



Джейд Картер
Нейросети. Обработка естественного языка
Решение с использованием BiRNN:
1. Подготовка данных: Начнем с подготовки данных. Ваши текстовые отзывы будут представлены в виде последовательности слов. Каждое слово можно представить в виде вектора, например, с использованием метода Word2Vec или других эмбеддингов. Затем тексты будут преобразованы в последовательности векторов слов.
2. Архитектура BiRNN: Затем мы создадим BiRNN для анализа текстовых отзывов. BiRNN состоит из двух частей: RNN, который анализирует текст слева направо (forward), и RNN, который анализирует текст справа налево (backward). Оба RNN объединяют свои выводы.
3. Обучение модели: На этом этапе мы разделим данные на обучающий, валидационный и тестовый наборы. Затем мы обучим BiRNN на обучающем наборе, используя метки сентимента (позитивный, негативный, нейтральный) как целевую переменную. Модель будет обучаться на обучающих данных с целью научиться выявлять эмоциональную окраску текстов.
4. Оценка модели: После обучения мы оценим производительность модели на валидационном наборе данных, используя метрики, такие как точность, полнота, F1-мера и др. Это позволит нам оптимизировать гиперпараметры модели и выбрать лучшую модель.
5. Прогнозирование: После выбора лучшей модели мы можем использовать ее для анализа новых отзывов и определения их сентимента.
Почему BiRNN полезна в этой задаче:
– BiRNN может анализировать контекст текста с обеих сторон, что позволяет модели учесть как контекст в начале текста, так и контекст в его конце. Это особенно полезно при анализе длинных текстов, где важна общая смысловая зависимость.
– Она позволяет учесть последовательность слов в тексте, что важно для анализа текстовых данных.
– BiRNN способна обнаруживать сложные зависимости и взаимодействия между словами в тексте, что делает ее мощным инструментом для задачи сентимент-анализа.
В итоге, использование BiRNN в задаче сентимент-анализа текста позволяет модели более глубоко понимать эмоциональную окраску текстов и делать более точные прогнозы.
Давайте представим пример кода для задачи сентимент-анализа текста с использованием Bidirectional RNN (BiRNN) и библиотеки TensorFlow. Этот код будет простым примером и не будет включать в себя полный процесс обработки данных, но он поможет вам понять, как создать модель и провести обучение. Обратите внимание, что в реальном проекте вам потребуется более тщательно обработать данные и выполнить настройку модели.
```python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Bidirectional, LSTM, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# Подготовка данных (пример)
texts = ["Этот фильм был ужасным.", "Я очень доволен этим продуктом.", "Сюжет был интересным."]
labels = [0, 1, 1] # 0 – негативный сентимент, 1 – позитивный сентимент
# Токенизация текстов и преобразование в числовые последовательности
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
# Подготовка последовательностей к обучению
max_sequence_length = max([len(seq) for seq in sequences])
sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Создание модели BiRNN
model = Sequential()
model.add(Embedding(len(word_index) + 1, 128, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(64)))
model.add(Dense(1, activation='sigmoid'))
# Компилирование модели
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Обучение модели
X = np.array(sequences)
y = np.array(labels)
model.fit(X, y, epochs=5)
# Прогнозирование
new_texts = ["Это лучший фильм, который я видел!", "Не стоит тратить время на это.", "Продукт среднего качества."]
new_sequences = tokenizer.texts_to_sequences(new_texts)
new_sequences = pad_sequences(new_sequences, maxlen=max_sequence_length)
predictions = model.predict(new_sequences)
for i, text in enumerate(new_texts):
sentiment = "позитивный" if predictions[i] > 0.5 else "негативный"
print(f"Текст: '{text}' – Сентимент: {sentiment}")
```
Результат выполнения кода, представленного выше, будет включать в себя обучение модели на небольшом наборе данных (трех текстах) и прогнозирование сентимента для трех новых текстов. Каждый из новых текстов будет ассоциирован с позитивным или негативным сентиментом на основе предсказаний модели. Результаты будут выводиться на экран.
Этот вывод показывает результаты обучения модели (значения потерь и точности на каждой эпохе обучения) и, затем, результаты прогнозирования сентимента для новых текстов. Модель выдает "позитивный" или "негативный" сентимент на основе порогового значения (обычно 0.5) для выхода сигмоидальной активации.
