



Александр Юрьевич Чесалов
Глоссариум по искусственному интеллекту и информационным технологиям
Исследования будущего (Futures studies) – это изучение постулирования возможных, вероятных и предпочтительных вариантов будущего, а также мировоззрений и мифов, лежащих в их основе.
Исходная отметка (Бенчмарк) ИИ (AI benchmark) – это эталонный тест ИИ для оценки возможностей, эффективности, производительности и для сравнения ИНС, моделей машинного обучения (МО), архитектур и алгоритмов при решении различных задач ИИ создаются и стандартизируется специальные эталонные тесты, исходные отметки. Например, Benchmarking Graph Neural Networks – бенчмаркинг (эталонное тестирование) графовых нейронных сетей (ГНС, GNN) – обычно включает инсталляцию конкретного бенчмарка, загрузку исходных датасетов, проведение тестирования ИНС, добавление нового датасета и повторение итераций.
«К»
Капсульная нейронная сеть (Capsule neural network) – это архитектура искусственных нейронных сетей, которая предназначена для распознавания изображений. Главными преимуществами данной архитектуры является существенное снижение размеров необходимой для обучения выборки, а также повышение точности распознавания и устойчивость к атакам типа «белый ящик». Ключевым нововведением капсульных нейросетей является наличие так называемых капсул – элементов, являющихся промежуточными единицами между нейронами и слоями, которые представляют собой группы виртуальных нейронов, отслеживающих не только отдельные детали изображения, но и их расположение друг относительно друга. Данная архитектура была задумана Джеффри Хинтоном в 1979 году, сформулирована в 2011 году и опубликована в двух статьях в октябре 2017 года57,58.
Квантование (Quantization) – это разбиение диапазона отсчётных значений сигнала на конечное число уровней и округления этих значений до одного из двух ближайших к ним уровней.
Квантовые технологии (Quantum technologies) – это технологии создания вычислительных систем, основанные на новых принципах (квантовых эффектах), позволяющие радикально изменить способы передачи и обработки больших массивов данных.
Киберфизические системы (Cyber-physical systems) – это интеллектуальные сетевые системы со встроенными датчиками, процессорами и приводами, которые предназначены для взаимодействия с физической окружающей средой и поддержки работы компьютерных информационных систем в режиме реального времени; облачные вычисления – информационно-технологическая модель обеспечения повсеместного и удобного доступа с использованием информационно-телекоммуникационной сети «Интернет» к общему набору конфигурируемых вычислительных ресурсов («облаку»), устройствам хранения данных, приложениям и сервисам, которые могут быть оперативно предоставлены и освобождены от нагрузки с минимальными эксплуатационными затратами или практически без участия провайдера.
Классификация (Classification) – это алгоритмы, которые позволяют машинам назначать категорию точке данных на основе данных обучения.
Кластеризация (Clustering) – это задача по организации данных в группы на основе определенных свойств. После того, как все примеры сгруппированы, человек может дополнительно придать значение каждому кластеру. Существует множество алгоритмов кластеризации. Например, алгоритм k-средних группирует примеры на основе их близости к центроиду. В качестве другого примера можно привести алгоритм кластеризации, основанный на расстоянии примера от центральной точки59.
Кластеризация временных данных (Temporal data clustering) – это разделение неразмеченного набора временных данных на группы или кластеры, где все последовательности, сгруппированные в одном кластере, должны быть согласованными или однородными. Хотя для кластеризации различных типов временных данных были разработаны различные алгоритмы, все они пытаются модифицировать существующие алгоритмы кластеризации для обработки временной информации60.
Кластерный анализ (Cluster analysis) – это тип обучения без учителя, используемый для исследовательского анализа данных для поиска скрытых закономерностей или группировки в данных; кластеры моделируются с мерой сходства, определяемой такими метриками, как евклидово или вероятностное расстояние.
Когнитивистика, когнитивная наука (Cognitive science) – это междисциплинарное научное направление, объединяющее теорию познания, когнитивную психологию, нейрофизиологию, когнитивную лингвистику, невербальную коммуникацию и теорию искусственного интеллекта61.
Когнитивная архитектура (Cognitive architecture) – это гипотеза о фиксированных структурах, обеспечивающих разум, будь то в естественных или искусственных системах, и о том, как они работают вместе – в сочетании со знаниями и навыками, воплощенными в архитектуре. Также, архитектуры, реализованные интеллектуальными агентами, называются когнитивными архитектурами.
