как это будет осуществлено. Кроме того, Pig Latin обеспечивает гибкость и мощность благодаря своей способности обрабатывать как структурированные, так и неструктурированные данные.
Одной из ключевых особенностей Pig является его способность интегрироваться с Hadoop, что позволяет эффективно использовать ресурсы распределенных систем для обработки больших объемов данных. Pig выполняет свои задачи на основе MapReduce, однако предоставляет более высокоуровневый интерфейс, чем традиционный MapReduce API. Это позволяет ускорить разработку и уменьшить сложность программного обеспечения для обработки данных, поскольку Pig берет на себя управление распределенными вычислениями и хранением данных.
Pig также поддерживает расширения через пользовательские функции и скрипты, что позволяет адаптировать платформу под специфические требования анализа данных. Например, пользователи могут создавать свои собственные функции для обработки данных или интегрировать Pig с другими инструментами и библиотеками для выполнения более сложных задач. Это делает Pig универсальным инструментом для анализа данных, способным справляться с различными задачами и интегрироваться с разными технологиями в экосистеме обработки больших данных.
Процесс работы Pig можно представить в виде нескольких этапов, которые включают подготовку данных, написание и выполнение Pig Latin скрипта, и обработку результатов.
Ниже представлена упрощенная схема того, как работает Pig:
1. Подготовка данных
– Исходные данные: Обычно данные хранятся в распределенной файловой системе, такой как HDFS (Hadoop Distributed File System). Эти данные могут быть как структурированными (например, таблицы), так и неструктурированными (например, текстовые файлы).
2. Написание Pig Latin скрипта
– Скрипт Pig Latin: Пользователь пишет скрипт на языке Pig Latin, описывающий, какие операции нужно выполнить над данными. Скрипт может включать в себя такие операции, как фильтрация, группировка, объединение, агрегирование и другие преобразования данных.
Пример скрипта:
```pig
–– Загрузка данных
data = LOAD 'input_data.txt' AS (field1:int, field2:chararray);
–– Фильтрация данных
filtered_data = FILTER data BY field1 > 100;
–– Группировка данных
grouped_data = GROUP filtered_data BY field2;
–– Агрегация данных
aggregated_data = FOREACH grouped_data GENERATE group AS category, COUNT(filtered_data) AS count;
–– Сохранение результата
STORE aggregated_data INTO 'output_data.txt';
```
3. Выполнение скрипта
– Компиляция: Pig Latin скрипт компилируется в последовательность задач MapReduce, которые могут быть выполнены на кластере Hadoop. Компилятор Pig преобразует высокоуровневый код в низкоуровневые MapReduce задачи.
– Выполнение MapReduce задач: Pig запускает созданные задачи MapReduce на кластере Hadoop. Каждая задача выполняется на отдельных узлах кластера, которые обрабатывают фрагменты данных параллельно. В процессе работы MapReduce задачи делятся на этапы "Map" (преобразование данных) и "Reduce" (агрегация результатов).
4. Обработка результатов
– Сохранение результатов: Результаты выполнения скрипта сохраняются в файловую систему, такую как HDFS, или могут быть выгружены в другие системы хранения данных. В зависимости от скрипта, результаты могут быть сохранены в виде текстовых файлов, таблиц или других форматов данных.
– Анализ результатов: Пользователь может проанализировать результаты, используя дополнительные инструменты или визуализировать их для получения инсайтов и поддержки принятия решений.
5. Обратная связь и итерации
– Обратная связь: На основе анализа результатов пользователь может внести изменения в скрипт Pig Latin, чтобы улучшить обработку данных или скорректировать результаты.
– Итерации: Процесс может повторяться с новыми данными или изменениями в скрипте для дальнейшего анализа и улучшения результатов.
Эта схема позволяет Pig эффективно работать с большими объемами данных, обеспечивая простоту использования и мощные возможности для анализа данных.