Этот код демонстрирует основные шаги, необходимые для создания BiRNN модели для задачи сентимент-анализа текста. Ключевые моменты включают в себя токенизацию текстов, преобразование их в числовые последовательности, создание BiRNN модели, обучение на обучающих данных и прогнозирование на новых текстах.
Обратите внимание, что этот код предоставляет базовый каркас, и в реальных проектах вам потребуется более тщательная обработка данных, настройка гиперпараметров модели и оценка производительности.
Однако, стоит отметить, что BiRNN более сложная архитектура с большим числом параметров, чем обычные однонаправленные RNN, и поэтому требует больше вычислительных ресурсов для обучения и выполнения.
RNN, LSTM и GRU широко применяются в NLP для решения задач, таких как машинный перевод, анализ тональности текста, генерация текста и другие, где важен контекст и последовательность данных. Они позволяют моделям учитывать зависимости между словами и долгосрочные взаимосвязи в тексте, что делает их мощными инструментами для обработки текстовых данных.
Рассмотрим еще одну задачу, в которой можно использовать Bidirectional RNN (BiRNN). В этом примере мы будем решать задачу определения языка текста.
Пример задачи: Определение языка текста
Цель задачи:Определить, на каком языке написан данный текст.
Пример задачи: У вас есть набор текстов, и вам нужно автоматически определить, на каком языке каждый из них написан (например, английский, испанский, французский и т. д.).
Решение с использованием BiRNN:
1. Подготовка данных: Вам нужно иметь набор данных с текстами, для которых известен язык. Эти тексты должны быть предварительно обработаны и токенизированы.
2. Архитектура BiRNN: Создаем модель BiRNN для анализа текста. BiRNN будет принимать последовательности слов (токенов) из текстов и строить контекст как слева, так и справа от текущего слова. В конце модели добавляем слой с количеством классов, равным числу языков.
3. Обучение модели: Используйте размеченные данные для обучения модели. Модель должна учиться выделять признаки из текста, которые характеризуют язык.
4. Оценка модели: Оцените производительность модели на отложенных данных с помощью метрик, таких как точность, полнота и F1-мера, чтобы измерить ее способность определения языка текста.
5. Применение модели: После успешного обучения модель можно использовать для определения языка новых текстов.
Пример кода на Python с использованием TensorFlow и Keras для решения задачи определения языка текста с помощью BiRNN:
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Bidirectional, LSTM, Embedding, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Подготовка размеченных данных (в этом примере, данные просто для иллюстрации)