Когнитивные вычисления (Cognitive computing) – это самообучающиеся системы, которые используют модели машинного обучения для имитации работы мозга. В конечном итоге эта технология будет способствовать созданию автоматизированных ИТ-моделей, способных решать проблемы без помощи человека62.
Код (Code) – это взаимно однозначное отображение конечного упорядоченного множества символов, принадлежащих некоторому конечному алфавиту.
Коммодитизация (Commoditization) – это процесс превращения продукта из элитного в общедоступный (сравнительно дешёвый товар массового потребления)63.
Компания DeepMind (DeepMind) – это британская компания по искусственному интеллекту, основанная в сентябре 2010 года, в настоящее время принадлежит Alphabet Inc. Компания базируется в Лондоне, а исследовательские центры находятся в Канаде, Франции и США. Приобретенная Google в 2014 году, компания создала нейронную сеть, которая учится играть в видеоигры так же, как люди, а также нейронную машину Тьюринга или нейронную сеть, которая может иметь доступ к внешней памяти. как обычная машина Тьюринга, в результате чего появился компьютер, имитирующий кратковременную память человеческого мозга. Компания попала в заголовки газет в 2016 году после того, как ее программа AlphaGo обыграла профессионального игрока в «го» Ли Седола, чемпиона мира, в матче из пяти игр, о котором был снят документальный фильм. Более общая программа, AlphaZero, обыграла самые мощные программы, играющие в «го», шахматы и сёги (японские шахматы) после нескольких дней игры против самой себя с использованием обучения с подкреплением.
Компилятор (Compiler) – это программа, переводящая текст, написанный на языке программирования, в набор машинных кодов. Компиляторы фреймворков ИИ собирают вычислительные данные фреймворков и старается оптимизировать код каждого из них, независимо от аппаратных средств акселератора. Компилятор содержит программы и блоки, при помощи которых фреймворк выполняет несколько задач. Распределитель ресурсов памяти компьютера, например, выделяет мощности индивидуально для каждого акселератора.
Комплект средств разработки ПО (Software Development Kit, SDK) – это комплект средств разработки, который позволяет специалистам по программному обеспечению создавать приложения для определенного пакета программ, программного обеспечения базовых средств раз работки, аппаратной платформы, компьютерной системы, игровых консолей, операционных систем и прочих платформ. SDK с использованием ИИ свободно распространяются компаниями разработчиками ПО, таким как NVIDIA, ABBYY, HUAWEI и т. д. в зависимости от сферы применения ИИ.
Комплекты для создания и обучения искусственного интеллекта (AI Building and Training Kits) – это приложения и комплекты для разработки программного обеспечения (SDK), которые абстрагируют платформы, фреймворки, аналитические библиотеки и устройства для анализа данных, позволяя разработчикам программного обеспечения включать ИИ в новые или существующие приложения.
Композитный искусственный интеллект (Composite AI) – это комбинированное применение различных методов ИИ для повышения эффективности обучения, расширения уровня представления знаний и, в конечном итоге, для более эффективного решения более широкого круга бизнес-задач.
Компьютерное зрение (Computer vision, CV) – это научная дисциплина, область техники и направление искусственного интеллекта (ИИ), занимающееся компьютерной обработкой, распознаванием, анализом и классификацией динамических изображений реальной действительности. Широко применяется в системах видеонаблюдения, в робототехнике и в современной промышленности для повышения качества продукции и эффективности производства, выполнения требований законодательства и др. В компьютерном зрении выделяют следующие направления: распознавание лиц (face recognition), распознавание образов (image recognition), дополненная реальность (augmented reality, AR) и оптическое распознавание символов (optical character recognition, OCR).
Компьютерное моделирование (Computer simulation) – это процесс математического моделирования, выполняемого на компьютере, который предназначен для прогнозирования поведения или результатов реальной или физической системы. Надежность некоторых математических моделей можно определить путем сравнения их результатов с реальными результатами, которые они стремятся предсказать. Компьютерное моделирование стало полезным инструментом для математического моделирования многих природных систем в физике (вычислительной физике), астрофизике, климатологии, химии, биологии и производстве, а также человеческих систем в экономике, психологии, социальных науках, здравоохранении и технике64.
Компьютерный инжиниринг (Computer engineering) – это технологии цифрового моделирования и проектирования объектов и производственных процессов на всем протяжении жизненного цикла.