– HBase
HBase – это распределенная, масштабируемая база данных, построенная на основе модели NoSQL, которая работает поверх Hadoop Distributed File System (HDFS). Основной целью HBase является предоставление возможности работы с большими объемами данных в реальном времени, обеспечивая низкую задержку при доступе к данным и высокую масштабируемость. HBase разрабатывался для решения задач, связанных с хранением и обработкой неструктурированных данных, которые не подходят для традиционных реляционных баз данных, особенно когда требуется работа с огромными объемами данных.
HBase использует модель данных, основанную на колонках, что отличается от традиционных реляционных баз данных, использующих строки и таблицы. В HBase данные хранятся в таблицах, которые делятся на строки и колонки, при этом каждая ячейка может хранить данные разного типа и иметь разное количество версий. Такая структура позволяет эффективно выполнять запросы к данным, поддерживать низкую задержку и обрабатывать данные с высокой скоростью, что делает HBase идеальным для использования в реальном времени, а также в аналитических приложениях, где требуется быстрый доступ к данным.
Одной из ключевых особенностей HBase является его способность масштабироваться горизонтально. Это достигается за счет распределенной архитектуры, в которой данные распределяются по нескольким узлам кластера. Каждый узел в кластере HBase выполняет роль RegionServer и хранит определенные части данных, называемые регионами. Эти регионы автоматически распределяются и балансируются между различными узлами кластера, что позволяет HBase справляться с увеличением объема данных и числа запросов. В дополнение к этому, HBase поддерживает репликацию данных для обеспечения высокой доступности и отказоустойчивости, что делает систему надежной даже в случае сбоя отдельных узлов.
HBase работает поверх HDFS, что позволяет использовать его возможности для хранения и управления большими объемами данных, эффективно используя распределенные ресурсы Hadoop. HDFS обеспечивает высокую надежность хранения данных и позволяет HBase эффективно работать с данными, хранящимися в распределенной файловой системе. Взаимодействие между HBase и HDFS позволяет пользователям использовать преимущества обоих инструментов: HBase для быстрого доступа и обработки данных, и HDFS для надежного и масштабируемого хранения.
HBase представляет собой мощный инструмент для работы с большими данными, предоставляя возможности для хранения и обработки данных в реальном времени, что особенно полезно в сценариях, где требуется высокая производительность и масштабируемость, таких как веб-приложения, анализ больших данных и обработка транзакций в реальном времени.

HBase обеспечивает эффективное хранение и обработку данных, используя распределенную архитектуру и ключевые компоненты, такие как RegionServer, HBase Master и Zookeeper. Процесс записи данных начинается с того, что клиент отправляет запрос на запись в HBase. Запрос сначала поступает к HBase Master, который определяет соответствующий RegionServer. На этом сервере данные попадают в MemStore, временное хранилище в памяти, где они накапливаются до тех пор, пока MemStore не заполнится. Затем данные записываются в HFile на диск, где они организованы по колонкам для оптимизации хранения и быстрого доступа. После записи в HFile, MemStore очищается, чтобы освободить место для новых данных. (Рис. 4)
При чтении данных клиент отправляет запрос на чтение, который также направляется к HBase Master для определения нужного RegionServer. На RegionServer данные сначала ищутся в MemStore. Если требуемые данные не найдены в MemStore, производится поиск в HFiles, которые хранят данные на диске. Результаты из MemStore и HFiles объединяются и возвращаются клиенту, обеспечивая точный и быстрый доступ к информации.
HBase также управляет балансировкой нагрузки и репликацией данных для обеспечения надежности и масштабируемости. HBase Master отвечает за распределение регионов между RegionServer, чтобы равномерно распределить нагрузку и избежать перегрузки отдельных узлов. Репликация данных обеспечивает отказоустойчивость, так как копии данных хранятся на нескольких RegionServer, что гарантирует доступность данных даже в случае сбоя узлов.