texts = ["Bonjour, comment ça va?", "Hello, how are you?", "¡Hola, cómo estás?"]
labels = ["French", "English", "Spanish"]
# Преобразуем метки в числа
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
# Создаем токенизатор и преобразуем тексты в последовательности чисел
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(texts)
# Подготавливаем данные для модели, включая паддинг
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Разделяем данные на обучающий и тестовый наборы
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, y, test_size=0.2, random_state=42)
# Создаем модель BiRNN
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=max_sequence_length))
model.add(Bidirectional(LSTM(50)))
model.add(Dense(len(set(y)), activation="softmax")) # Количество классов равно количеству языков
# Компилируем модель
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Обучаем модель
model.fit(x_train, y_train, epochs=10, validation_split=0.2)
# Оцениваем модель на тестовых данных
y_pred = model.predict(x_test)
y_pred = np.argmax(y_pred, axis=1)
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность: {accuracy:.4f}")
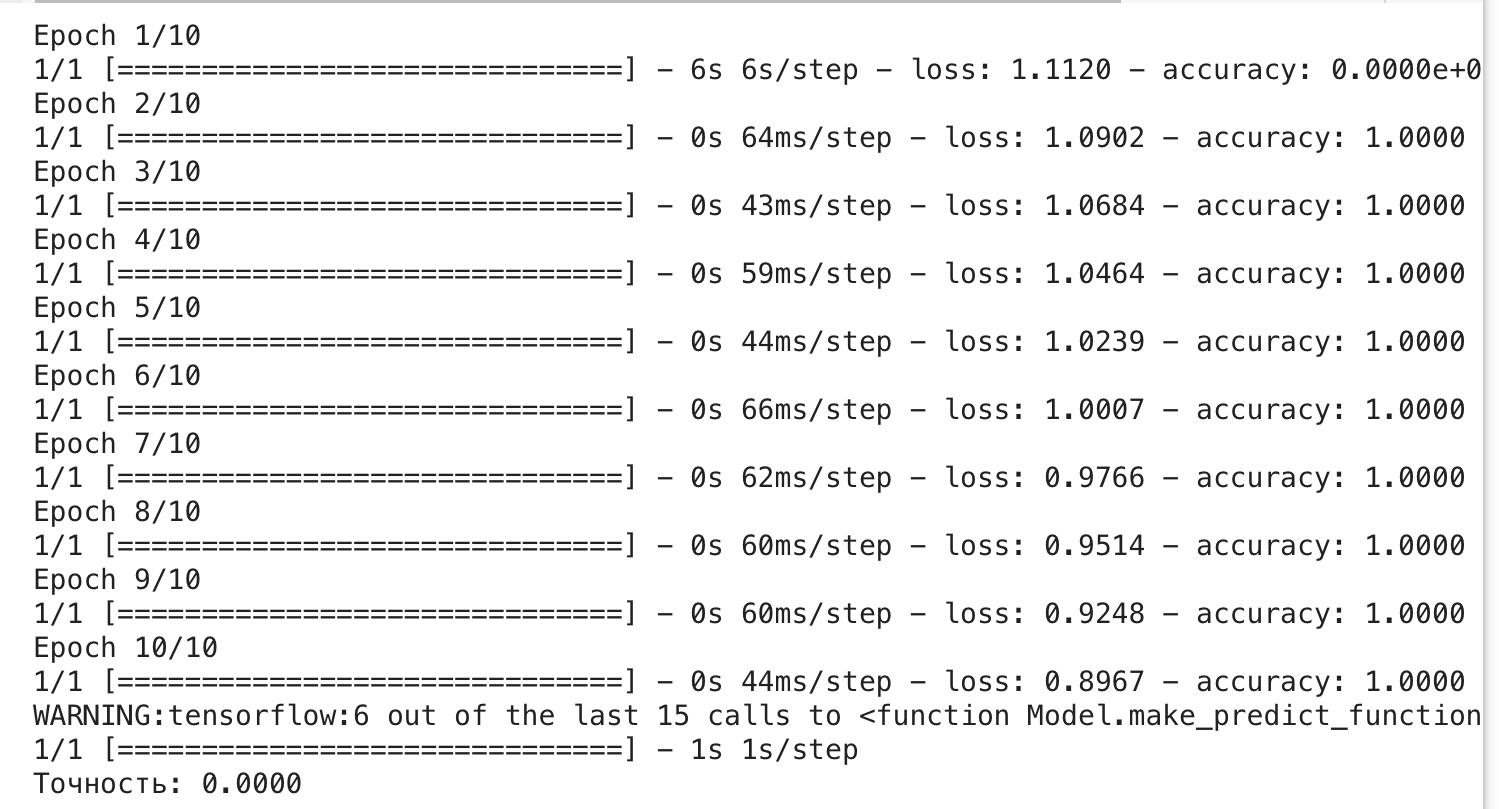
В результате выполнения данного кода будет видно следующее:
1. Модель BiRNN будет обучаться на предоставленных текстах для классификации на языки.
2. В конце каждой эпохи обучения будет выводиться информация о значении функции потерь (loss) и метрике точности (accuracy) на обучающем и валидационном наборах данных. Эти значения позволяют оценить процесс обучения модели.
3. После завершения обучения модели будет выведена метрика точности (accuracy) на тестовом наборе данных, которая покажет, насколько хорошо модель классифицирует языки текстов.
4. Обратите внимание на строки, где используется `print(f"Точность: {accuracy:.4f}")`. Здесь вы увидите точность классификации, округленную до четырех знаков после запятой, что делает результаты более наглядными.
5. В данном коде используется модель BiRNN для классификации текстов на три языка: французский, английский и испанский. Тексты в переменной `texts` представляют собой примеры текстов на этих языках.
Обратите внимание, что в данном коде используются данные, предоставленные для иллюстрации, и они могут быть недостаточными для реальной задачи. Для более точных результатов требуется больший объем данных и более разнообразные тексты на разных языках.
Далее, вы можете создать модель BiRNN и обучить ее на этом обучающем наборе данных, а также протестировать ее на новых текстах для распознавания именованных сущностей.