Компьютерный инцидент (Computer incident) – это факт нарушения и (или) прекращения функционирования объекта критической информационной инфраструктуры, сети электросвязи, используемой для организации взаимодействия таких объектов, и (или) нарушения безопасности обрабатываемой таким объектом информации, в том числе, произошедший в результате компьютерной атаки.
Контролируемое обучение (Supervised learning) – это тип машинного обучения, при котором выходные наборы данных обучают машину генерировать желаемые алгоритмы, как учитель, контролирующий ученика; используется чаще, чем обучение без учителя.
Конфиденциальность информации (Confidentiality of information) – это обязательное для выполнения лицом, получившим доступ к определенной информации, требование не передавать такую информацию третьим лицам без согласия ее обладателя.
Корреляционный анализ (Correlation analysis) – это метод обработки статистических данных, с помощью которого измеряется теснота связи между двумя или более переменными. Таким образом, он определяет существует ли связь между явлениями и насколько сильная связь между этими явлениями.
Корреляция (Correlation) – это статистическая взаимосвязь двух или более случайных величин.
Креативные вычисления (Computational creativity) – это междисциплинарное направление с характеристиками методов разработки, оценки, моделирования, философии, теоретики, психологии и искусства. Креативные вычисления относятся к мета-технологии для объединения знаний в области вычислений и других дисциплин65.
Криогенная заморозка (крионика, криоконсервация человека) – это технология сохранения в состоянии глубокого охлаждения (при помощи жидкого азота) головы или тела человека после его смерти с намерением оживить их в будущем.
Критическая информационная инфраструктура (Critical information infrastructure) – это объекты критической информационной инфраструктуры, а также сети электросвязи, используемые для организации взаимодействия таких объектов.
Критическая информационная инфраструктура Российской Федерации (Critical information infrastructure of the Russian Federation) – это совокупность объектов критической информационной инфраструктуры, а также сетей электросвязи, используемых для организации взаимодействия объектов критической информационной инфраструктуры между собой.
«Л»
Логистическая регрессия (logit model, Logistic regression) – это статистическая модель, используемая для предсказания вероятности возникновения интересующего нас события с помощью логистической функции66.
Логическое программирование (Logic programming) – это парадигма программирования, которая основывается на формальной логике. Любая программа, написанная на логическом языке программирования, представляет собой набор предложений в логической форме, выражающий факты и правила о некоторой проблемной области.
Логическое программирование (Logic programming) – это тип парадигмы программирования, в которой вычисления выполняются на основе хранилища знаний фактов и правил; LISP и Prolog – два языка логического программирования, используемые для программирования AI.
Локальное устройство (Local device) – это устройства, входящие в сеть, которая покрывает относительно небольшую территорию или небольшую группу зданий.
Локальный сервер (Local server) – это хостинг, работающий при помощи программ, которые осуществляют его эмуляцию на личном компьютере.
«М»
Маркер (Token) в языковой модели – это элементарная единица, на которой модель обучается и делает прогнозы.
Марковская модель (Markov model) — это статистическая модель, имитирующая работу процесса, похожего на марковский процесс с неизвестными параметрами, задачей которой является определение неизвестных параметров на основе наблюдаемых данных.
Марковский процесс (Markov process) – это случайный процесс, эволюция которого после любого заданного значения временного параметра t не зависит от эволюции, предшествовавшей t, при фиксированных параметрах процесса67.
Массив данных (датасет) – это идентифицируемая совокупность данных, к которой можно получить доступ или скачать в одном или нескольких форматах68.
Масштабируемость (Scalability) – это способность системы, сети или процесса справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов (обычно аппаратных).
Машина опорных векторов (Support Vector Machine) – это популярная модель обучения с учителем, разработанная Владимиром Вапником и используемая как для классификации данных, так и для регрессии. Тем не менее, он обычно используется для задач классификации, построения гиперплоскости, где расстояние между двумя классами точек данных максимально. Эта гиперплоскость известна как граница решения, разделяющая классы точек данных по обе стороны от плоскости.
Машина Тьюринга (Turing machine) – это математическая модель вычислений, определяющая абстрактную машину, которая манипулирует символами на полосе ленты в соответствии с таблицей правил. Несмотря на простоту модели, для любого компьютерного алгоритма можно построить машину Тьюринга, способную имитировать логику этого алгоритма.
Машинное восприятие (Machine perception) – это способность системы получать и интерпретировать данные из внешнего мира аналогично тому, как люди используют наши органы чувств. Обычно это делается с подключенным оборудованием, хотя можно использовать и программное обеспечение.