Zookeeper играет важную роль в координации и управлении HBase. Он отслеживает состояние RegionServer, управляет метаданными и помогает в выборе лидера и синхронизации между компонентами системы. Все запросы клиентов обрабатываются через HBase Master, который направляет их к соответствующим RegionServer. Региональные серверы обрабатывают запросы, взаимодействуя с MemStore и HFiles, и могут обращаться к Zookeeper для координации. HBase Master и Zookeeper работают вместе, чтобы обеспечить эффективное и масштабируемое хранение и обработку данных.
– ZooKeeper
ZooKeeper – это специализированный сервис, предназначенный для координации и управления конфигурацией в распределенных приложениях. Он был разработан для упрощения и повышения надежности взаимодействия между различными компонентами распределенных систем, которые могут быть разбросаны по множеству узлов. В основе работы ZooKeeper лежит идея предоставления централизованного сервиса для управления конфигурацией, синхронизации процессов и координации распределенных задач.
Одна из ключевых функций ZooKeeper – обеспечение надежной и согласованной конфигурации для распределенных приложений. В больших распределенных систем часто возникают проблемы с синхронизацией конфигурационных данных между разными узлами, что может приводить к сбоям или некорректной работе приложения. ZooKeeper решает эту проблему, предоставляя единое место, где хранятся все конфигурационные данные и метаданные. Узлы системы могут обращаться к ZooKeeper для получения актуальной конфигурации и оперативно обновлять свои настройки при изменении конфигурации, что гарантирует согласованность данных по всей системе.
Кроме того, ZooKeeper играет важную роль в обеспечении синхронизации и координации распределенных процессов. В распределенных системах часто возникают задачи, требующие синхронизации между различными узлами, такие как выбор лидера, блокировка ресурсов или координация выполнения задач. ZooKeeper предоставляет механизмы для реализации этих задач, включая локации, семафоры и уведомления о событиях. Например, при необходимости выбрать лидера из набора узлов, ZooKeeper может управлять этим процессом, гарантируя, что в любой момент времени существует только один активный лидер и что все узлы согласованы относительно текущего лидера.
ZooKeeper использует концепцию "znode" – элементов иерархической структуры, которые хранят данные и метаданные. Узлы в ZooKeeper могут быть листовыми (хранят данные) или промежуточными (служат для организации структуры). Эта иерархическая структура позволяет эффективно управлять конфигурацией и синхронизацией, так как все узлы системы имеют доступ к актуальной информации о состоянии и конфигурации через ZooKeeper. Когда данные или конфигурация изменяются, ZooKeeper оповещает все заинтересованные узлы о произошедших изменениях, что обеспечивает своевременное обновление информации по всей системе.
ZooKeeper обеспечивает надежное и эффективное управление конфигурацией и координацию процессов в распределенных системах, что является критически важным для обеспечения их стабильности и согласованности. Его способность централизованно управлять данными и синхронизацией делает его неотъемлемым инструментом для современных распределенных приложений, таких как Apache Hadoop, Apache HBase и других технологий, которые требуют координации между множеством узлов и процессов.

Основные компоненты и их функции (Рис. 5)
Clients (Приложения): Приложения и распределенные системы (например, Apache HBase, Apache Kafka) взаимодействуют с ZooKeeper для получения конфигурационных данных, синхронизации и координации. Клиенты отправляют запросы и получают обновления через ZooKeeper.
ZooKeeper Ensemble (Кластер): ZooKeeper Nodes (Узлы ZooKeeper): Кластер состоит из нескольких узлов ZooKeeper, которые работают совместно для обеспечения высокой доступности и отказоустойчивости. Каждый узел хранит копию данных и метаданных, и все узлы работают вместе для обработки запросов от клиентов.
Узлы ZooKeeper используют протокол согласования для поддержания согласованности данных между собой. В случае сбоя одного из узлов, остальные продолжают работать, обеспечивая надежность системы.