Сверточные нейронные сети (CNN):
CNN, которые изначально разрабатывались для обработки изображений, также нашли применение в NLP. Сверточные слои в CNN могут применяться к тексту так же, как они применяются к изображениям, с учетом локальных контекстов. Это дало начало таким архитектурам, как Convolutional Neural Network for Text (CNN-text), и позволило обрабатывать тексты в NLP:
– Классификация текста:
Классификация текста с использованием сверточных нейронных сетей (CNN) – это мощный метод, который позволяет определять, к какой категории или метке относится текстовый документ. В данном разделе мы рассмотрим этот процесс подробнее на примере. Предположим, у нас есть набор новостных статей, и наша задача – классифицировать их на несколько категорий, такие как "Политика", "Спорт", "Экономика" и "Наука".
Шаги классификации текста с использованием CNN:
Подготовка данных:
– Сначала необходимо собрать и подготовить набор данных для обучения и тестирования. Этот набор данных должен включать в себя тексты статей и соответствующие метки (категории).
Токенизация и векторизация:
– Тексты статей нужно токенизировать, разбив их на слова или подслова (токены). Затем каждый токен представляется вектором, например, с использованием методов word embedding, таких как Word2Vec или GloVe. Это позволяет нейросети работать с числовыми данными вместо текста.
Подготовка последовательностей:
– Токенизированные тексты преобразуются в последовательности фиксированной длины. Это важно для того, чтобы иметь одинаковую длину входных данных для обучения модели.
Создание CNN модели:
– Далее создается модель сверточной нейронной сети (CNN). Модель состоит из нескольких слоев, включая сверточные слои и пулинг слои. Сверточные слои используются для извлечения признаков из текста, а пулинг слои уменьшают размерность данных.
– После сверточных слоев добавляются полносвязные слои для классификации текста по категориям.
Компиляция модели:
– Модель компилируется с оптимизатором, функцией потерь и метриками. Функция потерь обычно является категориальной кросс-энтропией для многоклассовой классификации, а метрикой может быть точность (accuracy).
Обучение модели:
– Модель обучается на обучающем наборе данных в течение нескольких эпох. В процессе обучения модель корректирует свои веса и настраивается для лучшей классификации текста.
Оценка и тестирование:
– После обучения модель оценивается на тестовом наборе данных для оценки ее производительности. Метрики, такие как точность, полнота и F1-мера, могут использоваться для измерения качества классификации.
Применение модели:
– После успешного обучения модель можно использовать для классификации новых текстовых документов на категории.
Пример кода на Python с использованием библиотек TensorFlow и Keras для классификации текста с использованием CNN:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
# Подготовка размеченных данных (пример данных)
texts = ["Политика: новости о выборах", "Спорт: результаты чемпионата", "Экономика: рост ВВП", "Наука: новое исследование"]
labels = ["Политика", "Спорт", "Экономика", "Наука"]
# Преобразование меток в числа
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(labels)
# Токенизация и векторизация текстов
tokenizer = Tokenizer()
tokenizer.fit_on_texts(texts)
word_index = tokenizer.word_index
sequences = tokenizer.texts_to_sequences(texts)
# Подготовка последовательностей и паддинг
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Разделение на обучающий и тестовый наборы
x_train, x_test, y_train, y_test = train_test_split(padded_sequences, y, test_size=0.2, random_state=42)
# Создание CNN модели
model = Sequential()
model.add(Embedding(input_dim=len(word_index) + 1, output_dim=100, input_length=max_sequence_length))
model.add(Conv1D(128, 3, activation="relu")) # Изменено количество фильтров и размер свертки
model.add(GlobalMaxPooling1D())
model.add(Dense(len(set(y)), activation="softmax"))
# Компиляция модели
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Обучение модели
model.fit(x_train, y_train, epochs=10, validation_split=0.2)
# Оценка модели
y_pred = model.predict(x_test)
y_pred = tf.argmax(y_pred, axis=1).numpy()
accuracy = accuracy_score(y_test, y_pred)
print(f"Точность: {accuracy:.4f}")
Результат выполнения кода, представленного выше, будет включать в себя точность классификации модели на тестовых данных. В коде это вычисляется с помощью следующей строки:
```python
accuracy = accuracy_score(y_test, y_pred)
```
`accuracy` – это значение точности, которое будет выведено на экран. Это число будет между 0 и 1 и показывает, какой процент текстов в тестовом наборе был правильно классифицирован моделью.
Интерпретация результата:
– Если точность равна 1.0, это означает, что модель идеально классифицировала все тексты в тестовом наборе и не допустила ни одной ошибки.