Машинное зрение (Machine Vision) – это применение общего набора методов, позволяющих компьютерам видеть, для промышленности и производства.
Машинное обучение (Machine Learning) – это область исследования, которая дает компьютерам возможность учиться без явного программирования». Также под машинным обучением понимают технологии автоматического обучения алгоритмов искусственного интеллекта распознаванию и классификации на тестовых выборках объектов для повышения качества распознавания, обработки и анализа данных, прогнозирования. Также машинное обучение определяют, как одно из направлений (подмножеств) искусственного интеллекта, благодаря которому воплощается ключевое свойство интеллектуальных компьютерных систем – самообучение на основе анализа и обработки больших разнородных данных. Чем больше объем информации и ее разнообразие, тем проще искусственному интеллекту найти закономерности и тем точнее будет получаемый результат69,70,71,72,73.
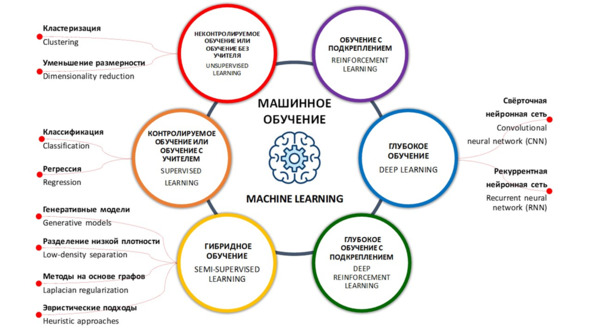
Машинное обучение Microsoft Azure (платформа автоматизации искусственного интеллекта) (Microsoft Azure Machine Learning) – это функция, которая предлагает расширенную облачную аналитику, предназначенную для упрощения машинного обучения для бизнеса. Бизнес-пользователи могут моделировать по-своему, используя лучшие в своем классе алгоритмы из пакетов Xbox, Bing, R или Python или добавляя собственный код R или Python. Затем готовую модель можно за считанные минуты развернуть в виде веб-службы, которая может подключаться к любым данным в любом месте. Его также можно опубликовать для сообщества в галерее продуктов или на рынке машинного обучения. В Machine Learning Marketplace доступны интерфейсы прикладного программирования (API) и готовые сервисы. Также, – это способность машин автоматизировать процесс обучения. Входными данными этого процесса обучения являются данные, а выходными данными – модель. Благодаря машинному обучению система может выполнять функцию обучения с данными, которые она принимает, и, таким образом, она становится все лучше в указанной функции.
Машинный разум (Machine intelligence) – это общий термин, охватывающий машинное обучение, глубокое обучение и классические алгоритмы обучения.
Машины опорных векторов или сети опорных векторов (Support-vector machines, Support-vector networks) – это контролируемые модели обучения с соответствующими алгоритмами обучения, которые анализируют данные для классификации и регрессионного анализа. Разработаны в AT&T Bell Laboratories Владимиром Вапником с коллегами в 1992 году. Машины опорных векторов являются одним из самых надежных методов прогнозирования, основанным на статистическом обучении или теории Вапника – Червоненкиса, предложенной Вапником (1982, 1995) и Червоненкисом (1974). Учитывая набор обучающих примеров, каждый из которых помечен как принадлежащий к одной из двух категорий, алгоритм обучения машины опорных векторов строит модель, которая относит новые примеры к той или иной категории, превращая ее в невероятностный двоичный линейный классификатор (хотя методы такие как масштабирование Платта, существуют для использования машин опорных векторов в вероятностной классификации). Машины опорных векторов сопоставляют обучающие примеры с точками в пространстве, чтобы максимизировать ширину разрыва между двумя категориями. Затем новые примеры сопоставляются с тем же пространством, и их принадлежность к категории определяется в зависимости от того, на какую сторону разрыва они попадают. В дополнение к выполнению линейной классификации SVM могут эффективно выполнять нелинейную классификацию, используя так называемый трюк ядра, неявно отображая свои входные данные в многомерные пространства признаков. Когда данные не размечены, обучение с учителем невозможно, и требуется подход к обучению без учителя, который пытается найти естественную кластеризацию данных в группы, а затем сопоставляет новые данные с этими сформированными группами. Алгоритм кластеризации опорных векторов, созданный Хавой Зигельманн и Владимиром Вапником, применяет статистику опорных векторов, разработанную в алгоритме машин опорных векторов, для категоризации неразмеченных данных74,75.