ZNodes (Данные): ZooKeeper хранит данные в иерархической структуре узлов, называемых ZNodes. Эти узлы могут быть:
Листовые узлы: Хранят данные (например, конфигурации или значения).
Промежуточные узлы: Используются для создания структуры и организации данных.
Примеры ZNodes:
/ (корневой узел): Начальная точка иерархии.
/config: Узел, содержащий конфигурационные данные.
/locks: Узел для управления блокировками и синхронизацией ресурсов.
/leaders: Узел для координации и выбора лидера в распределенной системе.
Процесс работы
Запросы от клиентов: Клиенты отправляют запросы к кластеру ZooKeeper для получения данных, обновления конфигураций или синхронизации. Запросы могут быть на чтение или запись данных, управление блокировками и т.д.
Обработка запросов: Узлы ZooKeeper обрабатывают запросы от клиентов и возвращают необходимые данные. Если данные изменяются, ZooKeeper обновляет соответствующие ZNodes и оповещает клиентов об изменениях.
Координация и синхронизация: Когда данные в ZNodes изменяются, ZooKeeper уведомляет все клиенты, которые подписаны на эти изменения. Это позволяет поддерживать согласованность конфигурации и синхронизацию процессов в распределенных системах.
Управление и отказоустойчивость: ZooKeeper использует кластер из нескольких узлов для обеспечения высокой доступности и отказоустойчивости. Если один узел выходит из строя, другие узлы продолжают обслуживать запросы, обеспечивая надежность и непрерывность работы.
Эта схема помогает визуализировать, как ZooKeeper управляет данными и координирует процессы в распределенных системах, обеспечивая централизованное и надежное решение для управления конфигурацией и синхронизацией.
Кроме основных компонентов Hadoop, существует множество других сопутствующих технологий и инструментов, таких как Apache Spark (для быстрой обработки данных в памяти), Apache Kafka (для потоковой передачи данных), и другие, которые расширяют возможности работы с большими данными, делая их обработку и анализ более эффективными и масштабируемыми.
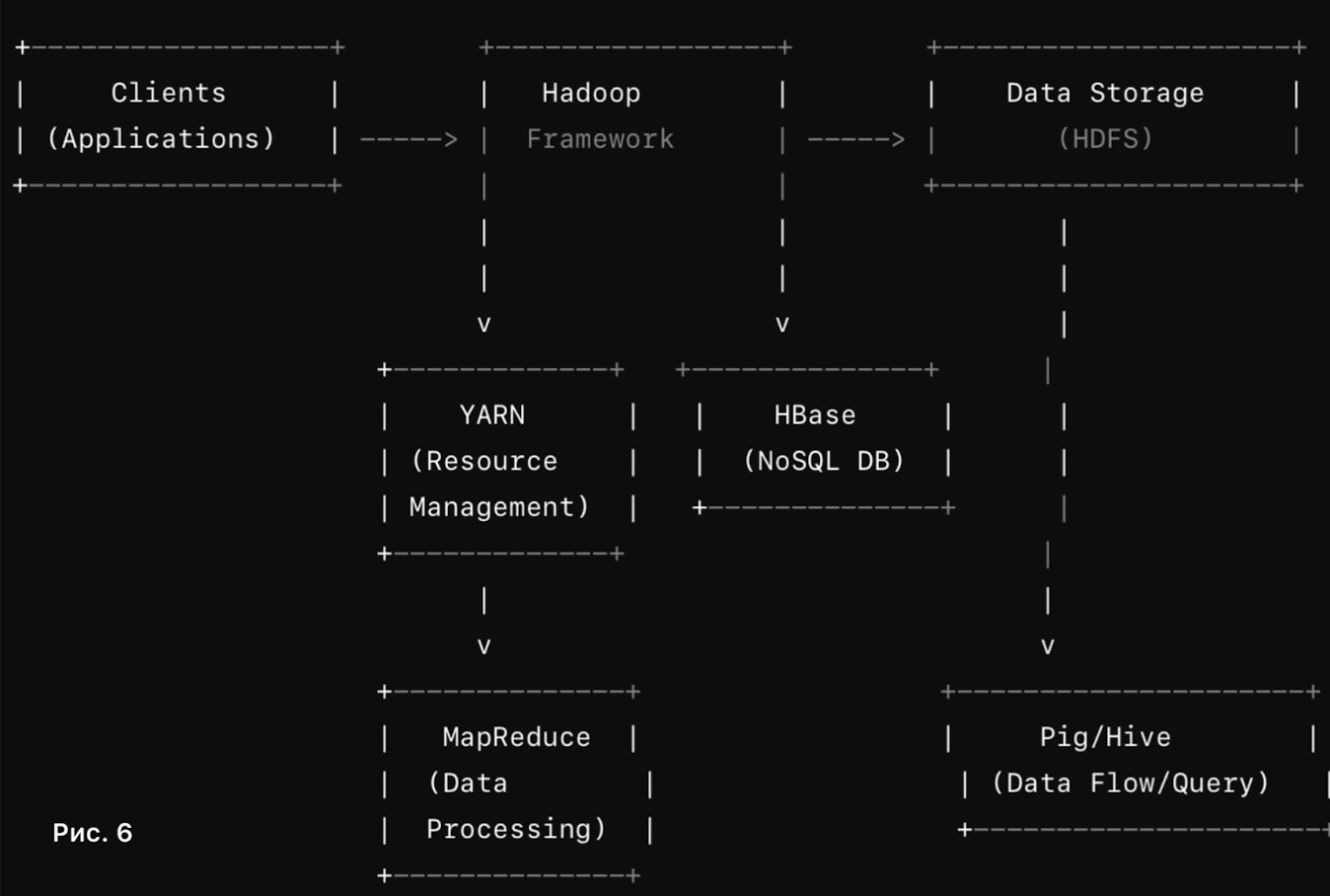
Описание компонентов на схеме (Рис. 6).