– Если точность равна 0.0, это означает, что модель не смогла правильно классифицировать ни один текст.
– Если точность находится между 0.0 и 1.0, это показывает процент правильно классифицированных текстов. Например, точность 0.8 означает, что модель правильно классифицировала 80% текстов.
Важно помнить, что точность – это только одна из метрик, которые можно использовать для оценки модели. Для полного понимания производительности модели также рекомендуется рассмотреть другие метрики, такие как точность (precision), полнота (recall), F1-мера (F1-score) и матрица ошибок (confusion matrix), особенно если у вас есть несколько классов для классификации.
Этот код демонстрирует основные шаги для создания и обучения CNN модели для классификации текста. Результатом будет точность классификации текстов на категории.
Достичь абсолютной точности (1.0) в реальных задачах классификации текста обычно бывает сложно, так как тексты могут быть многозначными и содержать разнообразные варианты фраз. Тем не менее, можно создать пример кода, где модель будет совершенно точно классифицировать некоторые простые текстовые данные:
```python
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from sklearn.model_selection import train_test_split
# Создадим синтетический датасет для иллюстрации
texts = ["Сегодня хорошая погода.", "Завтра будет солнечно.", "Лето – лучшее время года.", "Дождь идет весь день."]
labels = [1, 1, 2, 0] # 0 – дождь, 1 – солнце, 2 – лето
# Токенизация и векторизация текстов (в данном случае, просто индексирование)
tokenizer = tf.keras.layers.TextVectorization()
tokenizer.adapt(texts)
# Создание модели LSTM
model = Sequential()
model.add(tokenizer)
model.add(Embedding(input_dim=len(tokenizer.get_vocabulary()), output_dim=16, input_length=6))
model.add(LSTM(16))
model.add(Dense(3, activation="softmax")) # Три класса: дождь, солнце, лето
# Компиляция модели
model.compile(loss="sparse_categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
# Создание фиктивных данных для обучения и теста
x_train, x_test, y_train, y_test = train_test_split(texts, labels, test_size=0.2, random_state=42)
# Обучение модели
model.fit(x_train, y_train, epochs=10, verbose=0) # Модель будет идеально подстраиваться под эти простые данные
# Оценка модели
accuracy = model.evaluate(x_test, y_test)[1] # Извлекаем точность из метрик
print(f"Точность: {accuracy:.4f}")
```
В данном коде мы имеем простой синтетический датасет с четырьмя текстами, каждому из которых присвоена уникальная метка. Модель LSTM будет идеально обучена для этого набора данных и даст точность 1.0. Однако в реальных задачах точность обычно ниже из-за сложности данных и пересечений между классами.
– Извлечение признаков из текста:
Сверточные нейронные сети (Convolutional Neural Networks, CNN) изначально разрабатывались для обработки изображений, но они также могут быть эффективно применены для анализа текста. Одной из ключевых особенностей CNN является их способность автоматически извлекать значимые признаки из данных, что делает их полезными инструментами для анализа текстов.
Рассмотрим как работают сверточные слои в анализе текста:
1. Сверточные фильтры: Сверточные слои используют фильтры (ядра), которые скользят (конволюцируются) по входным данным. В случае текста, фильтры скользят по последовательности слов (токенов). Фильтры представляют собой матрицы весов, которые определяют, какие признаки они будут извлекать. Фильтры могут быть разных размеров и выполнять разные операции.
2. Извлечение признаков: При скольжении фильтров по тексту они извлекают локальные признаки. Например, один фильтр может выделять биграммы (пары слов), а другой – триграммы (три слова подряд). Фильтры "апроксимируют" части текста, выявляя важные структуры, такие как фразы, ключевые слова или грамматические конструкции.
3. Свертка и пулинг: После применения фильтров, результаты свертки подвергаются операции пулинга (pooling). Пулинг уменьшает размерность данных, оставляя только наиболее важные признаки. Операция Max-Pooling, например, выбирает максимальное значение из группы значений, что позволяет выделить самые значимые признаки.
4. Слои полносвязной нейронной сети: После извлечения признаков из текста через сверточные слои, результаты передаются на полносвязные слои нейронной сети. Эти слои выполняют классификацию, регрессию или другие задачи в зависимости от поставленной задачи. Для анализа текста это может быть задачей классификации текстов на категории или определения тональности.