Мероприятия по информатизации (Informatization activities) – это предусмотренные мероприятия программ цифровой трансформации государственных органов, направленные на создание, развитие, эксплуатацию или использование информационно-коммуникационных технологий, а также на вывод из эксплуатации информационных систем и компонентов информационно-телекоммуникационной инфраструктуры.
Мероприятия программы цифровой трансформации, осуществляемые государственным органом (Measures of the digital transformation program carried out by a state body) – это объединенная единой целью совокупность действий государственного органа, в том числе мероприятий по информатизации, направленных на выполнение задач по оптимизации административных процессов предоставления государственных услуг и (или) исполнения государственных функций, созданию, развитию, вводу в эксплуатацию, эксплуатации или выводу из эксплуатации информационных систем или компонентов информационно-коммуникационных технологий, нормативно-правовому обеспечению указанных процессов или иных задач, решаемых в рамках цифровой трансформации.
Метод оперирования большими данными – это совокупность теоретических принципов и/или практических приемов для оперирования большими данными76.
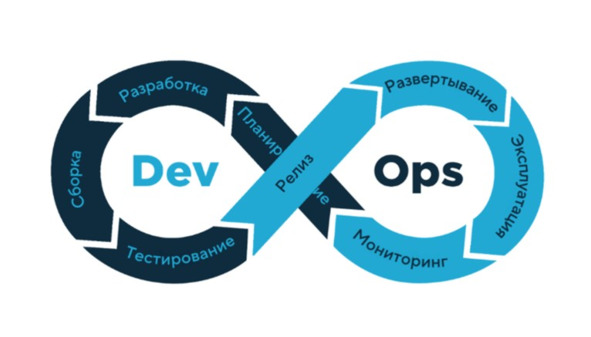
Методология разработки и операции (DevOps, development & operations) – это набор методик, инструментов и философия культуры, которые позволяют автоматизировать и интегрировать между собой процессы команд разработки ПО и ИТ-команд. Особое внимание в DevOps уделяется расширению возможностей команд, их взаимодействию и сотрудничеству, а также автоматизации технологий. Под термином DevOps также понимают особый подход к организации команд разработки. Его суть в том, что разработчики, тестировщики и администраторы работают в едином потоке – не отвечают каждые за свой этап, а вместе работают над выходом продукта и стараются автоматизировать задачи своих отделов, чтобы код переходил между этапами без задержек. В DevOps ответственность за результат распределяется между всей командой77,78.
Методы эвристического поиска (Heuristic search techniques) – это методы, которые сужают поиск оптимальных решений проблемы за счет исключения неверных вариантов.
Механизм внимания (Attention mechanism) – это одно из ключевых нововведений в области нейронного машинного перевода. Внимание позволило моделям нейронного машинного перевода превзойти классические системы машинного перевода, основанные на переводе фраз. Основным узким местом в sequence-to-sequence обучении является то, что все содержимое исходной последовательности требуется сжать в вектор фиксированного размера. Механизм внимания облегчает эту задачу, так как позволяет декодеру оглядываться на скрытые состояния исходной последовательности, которые затем в виде средневзвешенного значения предоставляются в качестве дополнительных входных данных в декодер.
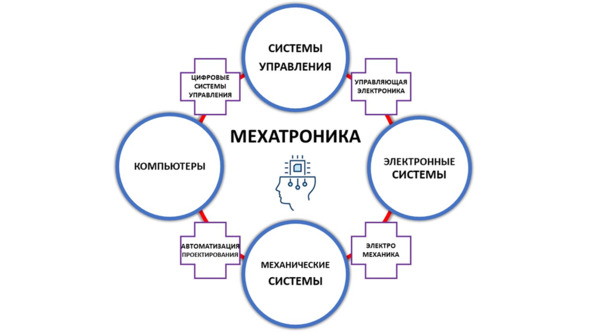
Мехатроника (Mechatronics) – это научно-техническая дисциплина, посвящённая созданию и эксплуатации электроприводов с программным управлением, которые обеспечивают высокоточные движения. Мехатронные узлы, блоки и системы строятся по технологиям, интегрирующим механику, электротехнику, силовую электронику, микропроцессорную технику, программное управление. Эти компактные модули применяются в самых разных системах, которые используют многие отрасли: авто- и авиастроение; космическая техника; производство спортивного оборудования; медтехника; бытовая техника; робототехника79.