1. Clients (Приложения): Запускают задачи и запросы на обработку данных.
2. Hadoop Framework (Фреймворк Hadoop): Включает YARN для управления ресурсами и планирования задач, а также HDFS для распределенного хранения данных.
3. Data Storage (Хранение данных): HDFS (Hadoop Distributed File System) хранит данные в распределенной файловой системе.
4. Data Processing (Обработка данных): MapReduce парадигма обработки данных, распределяющая задачи по узлам кластера.
– HBase: NoSQL база данных для реального времени и быстрого доступа к данным.
– Pig/Hive: Инструменты для обработки данных и выполнения запросов, где Pig использует язык скриптов, а Hive – SQL-подобные запросы.
Схема иллюстрирует взаимодействие между основными компонентами экосистемы Hadoop, обеспечивая хранение, обработку и управление данными.
Преимущества и вызовы больших данных
Использование больших данных (Big Data) имеет множество преимуществ, которые оказывают значительное влияние на различные сферы бизнеса, науки и общества в целом. Большие данные представляют собой огромные объемы информации, поступающие из разнообразных источников, таких как социальные сети, датчики, транзакционные системы, интернет вещей (IoT) и другие. Эти данные могут быть структурированными и неструктурированными, и благодаря современным технологиям их можно анализировать и извлекать из них полезную информацию.
Улучшение принятия решений
Одним из ключевых преимуществ использования больших данных является возможность улучшения процесса принятия решений. Анализ больших объемов данных позволяет организациям выявлять скрытые паттерны и тенденции, которые не были бы очевидны при использовании традиционных методов анализа. Это, в свою очередь, помогает компаниям принимать более обоснованные и информированные решения, снижая уровень неопределенности и риска. Например, анализ поведения потребителей и рыночных тенденций с помощью больших данных позволяет компаниям разрабатывать более эффективные маркетинговые стратегии и предлагать продукты, которые лучше соответствуют потребностям клиентов.