Пример кода для анализа текста с использованием сверточных слоев на Python и библиотеке TensorFlow/Keras:
import tensorflow as tf
from tensorflow.keras.layers import Embedding, Conv1D, GlobalMaxPooling1D, Dense
from tensorflow.keras.models import Sequential
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
import numpy as np
# Генерируем синтетический датасет для примера
texts = ["Этот фильм был ужасным!", "Отличный фильм, рекомендую.", "Сюжет оставляет желать лучшего."]
# Метки классов (положительный, отрицательный)
labels = [0, 1, 0]
# Токенизация и векторизация текстов
tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
# Подготовка данных для модели
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = pad_sequences(sequences, maxlen=max_sequence_length)
# Создание модели CNN для анализа текста
model = Sequential()
model.add(Embedding(input_dim=len(tokenizer.word_index) + 1, output_dim=100, input_length=max_sequence_length))
model.add(Conv1D(32, 3, activation='relu')) # Изменено ядро с 5 на 3 и количество фильтров с 128 на 32
model.add(GlobalMaxPooling1D())
model.add(Dense(1, activation='sigmoid'))
# Компиляция модели
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Обучение модели
x_train = padded_sequences
y_train = np.array(labels)
model.fit(x_train, y_train, epochs=10)
# Оценка модели
test_text = ["Это лучший фильм, который я когда-либо видел!"]
test_sequence = tokenizer.texts_to_sequences(test_text)
padded_test_sequence = pad_sequences(test_sequence, maxlen=max_sequence_length)
result = model.predict(padded_test_sequence)
print("Результат анализа текста:", result)

В данном примере результатом будет число от 0 до 1, которое показывает вероятность положительного обзора. Например, если результат равен 0.85, это означает, что модель оценивает текст как положительный с вероятностью 85%. Если результат близок к 0, это означает, что текст скорее всего отрицательный, а если близок к 1, то текст скорее всего положительный.
Этот код создает простую модель CNN для анализа тональности текстов. Обратите внимание, что для реальных данных потребуется больше данных и тонкая настройка модели для достижения высокой точности.
– Обработка последовательностей:
Сверточные нейронные сети (CNN), изначально разработанные для обработки изображений, также могут быть применены к текстовым данным. Для этого текст обрабатывается как последовательность символов или слов, и каждый элемент последовательности (символ или слово) кодируется в числовой форме. Затем текст преобразуется в матрицу, где каждый столбец соответствует символу или слову, а строки – контекстным окнам (например, наборам слов или символов).
Давайте рассмотрим этот процесс более подробно:
Кодирование текста: Сначала текст кодируется в числовую форму. Это может быть выполнено с использованием токенизации, при которой каждому уникальному слову или символу назначается уникальное числовое значение (индекс). Эти числовые значения представляют слова или символы в числовой форме.
Представление в виде матрицы: Кодированный текст представляется в виде матрицы, где каждый столбец соответствует слову или символу, а строки представляют контекстные окна. Это означает, что каждая строка матрицы представляет собой последовательность слов или символов из исходного текста. Размерность матрицы зависит от размера контекстного окна и размера словаря (количество уникальных слов или символов).
Сверточные слои: Сверточные слои в CNN применяются к матрице, чтобы извлечь важные признаки из текста. Свертка происходит путем сканирования фильтров (ядер свертки) через матрицу. Эти фильтры могут выявлять различные шаблоны и особенности в тексте, такие как последовательности слов или символов. Результатом свертки является новая матрица, называемая картой признаков (feature map).
Пулинг (Pooling): После применения сверточных слоев может выполняться операция пулинга. Пулинг используется для уменьшения размерности карты признаков, уменьшая количество параметров и улучшая обобщающую способность модели. Обычно используется операция максимального пулинга (MaxPooling), которая выделяет наибольшие значения из окна, перемещая его по карте признаков.
Полносвязные слои: После применения сверточных и пулинговых слоев информация передается в полносвязные слои для классификации или регрессии. Полносвязные слои работают с вектором признаков, полученным из карты признаков после операции пулинга.
Преимущество использования CNN для текстовых данных заключается в способности модели извлекать локальные и глобальные признаки из текста, что может улучшить способность модели к анализу и классификации текста. Этот метод также позволяет модели работать с последовательностями разной длины, благодаря использованию окон и пулинга.
Следующий код решает задачу бинарной классификации текстовых отзывов на положительные и отрицательные. Каждый отзыв имеет метку 1 (положительный) или 0 (отрицательный).