Минимизация структурных рисков (Structural risk minimization, SRM) – это индуктивный принцип использования в машинном обучении. Обычно в машинном обучении обобщенная модель должна быть выбрана из конечного набора данных, что приводит к проблеме переобучения – модель становится слишком строго адаптированной к особенностям обучающего набора и плохо обобщается для новых данных. Принцип SRM решает эту проблему, уравновешивая сложность модели с ее успехом в подборе обучающих данных. Этот принцип был впервые изложен в статье 1974 года Владимира Вапника и Алексея Червоненкиса80.
Многозадачное обучение (Multitask learning) – это общий подход, при котором модели обучаются выполнению различных задач на одних и тех же параметрах. В нейронных сетях этого можно легко добиться, связав веса разных слоев. Идея многозадачного обучения была впервые предложена Ричем Каруаной в 1993 году и применялась для прогнозирования пневмонии, а также для создания системы следования дороге на беспилотных устройствах (Каруана, 1998). Фактически при многозадачном обучении модель стимулируют к созданию внутри себя такого представления данных, которые позволяет выполнить сразу много задач. Это особенно полезно для обучения общим низкоуровневым представлениям, на базе которых потом происходит «концентрация внимания» модели или в условиях ограниченного количества обучающих данных. Многозадачное обучение нейросетей для обработки естественного языка было впервые применено в 2008 году Коллобером и Уэстоном (Collobert & Weston, 2008).
Мобильное здравоохранение (Mobile healthcare, mHealth) – это ряд мобильных технологий, систем, сервисов и приложений, установленных на мобильных устройствах и использующихся в медицинских целях и для обеспечения здорового образа жизни человека и мотивации людей к здоровому образу жизни и формированию новой «цифровой» культуры здоровья.
Модель от последовательности к последовательности (Sequence-to-sequence model, seq2seq). Самая популярная задача на последовательность – это перевод: обычно с одного естественного языка на другой. За последние пару лет коммерческие системы стали на удивление хороши в машинном переводе – взгляните, например, на Google Translate, Yandex Translate, DeepL Translator, Bing Microsoft Translator. Сегодня мы узнаем об основной части этих систем81.
Модель убеждений, желаний и намерений (Belief-desire-intention software model) – это модель программирования интеллектуальных агентов. Образно модель описывает убеждения, желания и намерения каждого агента, однако непосредственно применительно к конкретной задаче агентного программирования. По сути, модель предоставляет механизм позволяющий разделить процесс выбора агентом плана (из набора планов или внешнего источника генерации планов) от процесса исполнения текущего плана, выбранного ранее. Как следствие, агенты, повинующиеся данной модели способны уравновешивать время, затрачиваемое ими на выбор и отсеивание будущих планов со временем исполнения выбранных планов. Процесс непосредственного синтеза планов (планирование) в модели не описывается и остаётся на откуп программного дизайнера или программиста82.
Модули векторной обработки (Intelligent Engines) – это поле выполнения операций умножения с плавающей запятой с минимальными задержками (DSP Engines) и специализированное поле/модуль AI Engines c высокой пропускной способностью, а также минимальными задержкам на выполнение операций и оптимальным уровнем энергопотребления, предназначенное для решения задач в области реализации искусственного интеллекта (AI inference) и цифровой обработки сигналов.
Мозговая технология (также самообучающаяся система ноу-хау) (Brain technology) – это технология, в которой используются последние открытия в области неврологии. Термин был впервые введен Лабораторией искусственного интеллекта в Цюрихе, Швейцария, в контексте проекта ROBOY. Brain Technology может использоваться в роботах, системах управления ноу-хау и любых других приложениях с возможностями самообучения. В частности, приложения Brain Technology позволяют визуализировать базовую архитектуру обучения, которую часто называют «картами ноу-хау».
Мозгоподобные вычисления (Brain-inspired computing) – это вычисления на мозгоподобных структурах, вычисления, использующие принципы работы мозга.
Мозгоподобные вычисления (Brain-inspired computing) – это вычисления использующие принципы работы мозга.
Мультиопыт (Multiexperience) – это процесс замены людей, понимающих технологии, на технологии, понимающие людей.
Мульти-опыт (Multi-experience) – это часть долгосрочного перехода от индивидуальных компьютеров, которые мы используем сегодня, к многопользовательским, мультисенсорным и многолокационным системам.