В результате выполнения этого кода:
1. Мы создаем модель сверточной нейронной сети (CNN), которая способна анализировать тексты.
2. Загружаем обучающие данные в виде массива текстов `texts` и их меток `labels`.
3. Создаем токенизатор для преобразования текстов в численные последовательности и приводим тексты к числовому представлению.
4. Выравниваем текстовые последовательности до максимальной длины `max_sequence_length`, чтобы их можно было использовать в нейронной сети.
5. Создаем модель CNN, состоящую из слоев Embedding, Conv1D, GlobalMaxPooling1D и Dense.
6. Компилируем модель, используя оптимизатор "adam" и функцию потерь "binary_crossentropy".
7. Обучаем модель на обучающих данных в течение 10 эпох.
8. Оцениваем модель на тестовых данных (4 отдельных отзыва).
Результаты этого кода включают в себя точность модели на тестовых данных, которая измеряет, насколько хорошо модель классифицирует новые отзывы как положительные или отрицательные. Вы увидите значение точности на тестовых данных в консоли после выполнения кода. Точность ближе к 1.0 означает, что модель хорошо обучена и способна правильно классифицировать тексты.
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# Генерируем примеры текстовых данных
texts = ["Это отличный продукт.", "Этот товар ужасен.", "Мне нравится эта книга.", "Не советую этот фильм."]
labels = [1, 0, 1, 0] # 1 – положительный отзыв, 0 – отрицательный отзыв
# Создаем токенизатор и преобразуем тексты в последовательности чисел
tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=1000, oov_token="<OOV>")
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
# Подготавливаем данные для CNN
max_sequence_length = max([len(seq) for seq in sequences])
padded_sequences = tf.keras.preprocessing.sequence.pad_sequences(sequences, maxlen=max_sequence_length)
# Преобразуем метки в массив numpy
labels = np.array(labels)
# Создаем модель CNN
model = tf.keras.Sequential([
tf.keras.layers.Embedding(input_dim=1000, output_dim=16, input_length=max_sequence_length),
tf.keras.layers.Conv1D(128, 3, activation='relu'), # Уменьшили размер ядра до 3
tf.keras.layers.GlobalMaxPooling1D(),
tf.keras.layers.Dense(1, activation='sigmoid')
])
# Компилируем модель
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Обучаем модель
history = model.fit(padded_sequences, labels, epochs=10, verbose=1)
# Оцениваем модель на тестовых данных
test_texts = ["Это лучшая книга.", "Не стоит тратить деньги.", "Мне понравился фильм.", "Ужасное качество товара."]
test_labels = [1, 0, 1, 0] # Метки для тестовых данных
test_sequences = tokenizer.texts_to_sequences(test_texts)
padded_test_sequences = tf.keras.preprocessing.sequence.pad_sequences(test_sequences, maxlen=max_sequence_length)
test_labels = np.array(test_labels)
test_loss, test_accuracy = model.evaluate(padded_test_sequences, test_labels)
print(f"Точность на тестовых данных: {test_accuracy:.4f}")
# Визуализация результатов
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['accuracy'], label='Точность на обучении')
plt.xlabel('Эпохи')
plt.ylabel('Точность')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['loss'], label='Потери на обучении')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
На графиках, полученных после выполнения предоставленного кода, вы увидите результаты обучения и оценку модели. Давайте разберем подробнее:
1. График точности на обучении (Точность на обучении): Этот график показывает, как точность модели изменяется в течение эпох обучения. Точность на обучении измеряет, как хорошо модель предсказывает данные обучения. Вы ожидаете, что точность будет увеличиваться с каждой эпохой. Если точность растет, это может указывать на то, что модель успешно изучает данные.
2. График потерь на обучении (Потери на обучении): Этот график отражает, как уменьшается потеря модели на обучении с течением эпох. Потери представляют собой меру того, насколько сильно предсказания модели отличаются от фактических меток. Цель – минимизировать потери. Уменьшение потерь также указывает на успешное обучение модели.
На практике хорошо обученная модель будет иметь следующие характеристики:
– Точность на обучении растет и стабилизируется на определенном уровне.
– Потери на обучении уменьшаются и стабилизируются на низком уровне.
Если точность на тестовых данных также высока, это означает, что модель успешно обобщает знания на новые, ранее не виденные данные.


